
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
斯坦福大学医学院的研究人员在知名医学期刊JAMA Network Open发布了一篇论文,主要深度研究了大语言模型在医疗领域的应用。
研究人员将收到参与测试的病人信息转发到EHR 开发平台Epic,并通过 GPT-4G、PT-3.5 Turbo进行内容分类,然后自动生成对应的回复草稿。
本次共有197名临床医护人员参与了测试,这包括58名保健医生和高级医师、10名护士以及胃肠肝脏内科83名医生和高级医师、4名护士和8名临床药剂师等。
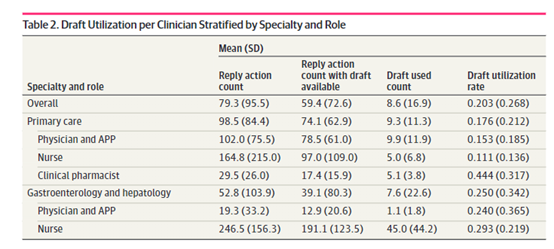
结果显示,在5周的测试期间,平均20%的回复由AI生成,在胃肠病学和肝病学,护士的利用率最高为29%;临床药师在初级护理中的利用率最高为44%,这表明大语言模型在不同临床情境下的适用性和价值可能存在一定差异。

斯坦福大学医学院的研究人员主要使用了RE-AIM框架,对大语言模型的应用研究进行了深度评估,主要包含覆盖范围、有效性、采纳、实施以及维护/实用性5大维度。
PRISM评估结果
覆盖范围方面,该研究的参与者包括初级保健和胃肠肝脏内科的所有主治医生、高级执业从业人员、诊所护士和临床药剂师共计197名。
尽管有14名预先参与测试的医生、16名出差人员和5名无具体门诊的人员被排除在外,但最终有163名医护人员参与测试,仍占原始招募人数的82%。这较高的参与率,反映了医护人员对大语言模型在医疗易用的高度兴趣。
有效性方面,主要提现了AI生成回复草稿在提升工作效率和改善医生职业体验两个方面的有效性。
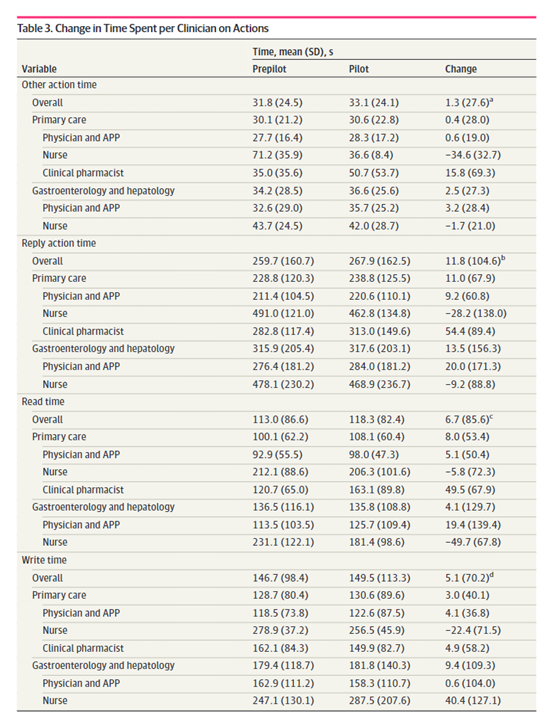
在工作效率方面,研究评估了医生在其他操作、回复动作、阅读和撰写消息等环节的平均耗时变化。结果显示,与试点前相比,这些时间指标并未出现显著改善。
但在职业体验方面,研究发现医生的认知负荷和工作倦怠均有明显下降。试点结束时,参与医生的4项医生任务负荷得分从61.31下降到47.26,工作倦怠得分也从1.95下降到1.62,这表明大语言模型有助于缓解医生的精神压力。
此外,医生对回复草稿的实用性、质量和时间效率等方面的主观感受,在试点前后也基本保持稳定,这进一步验证了大语言模型的有效性。
采纳方面,重点关注了参与测试的医生、护士对AI生成回复草稿的实际使用情况。在5周的测试期间,平均20%的回复由AI生成,在胃肠病学和肝病学,护士的利用率最高为29%;
临床药师在初级护理中的利用率最高为44%,这表明大语言模型在不同临床情境下的适用性和价值可能存在一定差异。
实施方面,主要评估了AI生成回复草稿在技术可靠性、部署质量以及适应性等方面的表现。在技术可靠性方面,研究人员在试点正式开始前,先组织14名医生进行了为期1个月的测试,验证了系统的稳定性和回复草稿的有效性。
此外,研究还通过电子健康记录集成、HIPAA合规性等措施,确保了新技术的可行性。
在部署质量方面,研究人员通过培训、沟通等方式,向参与医生提供了必要的支持,确保他们能够顺利掌握新工具的使用。参与医生的使用体验和满意度也在整体上较为良好。
在适应性方面,研究人员发现,AI生成回复草稿在某些专科和角色中的应用价值更高,体现了这一技术在不同临床情境下的适应能力。
维护/实用性方面,尽管大语言模型在某些特定领域并未带来显著改善,但在改善医生的职业体验方面取得了积极成果。医生的工作倦怠感有明显下降。
在持续使用意愿方面,医生对未来使用大语言模型生成回复草稿表现出了较强的期望和兴趣。医护人员普遍认为大语言模型能够在未来医疗工作中发挥重要作用,并提出了一些优化建议。
(文:AIGC开放社区)