


近年来,跨境电商业务发展非常迅猛,吸引了众多企业投入其中,然而跨境电商行业也面临很多现实的问题和挑战。阿里国际的 AI 团队通过创新的 AI 解决方案来帮助企业解决跨境电商场景中的核心问题,同时构建共享的 AI 基础设施来降低 AI 使用的门槛。本文我们将结合跨境电商场景中的实践,为大家详细介绍阿里国际 AI 团队的模型服务框架 MarsPlatform。
MarsPlatform 主要包含任务切分调度,模型推理引擎,计算集群资源管理三部分,全链路全方位地为跨境电商业务提供高吞吐、低时延、低成本的模型服务。
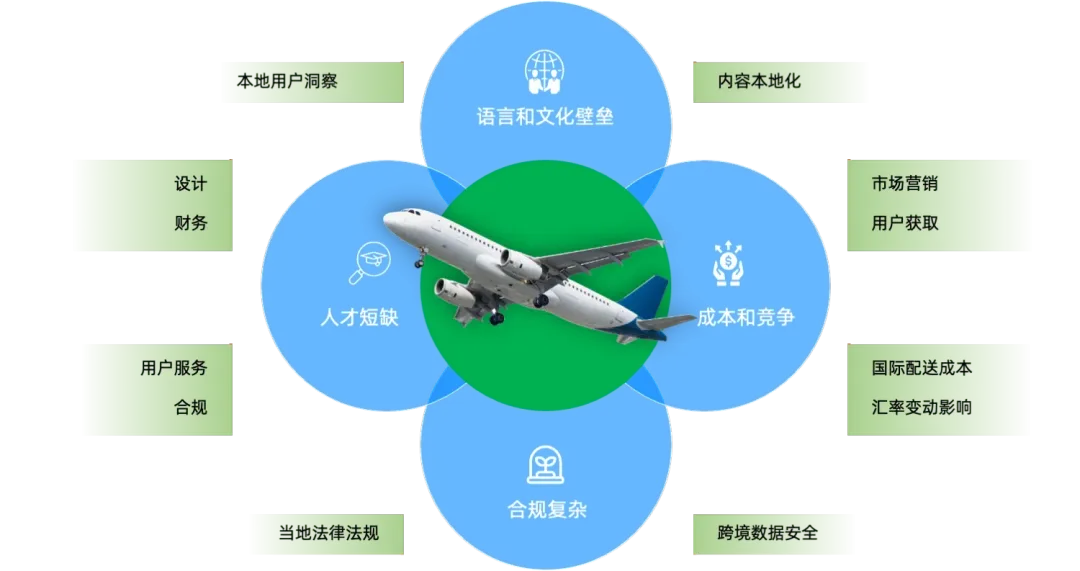
跨境电商业务目前正在如火如荼进行当中,有很多的中小企业也投入到跨境电商的行业当中,但是目前会遇到一些普遍存在的问题,比如语言和文化的壁垒、业务人才短缺、成本和竞争的压力以及合规的复杂性等问题,如下图所示。这些问题都需要投入比较多的人力和物力,那是否有更好的方法可以解决这些问题呢?比如创新的 AI 技术和产品。类似的问题在 AICon(全球人工智能开发与应用大会) 中也有过相关的讨论。
AIDC-AI 团队是阿里国际的 AI 技术部门,探索前沿 AI 技术与跨境电商业务的最佳实践和解决方案。
我们研发多语言的 AI 产品,同时为内部客户和外部客户打造共享的 AI 基础设施,降低 AI 使用门槛。我们目前的产品已经涵盖了整个跨境电商全链路,包括商品发布 (e.g. 商品信息翻译、图片翻译),营销投放,售前导购 (e.g. chatbot), 以及售后服务。同时我们的产品目前得到了广泛的应用,在全球超过 50 万商家受益,转化率和满意度等指标提升 1%-30%,应用场景覆盖超过 40 个,日均调用规模超过 2.5 亿次,并且还在不断上升, 支持的语言超过 60 种。
这些成果的取得,与团队创新 AI 技术的应用和推广息息相关,同时也与 AI Infra 的建设密不可分,比如模型推理服务框架。

AIDC-AI 团队的模型服务面临着许多方面的挑战。
-
首先是模型的多样性,如前面在 AI 产品中所述,包括多语言的翻译、文生成、多模态、图生成、图像处理等相关的应用。
-
其次是高吞吐量的需求,日均超过 2.5 亿的调用规模,对于模型吞吐量和批处理等方面提出了很高的要求。
-
第三是高实时性要求,目前一些应用跨三大洲服务部署,有毫秒级别的响应时延要求,需要降低服务 latency,保障客户体验。
-
最后是服务成本上的挑战,应用调用量大,机器资源使用较多,整体服务成本较高,需要提升资源利用率,降低服务成本。
为了解决这些问题和挑战,AIDC-AI 团队在 AI Infra 上进行了大量的研发,推出了自己的模型服务框架 MarsPlatform。
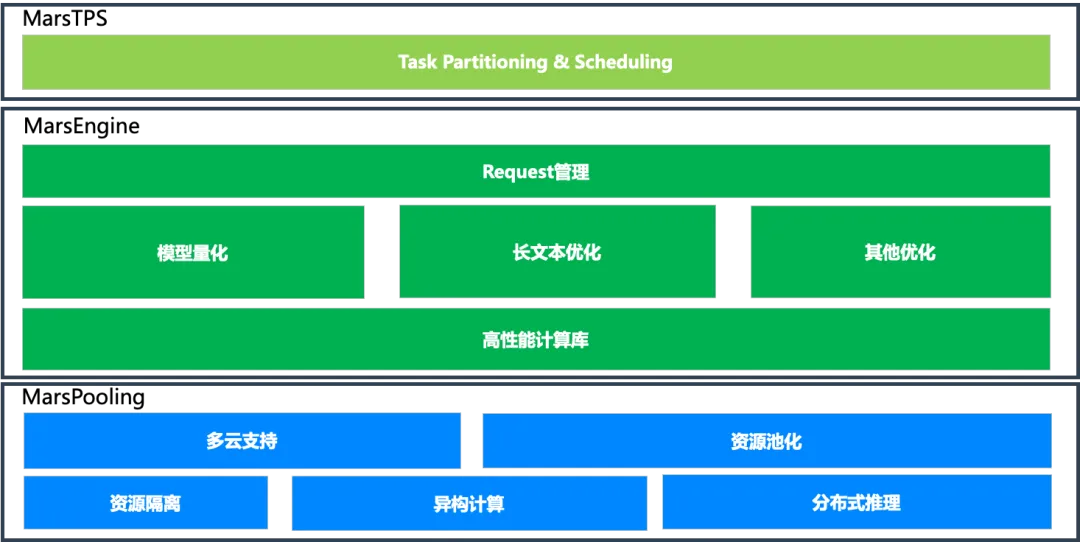
MarsPlatform 包含三部分的内容。第一部分是 MarsTPS,即 task partitioning & scheduling, 主要是对应用进行任务切分和调度,提升整体的计算的并行度和吞吐量。第二部分是 MarsEngine,即模型推理引擎,包括请求服务管理 (e.g. 请求批处理)、模型推理优化 (e.g. 模型量化、长文本优化、剪枝、蒸馏等)、高性能计算库等部分。第三部分是 MarsPooling,主要包括多云的支持、资源池化管理、资源隔离、不同资源异构计算以及分布式推理等方面的优化。我们将在后面逐步为大家详细展开各个部分的工作内容。
我们的应用在最开始执行的时候遇到较多的问题,整体资源利用率差, 吞吐量比较低。具体来讲,整个应用是作为一个整体去执行,没有 pipeline, 也无法异构执行。同时整个应用是串行执行的,无法并行。因此,就会需要比较多的机器资源来保障整体的服务吞吐,整体成本就比较高。
Task Partitioning & Pipelining
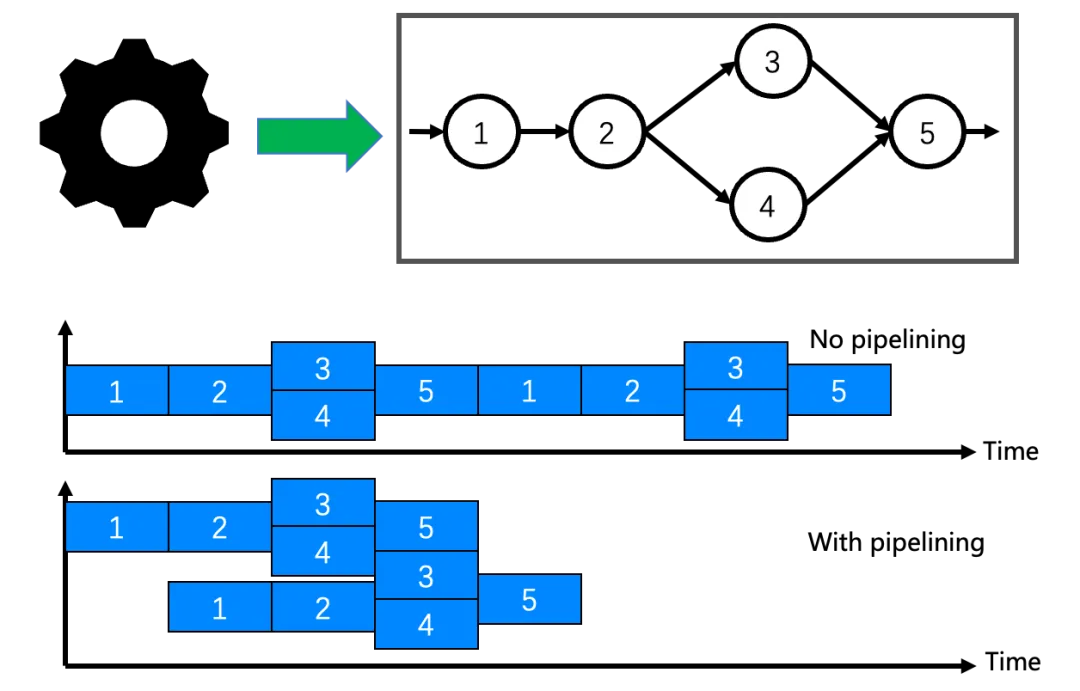
在 MarsTPS 我们首先应用 task partitioning,将一体执行的任务切分成不同的模块或者子任务,并且形成 DAG(Directed Acyclic Graph),可以在 model-level 切分,也可以在 function-level 切分,如下图所示。具体的,它将一个完整的任务切分成 5 个相互关联的任务图。然后应用任务流水执行,将任务从原来的串行执行变成流水线执行,提高计算资源利用率和应用的吞吐量。我们可以看到,相比于原来没有 pipeline 的执行 (no pipelining),流水执行 (with pipelining) 提升了资源利用率,缩短了整体执行时间。
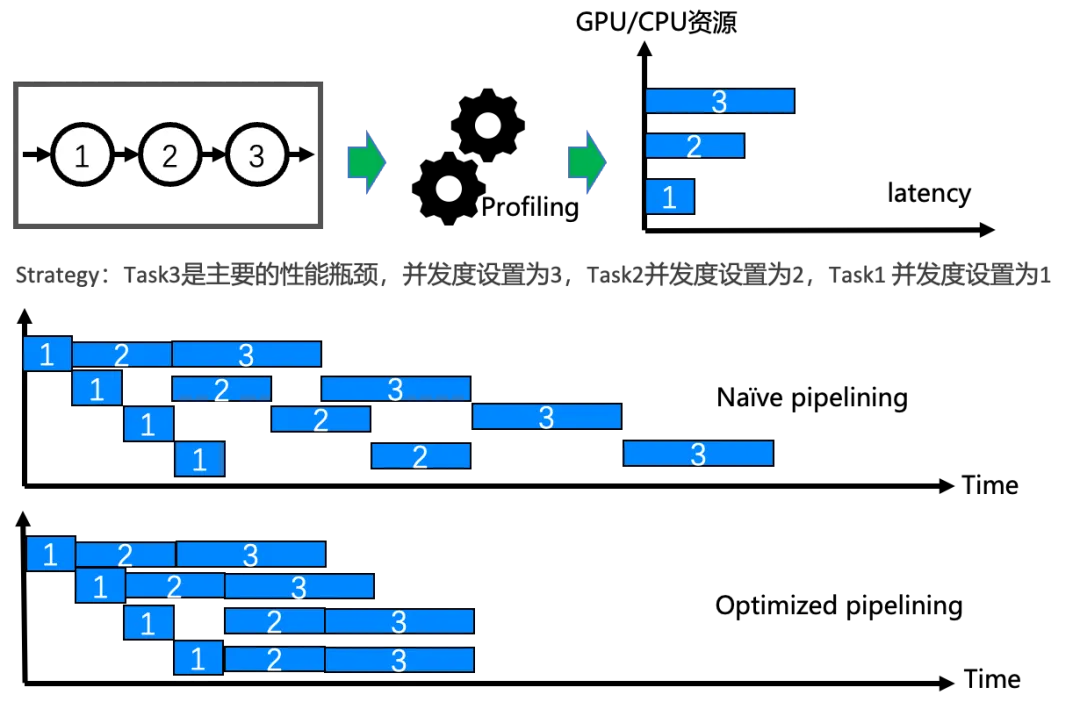
Task Profiling & Scheduling
除了 task partitioning & pipelining 之外,MarsTPS 还对每个 task 进行相应的 profiling,做更细节的优化策略。MarsTPS 将各个模块或者任务在不同的计算单元上 (GPU、CPU) 进行 profiling,得到相关的计算性能信息,比如执行时间,计算资源使用情况等。根据 profiling 的结果,以及计算资源的情况,来自动进行任务的调度,即确定各个任务的并发度,以及是否进行异构计算,比如调度在 CPU 上面,以减少 GPU 资源的消耗,达成计算资源利用和吞吐量的最大化。我们以一个例子来实际说明, 如下图所示。一个应用被切分成 3 个串行的任务, 通过对三个任务的 profiling,根据 profiling 的信息 (比如在同一个 GPU 上执行的时间和资源占用情况),将他们设置不同的并发度,以减少调度中的等待和资源浪费 (bubbles)。相比普通的 pipelining,优化后的 pipelining 可以进一步优化资源利用效率,提升吞吐,降低执行时延。
Case Study- 图片翻译
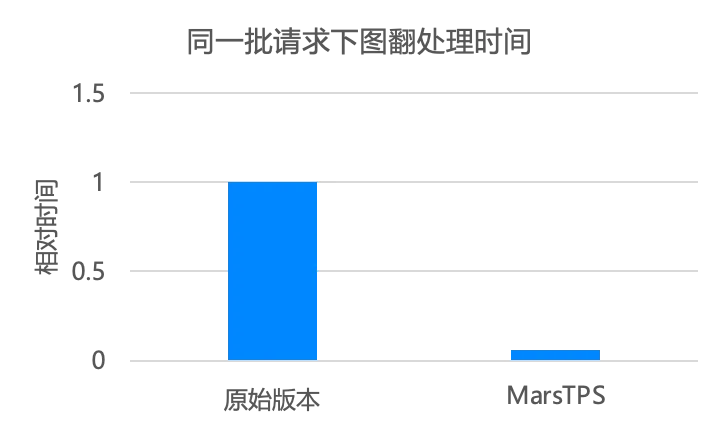
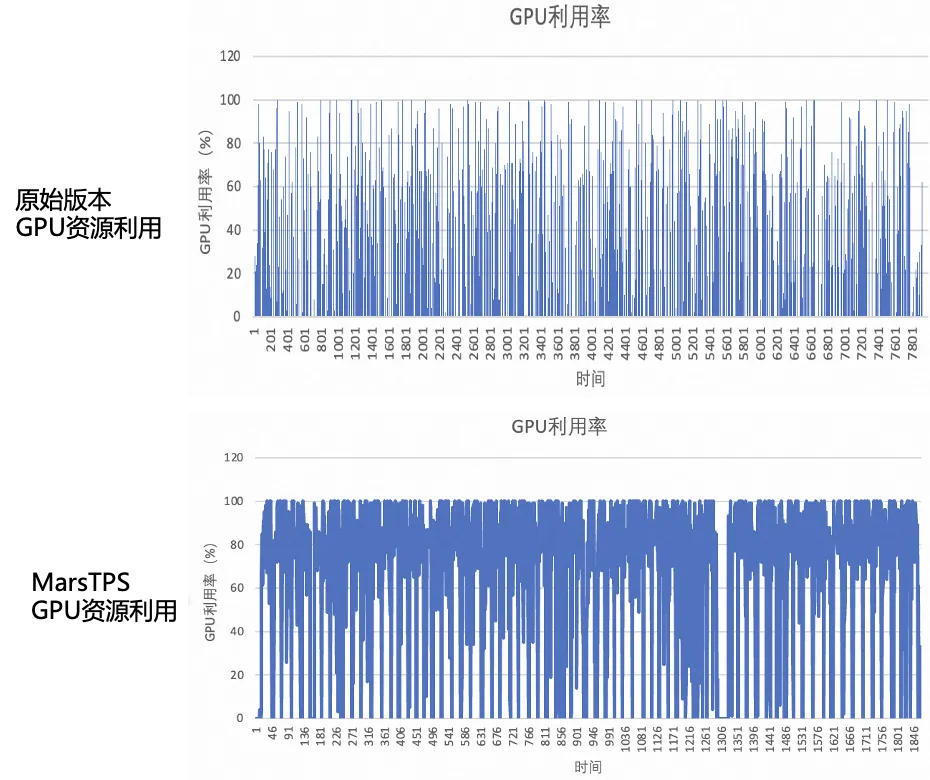
如前所述,图片翻译是跨境电商商品发布阶段一个使用很广泛的应用,它包含抠图、OCR、翻译、修复等多个 tasks,日均调用规模大,使用机器数量多。我们应用 MarsTPS 之后,同样的一批任务,整体执行时间被极大地缩短了。同时,观察整体 GPU 的利用率,MarsTPS 下面,GPU 资源利用相比原始版本有了大幅的提升。
MarsEngine 是 AIDC-AI 团队的模型推理引擎,负责模型的推理计算工作,我们在请求批处理优化、模型量化优化、LLM long-context 场景优化、模型剪枝和蒸馏等部分都做了相应的工作,下面将为大家逐步展开。
Batching 批处理优化
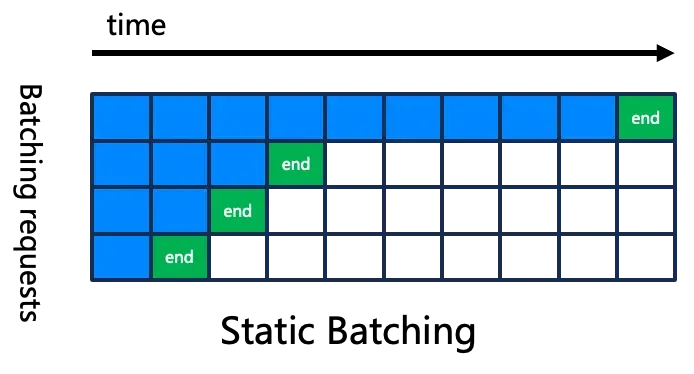
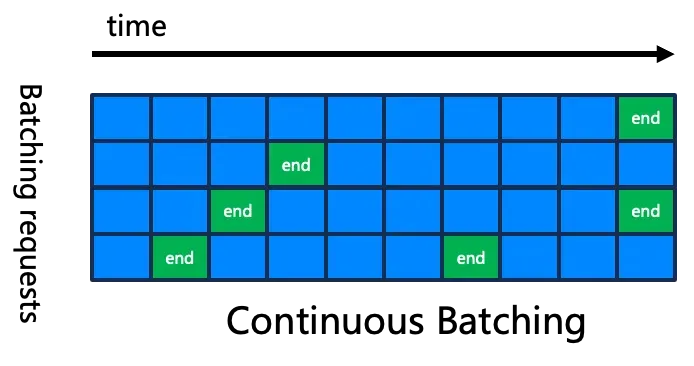
如前所述,批处理对于服务的吞吐量至关重要,因此,提升批处理的能力就很关键。我们使用最新的 continuous batching 的技术来优化整体吞吐,如下图所示。传统的 static batching,不同的 request 组成 batch 后,要等最长的一个 request 执行完毕,才能整体退出,因此当 request 序列长度差别较大时,容易造成计算资源的闲置和浪费。但是 continuous batching,当一个 request 执行完毕之后,可以继续插入新的 request,很好地解决了资源浪费的问题。
如前所述,我们在跨境电商业务中有大量多语言的翻译需求,并且翻译文本的序列长度差别很大,使用 static batching 极易造成资源的浪费和吞吐效率的低下。而使用 continuous batching 之后,相关问题得到了很好地解决,在翻译场景实测,整体吞吐量最高提升了 10x。
模型量化优化
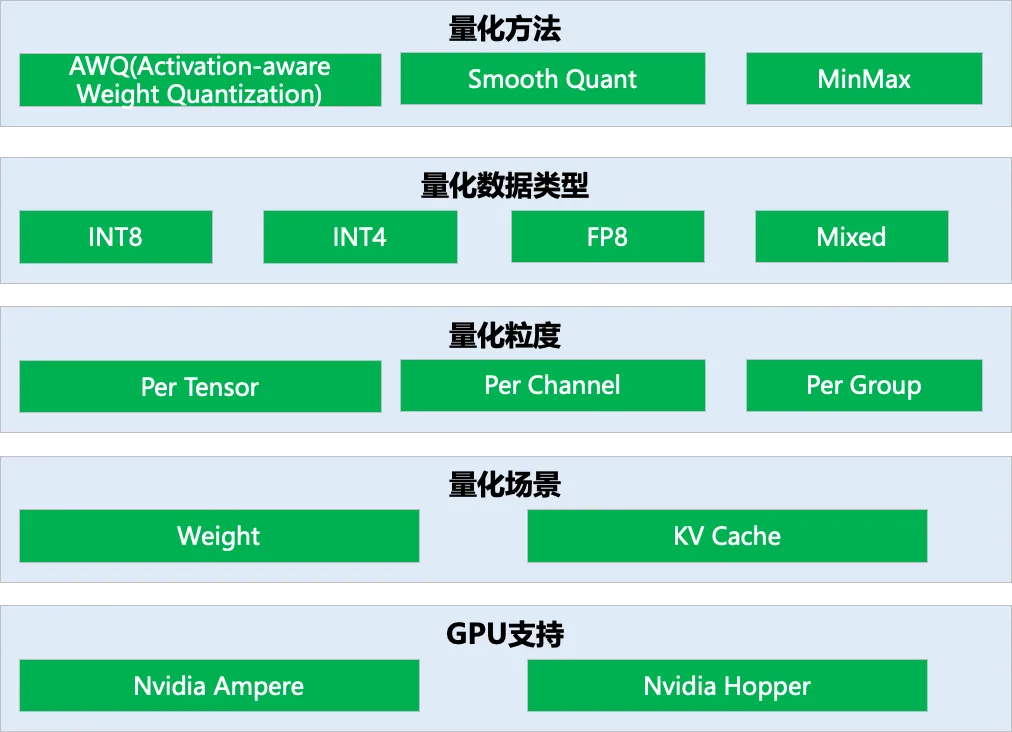
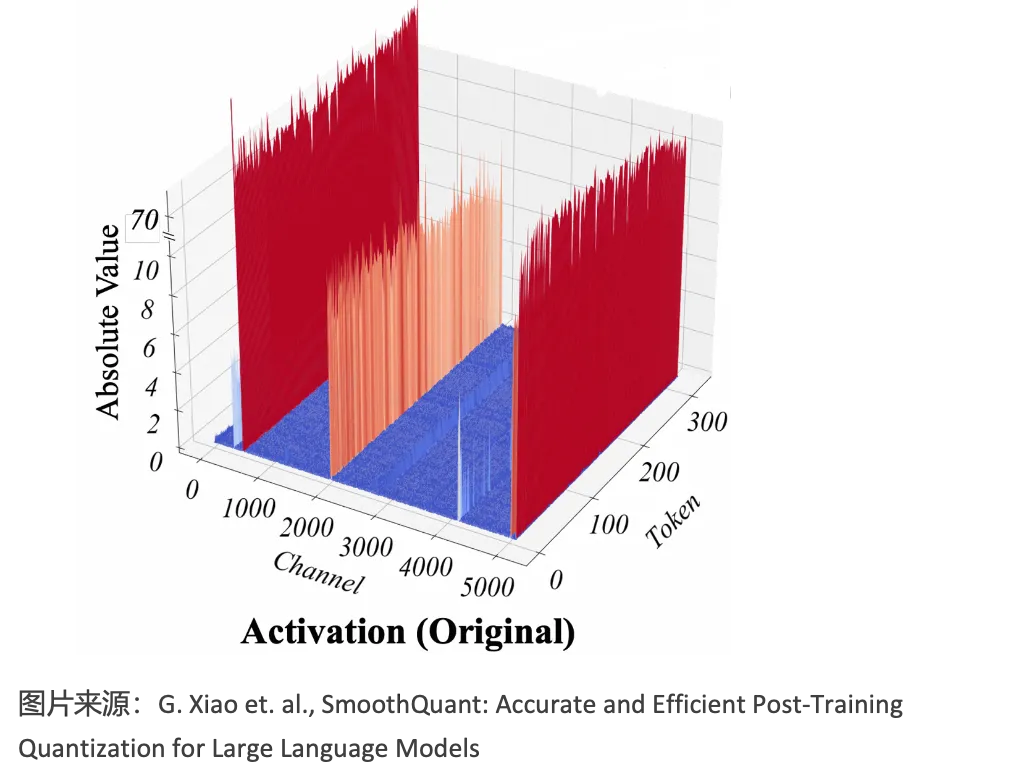
在模型推理过程中,由于模型的参数或者 activation 等数据的分布通常符合一定的规律 (比如高斯分布),量化的方法在保持精度变化很小的情况下,可以有效减少需要存储和传输的数据量,降低 memory 带宽的压力,同时也可以将计算转移到低比特计算,提升整体的计算性能。我们在业务中采用了 AWQ(Activation-aware Weight Quantization), Smooth Quant,MinMax 等量化方法,量化数据精度从 INT4,INT8,FP8,到混合精度量化。同时,量化的粒度从 per tensor,per channel 到 per group,在不同的粒度下权衡量化开销和模型精度。目前量化主要在 Nvidia 的 GPU 上进行,涉及到 weight、activation 以及 kv cache 的量化,具体如下图所示。
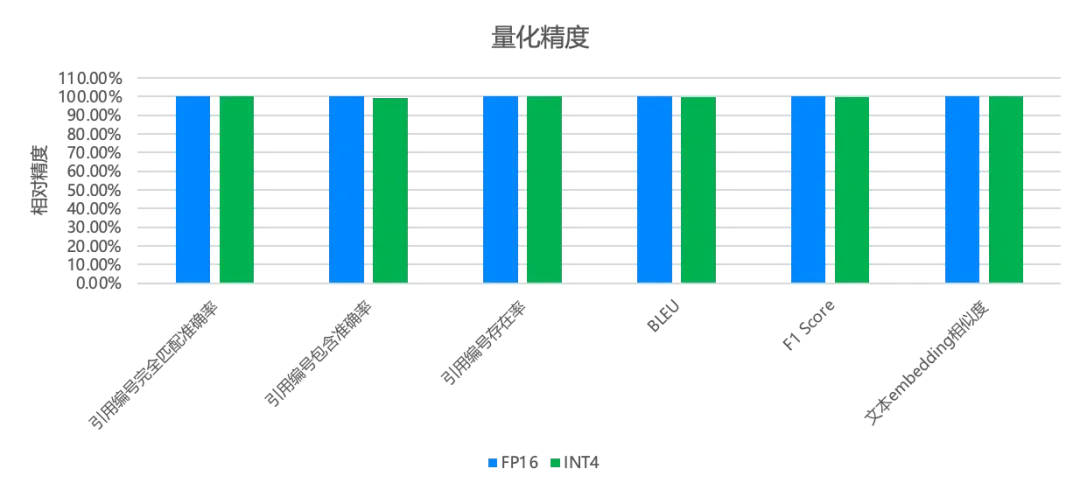
智能客服 (chatbot) 是跨境电商中的一个重要的场景,我们应用 INT4 AWQ 量化到智能客服的业务当中,相比原始的 fp16 版本,做到了精度基本不丢失,但是计算性能 (latency)2x。如下所示,INT4 量化之后,在各个指标上都保持了不错的精度,保证了服务的效果。
场景图生成也是我们重点关注的场景,它使用了 stable diffusion 的算法,这个场景中生图速度一直是我们的痛点。我们使用 int8 对 stable diffusion 中的重点模块 unet 进行 weight 和 activation 的量化。相比原始的 fp16 版本,生图效果基本保持不变,如下所示,但是整体生图性能 (latency) 提升了 30%。

长文本 (Long-context) 场景推理优化
跨境电商的 LLM 中会经常遇到 long context 的需求,比如长的商品详情描述,客服多轮对话等。如何提升 long-context 场景下 LLM 的推理性能,比如 TTFT(time to first token),是我们需要重点要解决的问题。我们目前使用了 prompt 压缩的方法以及 token pruning 的方法,为大家介绍如下。
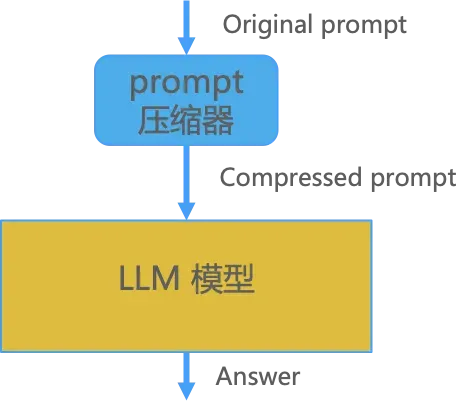
在 prompt 压缩的方法中,我们在 prompt 进入到 LLM 推理之前,设计了一个 prompt 压缩器,压缩掉一些不必要的 prompt 信息,如下图所示。prompt 长度变短之后,整体计算量减少,推理性能提升,但输出结果与原来基本一致。我们目前在业务场景中可以做到压缩 40% 的 prompt,整体性能提升 1.4x,同时精度符合应用要求。下图给出了一个实际的例子,输入的 prompt 从 5 行压缩到了 3 行,但是输出的内容在压缩前后基本保持一致。

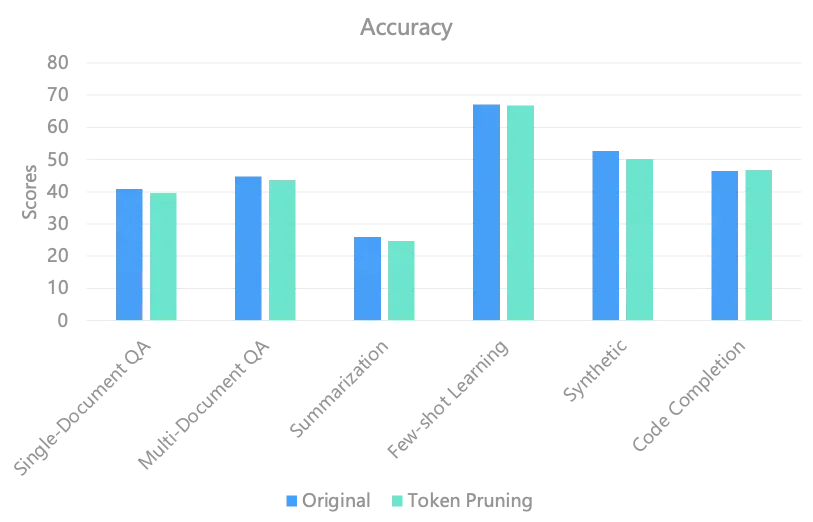
在 token pruning 的优化中,主要的逻辑是减少推理过程中相关度很小的 token 的计算,同时保持精度。根据 attention score 等相关的数据,对 token 进行剪枝,减少与被裁剪的 token 相关联的计算。我们在 Qwen1.5 32B 的模型上进行测试,精度损失很小,但是性能提升 30% 以上,具体数据如下所示。
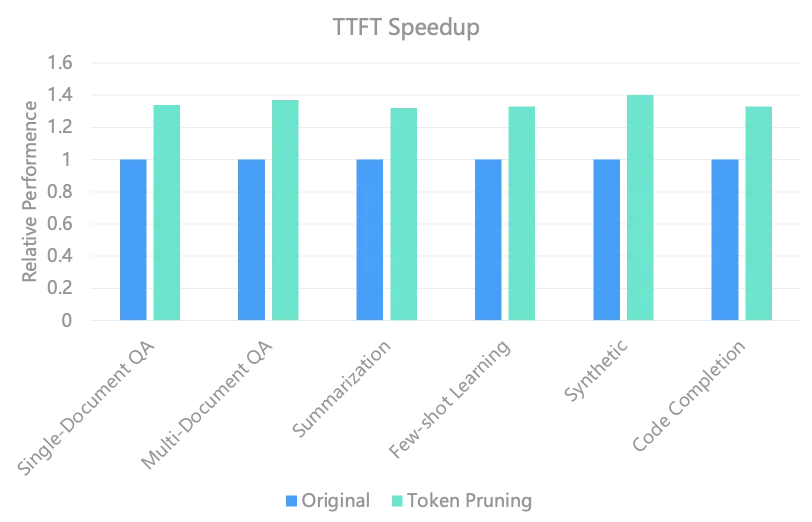
LLM Pruning
除了 token pruning 的工作外,我们在 LLM 上也进行整体的剪枝优化工作,以减少一些不必要的计算,提升整体的推理性能。我们观察到在 LLM 中,一些 token 特征的 channel 维度,有数据稀疏相关的一致性,因此在 channel 维度进行模型剪枝的实践,剪掉一些数值极小的 channel。我们在翻译场景进行测试,精度损失 0.17%, 性能 (latency) 提升 1.1x。
Stable Diffusion 模型蒸馏
文生图应用也是目前业务中非常重要的一环, 我们使用 stable diffusion 的生图模型,如前所述,文生图的模型推理一般耗时较高,因此成本也较高。为了能够进一步降低成本,降低推理耗时,我们使用知识蒸馏的方法,压缩 stable diffusion 的核心 unet 部分的 step 数目。从实践来看,我们目前的生图效果基本保持不变,计算性能 (latency) 提升约 50%。

除了在模型推理部分进行细致的优化外,我们在底层的计算集群层面也进行资源管理和使用方面的优化,包括推理的资源,也包括我们训练的资源。在这部分,我们重点介绍 MarsPooling 是如何从资源管理角度来进一步提升资源的利用率,降低成本的。
在资源的使用过程中,我们经常会遇到各种使资源利用效率低下的问题。首先是碎卡问题,训练集群中,小型训练任务 (几卡) 会让一机 8 卡的整机卡数碎片化,碎片增多的情况下会导致虽然有额度,但是大型任务无法调度的情况出现。其次是资源闲置问题,训练或者推理集群因为任务的动态变化,会有资源没有被调度,或者请求减少,导致资源闲置的情况。最后是单卡利用率低的问题,比如模型比较小,无法充分利用单卡 GPU 上的所有资源,导致资源浪费。针对这些问题,我们提出了对应的一些设计方案。
训练 / 推理资源池化
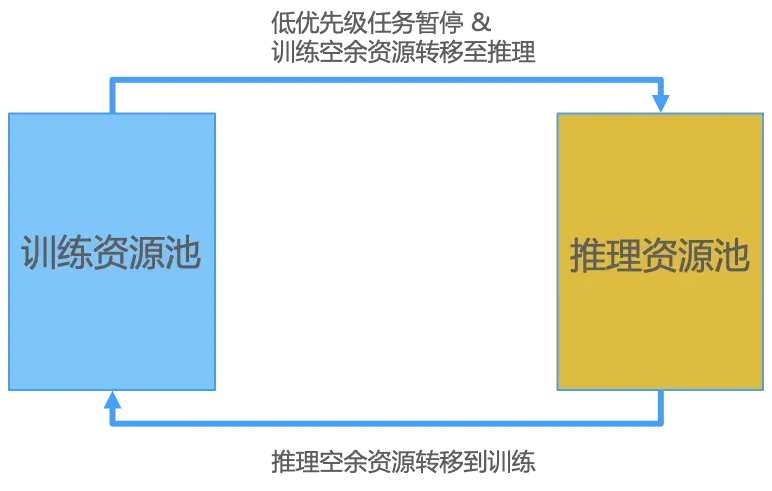
首先是提供资源的池化方案。大的训练资源池使用粒度为台 (比如一机八卡),小型任务则分池处理,避免小的训练任务导致的碎卡影响大的训练任务。同时资源可在训练和推理资源池相互转移,提高资源的利用率,比如当推理资源不足时,低优先级训练任务暂停,资源转移至高优先级推理任务;当推理资源闲置时,也可以将闲置的资源转移到训练集群,承接相关的训练任务。
资源动态扩缩容
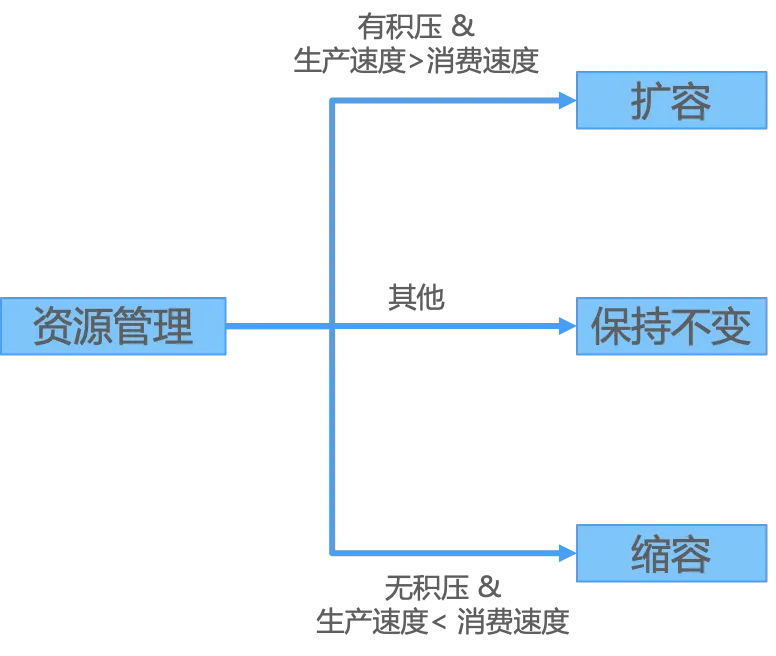
目前同步实时的动态扩缩依然比较困难,一个是目前业务的流量难以预测,第二是生成式模型一般较大,服务拉起时间比较长。但是对于离线异步的任务来讲,它们无实时性要求,任务可以容忍一定的积压,动态扩缩资源就成为可能,可以根据请求积压、生产速度、消费速度等情况进行动态扩缩容, 具体信息如下图所示。
GPU 资源隔离
在我们的业务实践中,会遇到小模型要部署到大的 GPU 卡上的情况,这种情况下面,一般就会出现前述的单卡 GPU 利用率低的情况,比如在翻译场景,我们就遇到需要在 A100 上部署,但是资源利用率低的情况。为了能够提高资源的利用率,我们对大的 GPU 卡进行资源隔离的操作,比如通过 nvidia 提供的 MPS(Multi-Process Service) 和 MIG(Multi-Instance GPU) 操作,将 GPU 分成不同的部分,从而可以部署更多的应用,提高资源的利用率。我们在翻译场景进行实践,使用 MPS 和 A100,整体 A100 的吞吐效率 2x。
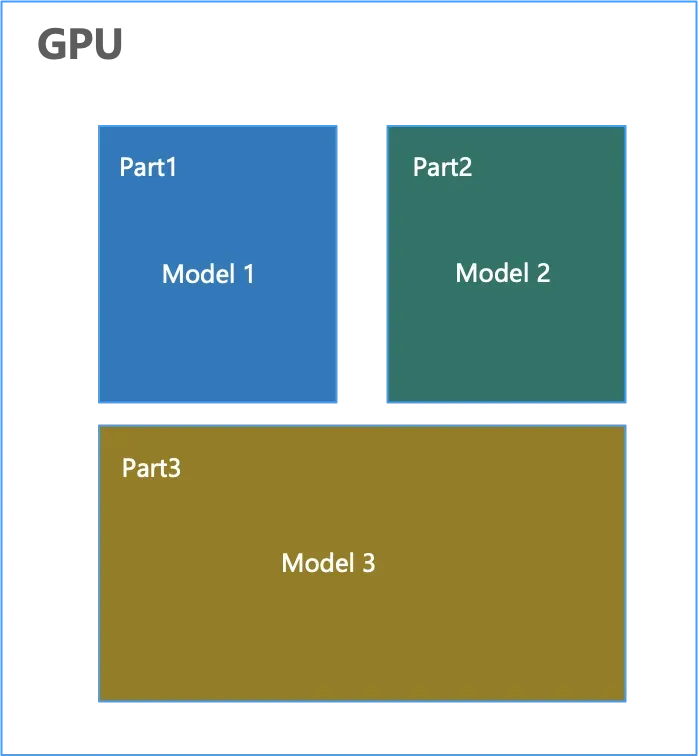
在本文中,首先给大家介绍了跨境电商的业务以及面临的挑战。目前跨境电商业务发展迅速,且规模庞大,但是在语言文化、本地化、人才、成本、竞争、合规等方面都面临很大的挑战。阿里国际的 AI 团队聚焦在跨境电商的核心业务,通过 AI 技术创新和 AI 基础设施的建设,为跨境电商业务提供更好的产品和解决方案。其次给大家详细介绍了阿里国际 AI 团队在模型服务层面的框架 MarsPlatform。MarsPlatform 通过 MarsTPS,MarsEngine,MarsPooling 三方面的工作,从上层的任务切分调度,到中间的模型推理优化,到下层的计算集群资源管理,全链路全方位地为跨境电商业务提供高吞吐、低时延、低成本的模型服务。
在未来的模型服务中,我们依然面临着很多的挑战。首先,在目前的生图服务中,我们依然面临着生图服务时间较长、成本较高的问题,还需要在算法和模型服务层面进行进一步的优化,去降低生图的成本。其次,多模态的模型的使用也越来越广泛,AIDC-AI 团队也自研了 Ovis 多模态模型, 未来结合 MarsPlatform 和 Ovis,打造有竞争力的多模态产品方案将是我们未来的重要目标。最后,agent 领域的应用也在不断涌现,如何解决 agent 应用中的慢思考太慢的问题,包括持续的 long-context 优化以及并行化的推理技术,也是未来的重要研究课题。
(文:AI前线)