

GraphAgent团队 投稿
量子位 | 公众号 QbitAI
论文能不能中?可以用AI提前预测~
港大黄超教授团队提出多智能体自动化框架GraphAgent,能自动构建和解析知识图谱中的复杂语义网络,应对各类预测和生成任务。

GraphAgent通过图生成、任务规划和任务执行三大核心智能体的协同运作,融合大语言模型与图语言模型的优势,成功连接了结构化图数据与非结构化文本数据,在文本总结与关系建模方面实现了明显提升。
实验中,在预测性任务(如节点分类)和生成性任务(如文本生成)上,GraphAgent均取得突出成果,仅以8B参数规模便达到了与GPT-4、Gemini等大规模封闭源模型相当的性能水平。
特别在零样本学习和跨域泛化等场景中,GraphAgent展现出显著优势。
有意思的是,团队将GraphAgent应用到了学术论文评审场景。
在实际投稿流程中,作者往往需要根据评审意见准备Rebuttal回应,而GraphAgent仅基于论文评审意见(Reviews)就能帮助作者更好地评估论文的录取可能。
GraphAgent长啥样?
现实世界的数据呈现双重特性:一方面是结构化的图连接数据,另一方面是非结构化的文本与视觉信息。
这些数据中蕴含的关系网络也分为两类:显式的连接关系(如社交网络互动),以及隐式的语义依赖(常见于知识图谱)。
这种复杂性带来了三大核心挑战:
-
异构数据融合:系统需要整合多种形式的信息。以学术网络为例,论文间的引用构成了图结构关系,而标题、摘要等文本则承载着丰富的语义信息。有效整合这些异构信息可支持知识总结、科学问答等应用。
-
多层次关系理解:实际场景中往往存在多维度的关联。例如电商平台中,用户-商品交互构成行为图谱,产品评论则形成语义网络。深入理解这些多层关系有助于提升用户-商品交互预测的准确性。
-
任务多元化:应用场景要求系统具备广泛的处理能力。预测类任务包括节点分类、链接推断等图分析;生成类任务涉及图增强文本生成、知识图谱问答等。这需要系统能够灵活适应不同任务特点,并充分利用数据中的结构化与语义信息。
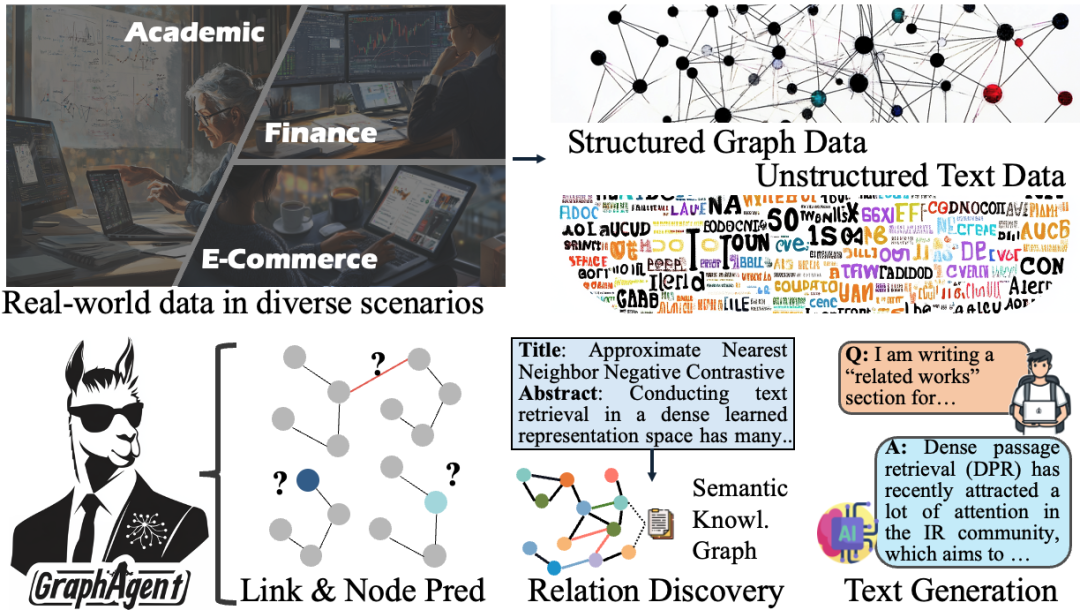
为应对上述挑战,研究团队提出多智能体自动化框架GraphAgent。
该框架通过三大核心智能体的协同配合,实现了图结构与语义信息的深度融合,可同时支持预测型(图分析、节点分类)和生成型(文本创作)等多样化任务。
其核心架构包括:
-
图生成智能体(Graph Generator Agent)
-
任务规划智能体(Task Planning Agent)
-
任务执行智能体(Task Execution Agent)
三大智能体通过协同机制紧密配合,融合大语言模型与图语言模型的优势,有效挖掘数据中的关系网络与语义依赖。
下面详细介绍各个智能体的核心功能:

图生成智能体
图生成智能体负责构建语义知识图谱(Semantic Knowledge Graph, SKG),通过创新的双阶段迭代机制实现深层语义信息的提取与整合。
该智能体的工作流程分为两个核心阶段:
1)知识节点提取阶段
该阶段采用自适应的分层策略,从非结构化文本中识别多维度的知识实体:
-
通过定制化的系统提示,调用大语言模型(LLM)处理输入文本
-
运用迭代式识别技术,同时捕获宏观领域概念(如”Machine Learning”)和微观技术细节(如”Self-Supervised Learning”)
-
基于多轮迭代构建层次化知识结构,确保知识体系的完整性与连贯性
2)知识描述增强阶段
这一阶段着重提升知识表示的丰富度与准确性:
-
为每个识别的节点生成详实的语义描述
-
整合相关上下文信息,构建完整的知识联系
-
采用动态迭代更新机制:i) 将每轮描述作为下轮优化的基础;ii) 持续深化和拓展知识内容;iii) 通过多轮迭代融合,最终形成语义完备的知识图谱
任务规划智能体
任务规划智能体作为框架的决策核心,通过精密的三阶段处理机制完成复杂任务的规划与分解。
其工作流程包括:
1)意图识别与任务制定
该阶段专注于准确理解用户需求并确定处理策略:
-
深度解析用户查询,提取核心意图
-
将任务分类为三大类型:预定义图预测(Predictive_predefined),处理已知结构的图分析;开放图预测(Predictive_wild),应对未知结构的图推理;自由生成任务(Open_generation),执行灵活的创作需求。
2)图结构标准化处理
此阶段实现不同类型图数据的统一表达:
-
运用专业图构建工具(GBW_Tool)进行结构转换
-
同步处理显式关系图(G_exp)与语义知识图(G_skg)
-
建立标准化的异构图表示体系,确保处理一致性
3)图文特征融合
这一阶段着重实现信息的深度整合:
-
结合预训练文本编码器与图神经网络,构建双层编码体系
-
生成文本语义与图结构的联合表示
-
为下游任务提供丰富的特征支持,奠定执行基础
图动作智能体
图动作智能体是框架的核心执行单元,通过创新的三维处理架构,实现了任务的精准执行与性能优化。
其工作机制包括:
1)智能化任务处理机制
针对不同类型任务采用差异化处理策略:
-
预测类任务:设计专属系统提示,引导模型进行精准预测
-
生成类任务:融合语义知识图谱,提升文本生成的质量与相关性
-
自适应优化:根据任务特点动态调整处理流程,确保执行效率
2)深度图指令对齐技术
创新性地实现了多层次的模态对齐:
-
同类型图结构对齐:增强模型对特定图模式的理解能力
-
跨类型知识融合:提升处理异构图关系的准确性
-
双向增强机制:显著提升模型在多样化场景下的泛化表现
3)渐进式学习策略
采用先进的课程学习方法:
-
基于难度梯度的任务编排:从基础到进阶的平滑过渡
-
精细化的训练序列设计:确保知识积累的连续性
-
全方位性能调优:在各类任务中保持稳定的高水平表现
实验
数据集设置
实验评估采用了六个各具特色的基准数据集,涵盖了不同场景和任务类型。
如Table 1所示,这些精心选择的数据集在规模、结构和应用领域等方面展现出显著差异,为全面验证框架性能提供了理想的测试基础。
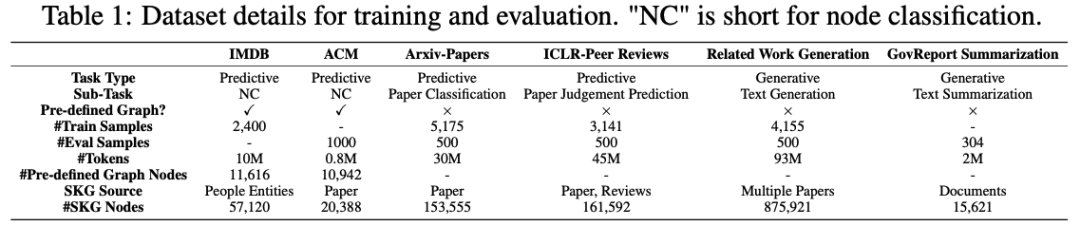
为全面评估GraphAgent的通用性能,本研究精选了六个具有代表性的基准数据集开展系统实验。这些数据集按照任务特征可划分为三大类:
结构化图数据集: 采用了两个经典的节点分类数据集IMDB和ACM。其中IMDB数据集包含11,616个节点,ACM数据集涵盖10,942个节点,这两个数据集都具有清晰的图结构特征,为评估模型在结构化数据处理方面的能力提供了可靠基准。
文本处理数据集: 选择了Arxiv-Papers和ICLR-Peer Reviews两个具有代表性的数据集。Arxiv-Papers构建了包含153,555个SKG节点的语义知识图,用于评估文档分类性能;ICLR-Peer Reviews则包含161,592个SKG节点,专门用于论文录用预测任务,这些数据集体现了模型处理复杂文本及语义关系的能力。
智能生成数据集: 引入了Related Work Generation和GovReport总结两个具有挑战性的数据集。Related Work Generation基于多篇论文构建,包含875,921个SKG节点,用于验证模型的相关工作生成能力;GovReport包含15,621个SKG节点,针对长文档摘要生成任务,这两个数据集都对模型的生成能力提出了较高要求。
实验效果分析
结构化数据预测性能分析
为深入评估GraphAgent在结构化图任务中的零样本学习能力,研究团队设计了一组的对比实验。
实验采用IMDB数据集进行模型训练,分别在1-shot和40-shot两种低资源场景下验证模型性能,并在ACM数据集的1,000个未见节点上开展迁移测试,以评估模型的泛化能力。
实验结果表明:GraphAgent在所有关键指标上都显著优于当前最先进的图语言模型HiGPT,平均性能提升超过28%。模型在40-shot设置下取得了显著性能提升:Micro-F1和Macro-F1均达74.98%(提升48.5%/63.5%),AUC达80.90%(提升27.2%)。
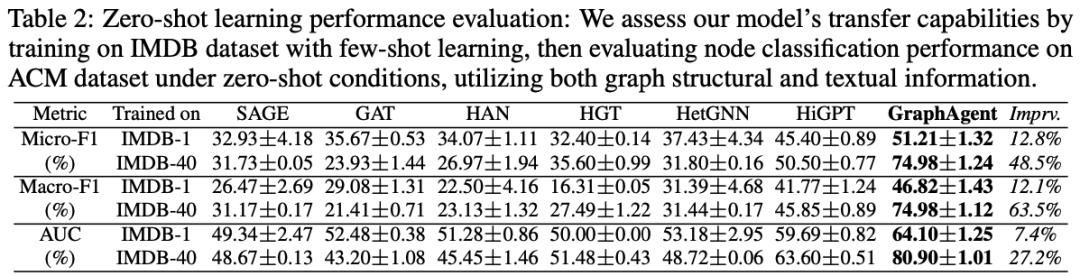
GraphAgent的卓越性能主要源于三项核心技术创新:
首先,智能图生成机制通过自动构建语义知识图谱(SKG)为模型注入丰富的补充信息,显著增强了复杂语义关系的理解能力;
其次,精确的任务规划机制使模型能够准确理解和分解用户意图,并为不同应用场景制定最优执行策略;
最后,创新性的双重优化策略结合了图文对齐和任务微调机制,不仅提升了模型的基础性能,还增强了迁移学习能力,使模型即使在1-shot等低资源场景下仍能保持稳定的高性能表现。
语义理解能力分析
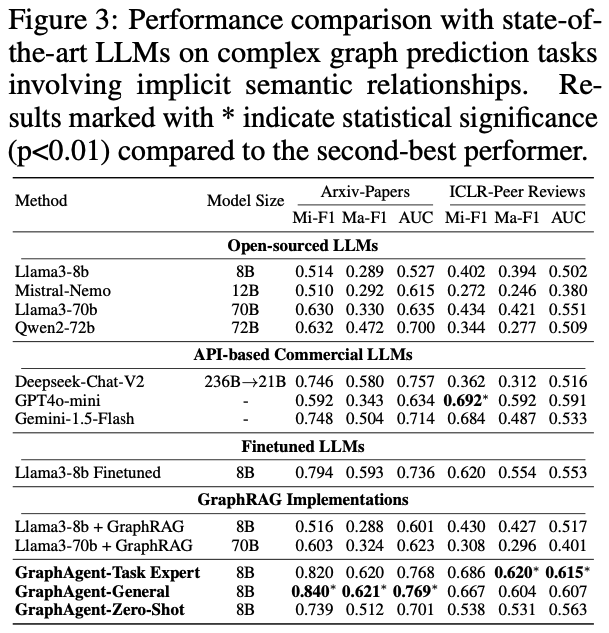
为深入评估GraphAgent在复杂语义关系处理方面的性能,研究团队基于两个典型数据集开展了系统实验:利用Arxiv-Papers数据集进行论文分类验证,并通过ICLR-Peer Reviews数据集测试论文录用预测能力。
通过严格的实验评估,GraphAgent在处理隐式语义依赖关系时展现出如下突出优势:
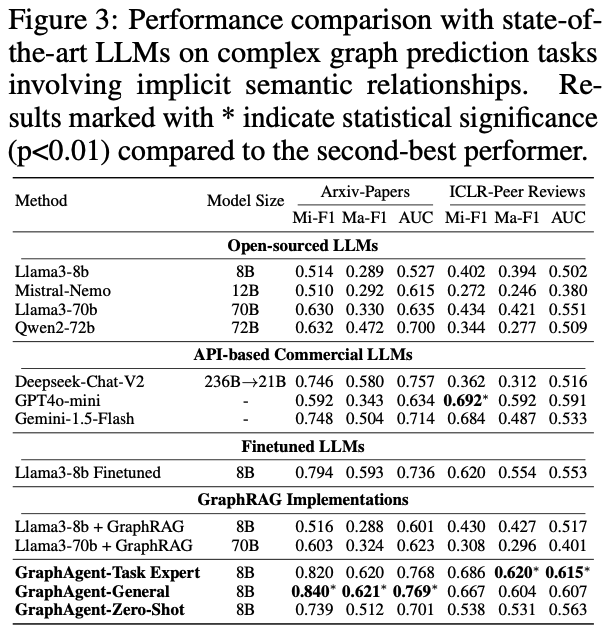
实验结果凸显了GraphAgent的三大核心优势:
在参数规模优化方面,仅有8B参数的GraphAgent凭借其独特的语义知识图谱架构,成功实现了对复杂语义依赖关系的精准把握,通过多层次语义信息的局部与全局整合,在各项评估指标上显著超越了Llama3-70b和Qwen2-72b等大规模模型,平均性能提升达31.9%。
在泛化能力表现上,GraphAgent展现出卓越的跨任务学习潜力。其多任务版本GraphAgent-General在Arxiv-Papers数据集的表现甚至优于专门优化的单任务版本。
特别值得注意的是,8B规模的GraphAgent在零样本场景下也能达到Deepseek-Chat-V2等大型闭源模型的性能水平。
在架构效率方面,GraphAgent通过创新性地整合语义知识图谱和结构化知识表示,相比传统的监督微调方法和GraphRAG系统,不仅显著提升了模型性能,还有效降低了输入开销,同时成功缓解了大语言模型常见的幻觉问题。
文本生成任务
GraphAgent在图增强文本生成任务中展现出卓越表现,通过性能评估、模型对比和架构分析三个维度的系统实验,充分验证了其突出优势。
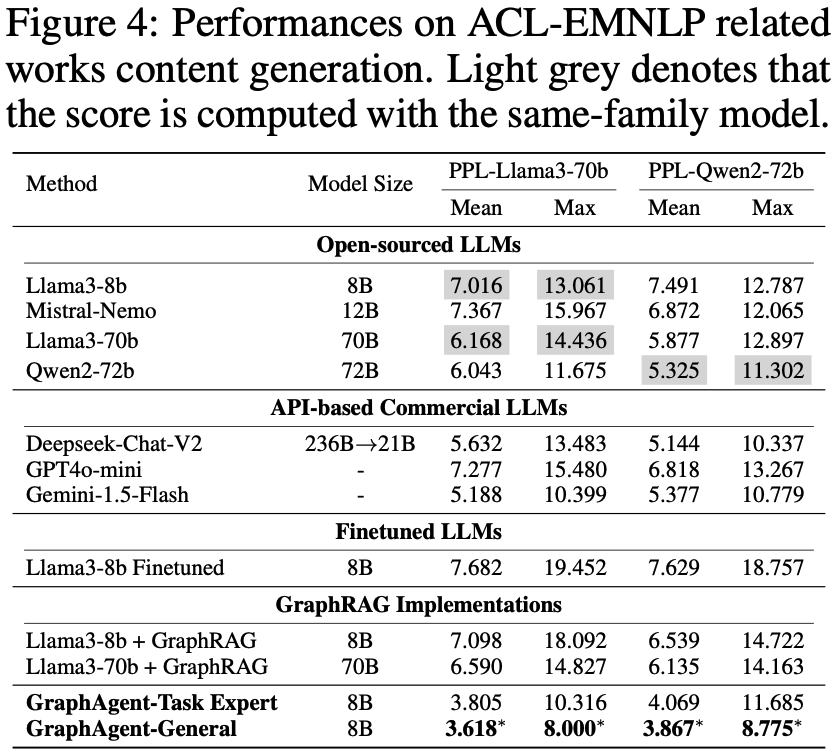
基于Llama3-70b和Qwen2-72b的双重对比验证表明,GraphAgent在困惑度(PPL)等核心指标上显著优于基线模型。不同于传统的监督微调(SFT)和GraphRAG方法,GraphAgent通过智能构建语义知识图谱,从根本上提升了模型的推理理解能力,有效解决了常规微调和知识注入方法在处理复杂推理模式时的固有局限。
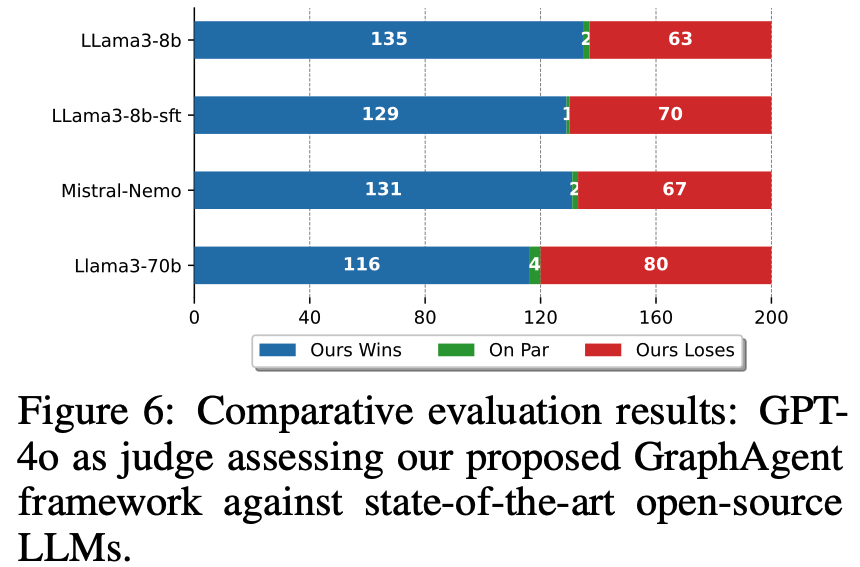
在架构创新和性能对标方面,GraphAgent展现出突出优势。
以GPT-4为评判基准的实验显示,GraphAgent相比Llama3-8b和Llama3-70b分别实现了114%和45%的性能提升,在67%的测试案例中领先同等规模模型,58%的情况下超越主流开源方案。
尤为显著的是,GraphAgent仅以8B的参数规模和极低的计算开销便达成这些卓越成果,充分验证了基于语义知识图谱的架构设计在增强文本生成能力方面的显著效果。
消融实验
通过系统化的消融实验(Ablation Study),研究团队深入评估了GraphAgent架构中三个核心组件的性能贡献,研究结果揭示了以下关键发现:
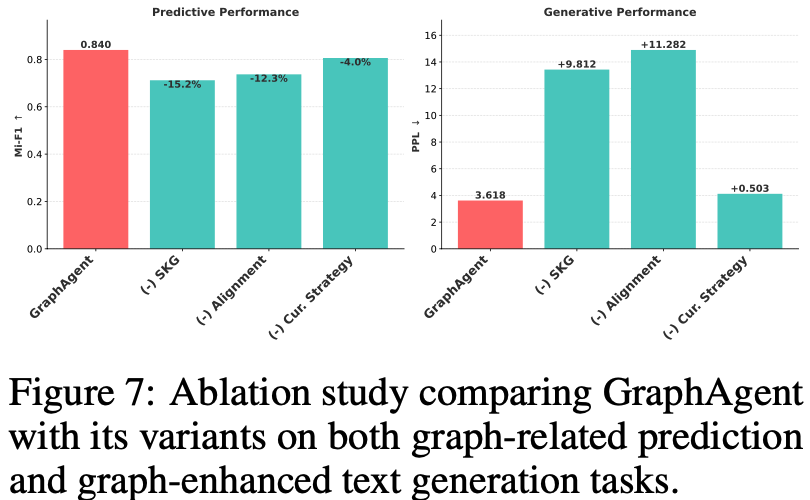
语义知识图谱(SKG)的基础支撑作用:移除SKG组件导致模型性能显著降低15.2%,充分证实了自动构建的语义知识图谱在提供关键补充信息方面的不可替代性。这一发现强调了结构化知识表示对模型整体性能的决定性影响。
图文对齐机制的重要性:实验表明,缺失图文对齐机制造成了最显著的性能损失,困惑度(PPL)增加达11.282。这突出表明深层次的图文理解能力对于需要复杂推理的生成任务至关重要,是保障模型高质量输出的关键环节。
课程学习策略的优化效果:虽然相较其他组件影响相对较小(预测任务降低4.0%,生成任务PPL增加0.503),但课程学习策略的缺失仍对双任务性能产生明显负面影响。这验证了渐进式学习路径在优化模型训练效果方面的积极作用。
最后研究团队透露了他们的未来研究方向,包括:
多模态能力拓展:计划将当前框架的处理能力扩展至视觉信息领域,建立支持关系型数据、文本内容和视觉元素的综合处理机制。这一拓展不仅包括多模态信息的理解与融合,还将重点开发跨模态知识表示和生成能力,从而实现更丰富的智能交互场景。特别关注视觉-文本-关系的协同建模,为多模态智能系统开辟新的研究方向。
模型性能优化:致力于提升模型在复杂现实场景中的泛化表现,重点研究如何在保持或提升性能的同时实现模型压缩。这涉及创新的模型架构设计、高效的参数共享机制以及先进的知识蒸馏技术。同时,将探索计算资源优化策略,提高模型在实际部署环境中的效率,为大规模应用奠定基础。
应用场景扩展:积极探索框架在多个实际领域的落地应用,重点关注科学研究辅助和商业智能分析等高价值场景。在科研领域,将开发专门的文献分析和知识发现工具;在商业领域,着重构建面向决策支持的智能分析系统。同时,密切关注新兴技术趋势,探索在医疗健康、金融科技等领域的应用场景。
项目地址:https://github.com/HKUDS/GraphAgent
论文链接:https://arxiv.org/abs/2412.17029
实验室主页: https://sites.google.com/view/chaoh
(文:量子位)