

Sky-T1 以 不到450美元 的成本,训练出媲美 o1-preview 的开源推理模型,揭示了低成本、高质量AI的新可能性。通过 全面开源、精选数据集 和 高效训练方法,Sky-T1在数学、代码等领域均展现卓越性能,为开源社区和学术界打开了一扇新的大门。Sky-T1 的训练过程,充分利用了 开源模型 QwQ-32B-Preview 和 Llama-Factory 框架,是实现低成本训练的关键。
想象一下,一个小型创业团队,仅仅花费了不到 450 美元,就训练出了一个可以媲美 OpenAI 最先进的推理模型,这听起来像天方夜谭吗?但加州大学伯克利分校的 NovaSky 团队,用他们的实际行动,证明了这一切并非不可能。他们发布了 Sky-T1-32B-Preview,一个令人瞩目的开源推理模型。更令人震惊的是,这个模型仅花费了 不到 450 美元 的训练成本,就达到了与 o1-preview 模型相当的推理和代码能力!这不仅打破了高性能模型必须依赖巨额投入的传统观念,也为开源社区带来了新的希望。Sky-T1 的出现,无疑给开源社区打了一剂强心针,证明了低成本、高质量AI的潜力,为 “AI平民化” 迈出了重要一步。

开源推理模型:一场打破巨头垄断的竞赛
大型语言模型(LLM)在自然语言处理、代码生成等领域展现出惊人的能力,其中,推理能力是 LLM 的重要组成部分。诸如 o1 和 Gemini 2.0 等模型,通过构建复杂的内部“思维链”,能够解决过去认为难以解决的问题。然而,这些模型的封闭性给整个 AI 生态带来了挑战。它让真正掌握技术的人们,成为了技术的“打工人”,贡献了数据和算力,却无法掌握核心的技术。高性能模型似乎成了少数巨头的专属“玩具”,普通研究者和开发者只能望洋兴叹,这无疑限制了整个AI生态的健康发展。
虽然有一些开源的数学推理模型如 Still-2 和 Journey 正在出现,但它们通常专注于特定领域,且模型的训练和使用依然存在较高的门槛。开源社区需要一个更加开放、透明、易于复制的解决方案。而 Sky-T1 的出现,恰好填补了这个空白。Sky-T1 团队的使命,正是希望通过开源的方式,让更多人能够参与到最先进的 AI 技术的发展中来。这是打破巨头垄断,促进 AI 技术民主化的重要一步,让 “思考引擎”不再是少数人的专利,而是每个人都能触手可及的智能工具。
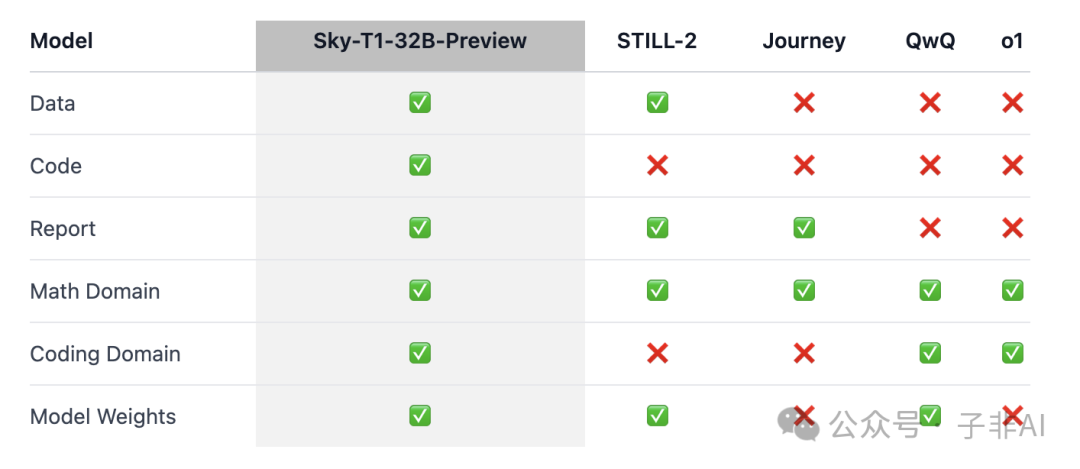
Sky-T1 的核心竞争力:全面开源,打破壁垒
Sky-T1 的核心竞争力在于其 全面开源。NovaSky 团队不仅开源了模型权重,还公开了训练模型所需的全部基础设施、数据和技术细节。这使得任何研究人员或开发者都能够轻松复现、改进和扩展他们的工作。
-
• 开源基础设施: Sky-T1 项目提供了一个完整的代码库 SkyThought ,其中包含了构建数据、训练和评估模型的全套工具和脚本,用户可以在该代码库中一站式完成模型的训练和部署。这大大降低了研究门槛,让每个人都有机会参与到前沿研究中,不再受限于高昂的成本和复杂的技术。 -
• 开源数据: Sky-T1 使用的数据集包含了 17K 个高质量、多领域的样本,涵盖数学、代码、科学和谜题等多个领域。这些数据为模型的训练提供了坚实的基础。 -
• 开源技术细节: NovaSky 团队还提供了详尽的技术报告 Sky-T1 技术报告,并公布了 Wandb 日志 Wandb Log,让研究者可以深入了解模型的训练过程和性能表现。这种透明度是开源精神的重要体现,也为其他研究者提供了宝贵的参考资料。 -
• 开源模型权重: Sky-T1 最大的亮点莫过于其开源的 32B 模型权重 Hugging Face,用户可以直接下载和使用该模型。这让更多人能够直接体验到高性能推理模型带来的便利,促进 AI 技术的普及和应用。
与其他开源模型相比,Sky-T1 的全面性使其更具吸引力。Sky-T1 不仅开源了模型本身,还提供了完整的训练流程和数据,为开源社区提供了一个完整的参考框架,使得更多人能在此基础上进行研究和创新。可以说,Sky-T1 已经做到了“授人以渔”,而非简单的“授人以鱼”,它为开源社区提供了真正的“思考利器”,让每个人都能够成为 AI 时代的参与者和贡献者。
Sky-T1:低成本高性能模型的破局之道
Sky-T1 的成功并非偶然,其背后是精心策划的数据收集和高效的训练方法。而能够以 450 美元完成训练的核心原因在于,充分利用了现有的开源资源和高效的训练框架,而不是从零开始构建一切。这体现了开源协作的力量,也为低成本 AI 发展提供了重要借鉴,告诉我们,高科技并非一定要高成本,开源协作可以让科技更普惠。
-
• 数据收集: NovaSky 团队首先使用 QwQ-32B-Preview 模型生成高质量的训练数据。QwQ-32B-Preview 本身就是一个具有强大推理能力的开源模型,其表现可与 o1-preview 相媲美。为了确保数据的多样性,他们从多个领域收集数据,包括数学、代码、科学和谜题等。 -
• 多领域数据覆盖: 数据集涵盖了多个领域,能够使模型学习到不同类型的推理模式,从而提高模型的泛化能力。这保证了 Sky-T1 模型拥有更强的适应能力,能够处理各种复杂任务,不再局限于单一场景。 -
• 拒绝采样: 为了提高数据质量,他们采用了拒绝采样策略,即丢弃那些与已知答案不匹配的数据。这就像为模型剔除“杂质”,只保留“精华”,大幅提升了训练效率,避免了不必要的资源浪费。 -
• GPT-4o-mini 重写: 他们还使用了 GPT-4o-mini 模型将 QwQ 的推理过程重写为格式良好的版本,这种格式化的数据能够显著提高模型的解析效率,使得模型能够更好地理解推理过程和答案。例如,在 APPs 数据集中,原始数据中代码可能出现在任何位置,导致模型解析错误率高;经过重新格式化后,代码统一出现在最后,模型的解析准确率从 25% 提高到了 90% 以上,这充分说明了数据格式化对于模型训练的重要性,让“燃料”更高效。 -
• 训练过程:Sky-T1 基于 Qwen2.5-32B-Instruct 模型进行微调。Qwen2.5-32B-Instruct 是一个不具备推理能力的开源模型。他们使用开源的 Llama-Factory 框架进行训练,训练使用了 8 个 H100 GPU,仅耗时 19 小时,总成本 不到 450 美元。 -
• 低成本训练: 仅仅 不到 450 美元 的训练成本,却能得到如此强大的模型,这不得不说是一个奇迹,证明了高效的训练方法在 AI 发展中的重要性。这为那些没有巨额预算的小型团队和个人开发者提供了无限可能,打破了算力垄断,也为低成本AI时代拉开了序幕。 -
• Llama-Factory 加持: Llama-Factory 是一个流行的开源 LLM 微调框架,它的使用,大大简化了模型的训练过程,使即使是非专业人士也能轻松上手。这使得模型微调不再是高不可攀的技术,每个人都能参与其中,推动技术创新,让 “人人都能炼丹”不再是梦想。
Sky-T1 的卓越表现:性能超越预期,多领域领先
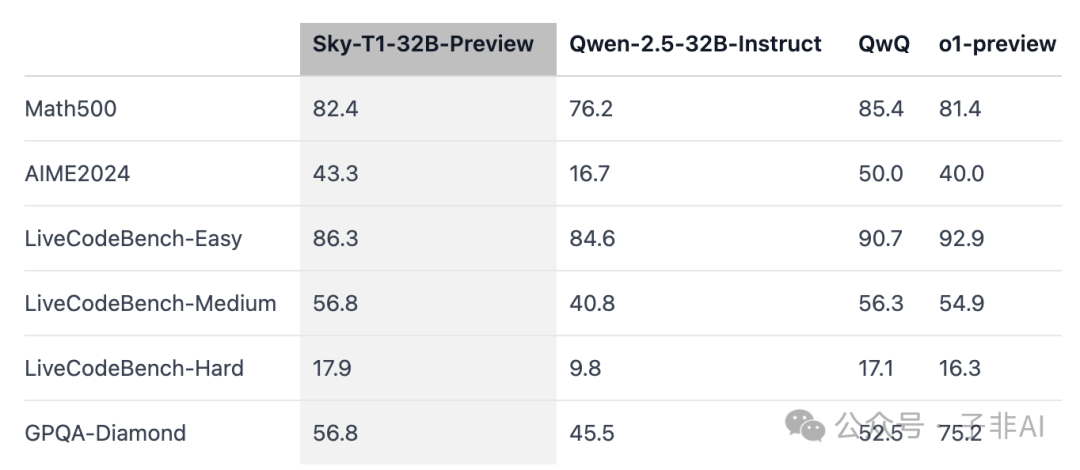
Sky-T1-32B-Preview 在多个基准测试中表现出色,性能可与 o1-preview 相媲美,甚至在某些指标上更胜一筹。这再次证明了,开源模型完全有能力达到甚至超越闭源模型的水平,为开源社区注入了强大的信心,也证明了 “小成本也能做大事” 的可能性。
-
• 数学推理能力: 在 Math500 和 AIME2024 等基准测试中,Sky-T1 展现了强大的数学推理能力。例如,在 AIME2024 测试中,Sky-T1 的准确率达到了 43.3%,而 Qwen-2.5-32B-Instruct 模型的准确率仅为 16.7%。 -
• 代码能力: 在 LiveCodeBench 基准测试中,Sky-T1 在 Easy、Medium 和 Hard 三个难度级别上都表现出色,这表明该模型不仅具有强大的数学推理能力,还具备了处理复杂代码的能力。Sky-T1 在代码方面的表现,甚至超越了许多专注于代码生成的大型模型,证明了其多领域的卓越性能,不再是 “偏科生”。 -
• 与其他模型对比: 从表格中可以看出,Sky-T1 在多个基准测试中都与 Qwen-2.5-32B-Instruct、QwQ 和 o1-preview 等模型进行了性能对比,结果显示 Sky-T1 性能不逊于 o1-preview,在某些方面甚至更好。 -
• 多领域表现卓越,综合能力强大: Sky-T1 在数学和代码两个领域都表现出色,证明了其强大的综合能力。这使得 Sky-T1 不仅可以用于解决数学问题,还可以应用于代码生成、bug修复等多种场景,具有广泛的应用前景,成为了名副其实的“全能选手”,让人们看到了AI模型多领域应用的巨大潜力。 -
模型尺寸和数据混合:推理能力的“左膀右臂”
在研究过程中,NovaSky 团队还有一些重要的发现:
-
• 模型尺寸: 模型尺寸对于推理能力至关重要。他们发现,小型模型(如 7B 和 14B)的改进有限,并且会频繁生成重复内容,这严重限制了其推理效果。因此,他们选择使用 32B 模型进行训练,最终取得了卓越的性能。这表明,对于推理任务而言,模型尺寸越大,其表现通常也会越好,但大模型的训练也意味着更高的成本,Sky-T1 在此方面做了很好的平衡,用有限的资源达到了最好的效果。 -
• 数据混合: 数据混合对于模型的性能也至关重要。最初,他们只使用数学数据进行训练,虽然在数学任务上的准确率大幅提升,但加入代码数据后准确率却有所下降。**这表明,不同领域的推理方式存在差异,单一领域的数据无法满足多领域推理的需求,就像 “偏食” 的孩子无法获得全面的营养一样。**他们通过平衡数学和代码数据,并针对两者的不同推理模式进行了数据处理,最终使得模型在两个领域都表现出色。这一发现也为未来的多领域模型训练提供了重要的借鉴,证明了数据混合的重要性,也为我们提供了更有效的训练思路。
Sky-T1 的创新之处:开启人人皆可拥有的“思考引擎”时代
-
• 低成本高性能: Sky-T1 以极低的训练成本实现了与闭源模型 o1-preview 相当的性能,这为更多研究者和开发者打开了探索高性能推理模型的大门,有望加速该领域的创新,让 “AI平民化” 不再是遥不可及的梦想。 -
• 数学与编码推理融合: Sky-T1 在同一个模型中实现了数学和编码领域的推理能力,这不同于以往专注于单一领域的推理模型,这种文理兼备的“全能选手”更贴近人类的认知方式,具有更高的实用价值,让 “一招鲜吃遍天” 的时代成为过去。
Sky-T1,只是一个开始
Sky-T1 的出现,无疑为我们打开了一个全新的视角,让我们看到了低成本、高质量 AI 的可能性。它不仅是一款强大的推理模型,更是开源精神的体现,是 AI 技术民主化的重要一步。那么,在看到 Sky-T1 的强大性能后,你是否也想尝试一下,利用它构建属于你自己的 “思考引擎”?你认为 Sky-T1 的出现对开源社区意味着什么? 欢迎在评论区留言,分享你的看法和建议。
年度AI合集
相关链接
-
• Sky-T1 论文链接: https://novasky-ai.github.io/posts/sky-t1 -
• SkyThought 代码库链接: https://github.com/NovaSky-AI/SkyThought -
• 模型权重下载链接: https://huggingface.co/NovaSky-AI
(文:子非AI)