


随着人工智能技术的飞速发展,多模态大模型已成为研究的新趋势,它们能够整合视觉、听觉等多种感官信息,提供更自然的交互体验。InternLM-XComposer-2.5-OmniLive(浦语·灵笔2.5-OL)正是这一领域的最新成果,它不仅能够理解文本和图像,还能处理视频和音频流,实现真正的多模态交互。
一、模型概述
InternLM-XComposer-2.5-OmniLive(浦语·灵笔2.5-OL)是一款国产开源的多模态大模型。它主要功能涵盖了对视觉和听觉信息的深度处理与交互,能够实现超高分辨率图像的理解、多轮多图像对话、视频理解与网页制作以及文章创作等复杂任务。其特点鲜明,在视觉方面,能够精准地识别和理解图像中的各种元素、场景以及它们之间的关系;在听觉方面,可以准确地解析音频信号,无论是语音指令还是环境声音,都能有效处理并与视觉信息协同整合,从而实现真正意义上的实时交互,为用户提供更加智能、便捷和丰富的体验。
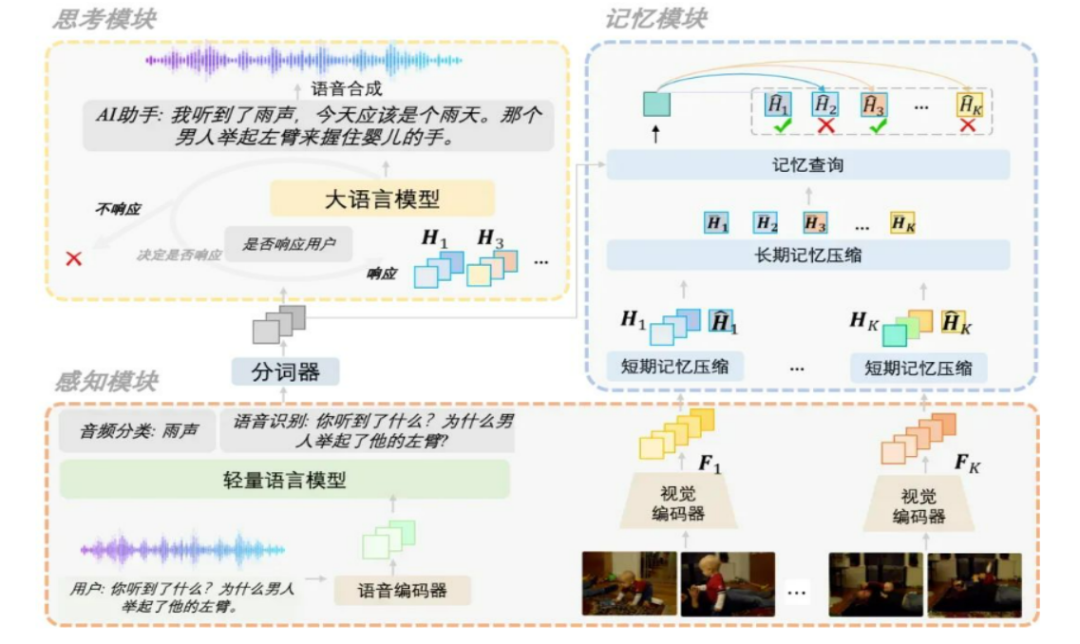
二、技术架构
1、输入层
在输入层,模型对流式视频数据和音频数据进行专门的处理。对于流式视频数据,会进行高效的解码与初步特征提取,将视频帧转化为模型能够理解的格式,并提取如颜色、纹理、形状等基础特征。音频数据则经过采样、滤波等处理步骤,去除噪声干扰并提取音频的关键特征,如频率、振幅等,为后续的感知模块提供高质量的数据输入。
2、流式感知模块
视频感知模块采用了CLIP – L/14技术,该技术能够对视频中的图像序列进行深度理解。通过预训练的模型权重,它可以快速识别视频中的物体、场景、人物动作等信息,并将这些信息编码为语义特征向量。音频感知模块则有着一套严谨的处理流程,首先对音频进行分帧处理,然后利用声学模型对每帧音频进行分析,识别其中的语音内容、声音类型(如音乐、环境音效等),并将音频信息转换为与视频信息相对应的语义表示,以便在后续模块中实现多模态信息的融合与交互。
3、记忆模块
感知数据会被写入记忆池,在记忆池中,数据以一种结构化的方式进行存储。当需要进行检索生成时,模型会根据当前的任务需求和输入信息,在记忆池中快速查找相关的历史数据。
例如,在多轮对话中,如果涉及到之前提到的图像或视频内容,记忆模块能够迅速定位并提取相关信息,为生成准确的回答提供有力支持。
4、推理模块
推理模块从记忆池检索记忆,并在此基础上进行复杂的推理过程。它结合了多种推理算法和神经网络结构,能够对多模态信息进行综合分析。
例如,在视频理解任务中,推理模块可以根据视频感知模块提供的图像信息、记忆模块中的相关历史信息以及音频感知模块的声音信息,推断出视频中的事件发展逻辑、人物关系等,并根据推理结果进行相应的回答生成或任务执行,如生成视频的文字描述、回答关于视频内容的问题等。
三. 核心功能
1、超高分辨率理解
InternLM-XComposer-2.5-OmniLive能够支持超高分辨率图像的理解。在处理高分辨率图像时,模型采用了分层处理的策略。首先对图像进行整体的感知与特征提取,确定图像的大致场景和主要元素分布。然后,针对图像中的关键区域进行精细化处理,利用深度学习算法对细节进行深入分析,如识别高分辨率图像中的微小物体、精细纹理等,从而实现对整个超高分辨率图像的全面、精准理解,无论是用于图像分析、艺术创作还是工业检测等领域,都能提供有力的支持。
2、多轮多图像对话
该模型具备强大的支持自由形式多轮多图像对话的能力。在多轮对话过程中,模型能够记住之前对话轮次中的图像信息以及相关的讨论内容。
3、视频理解与网页制作
在视频理解方面,模型可以对视频的内容、情节、人物行为等进行全面的分析和理解。通过对视频帧序列的处理,提取关键帧和关键事件,构建视频的语义框架。基于这种视频理解能力,模型还能够进行网页制作和文章创作。
四、性能评测
InternLM-XComposer-2.5-OmniLive在 28 个基准测试中展现出了卓越的性能。尤其在 16 个基准测试中优于现有的开源模型。在图像理解基准测试中,其准确率和召回率均处于领先水平,能够更精准地识别图像中的各种元素和场景;在视频理解相关的基准测试里,对于视频内容的分析、事件的预测等任务,也表现出更高的准确性和效率。
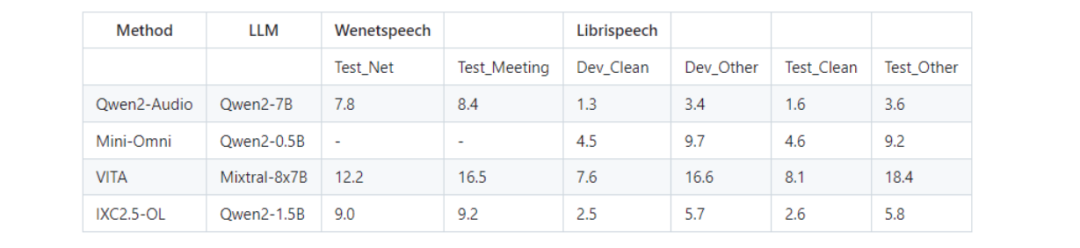
1、语音识别性能
在 WenetSpeech 和 LibriSpeech 基准测试如下:
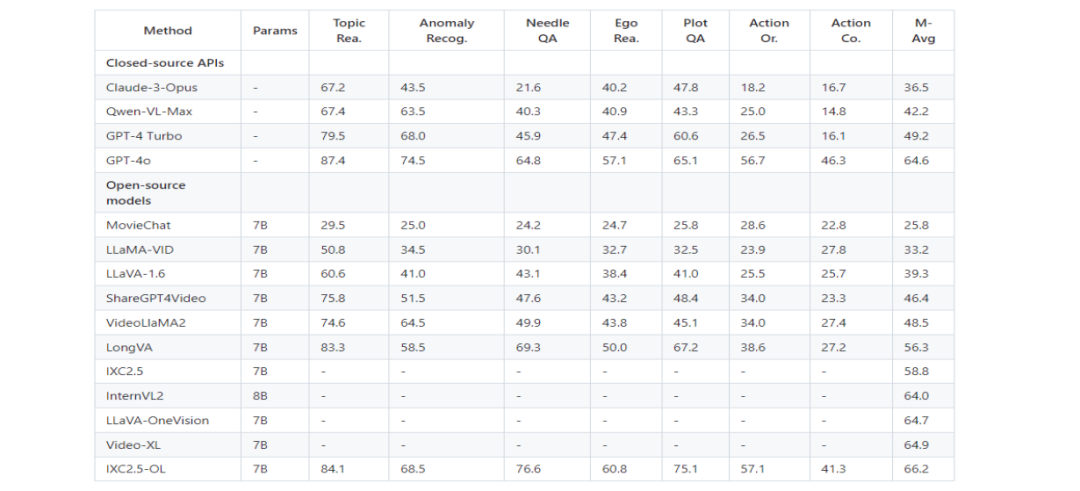
2、视频理解性能
在 MLVU 基准测试上如下:
五、部署实践
1、环境准备
-
确保你的开发环境中安装了Python和必要的依赖库:
-
npython 3.8及以上版本
-
npytorch 1.12及以上版本,推荐2.0及以上版本
-
n推荐使用CUDA 11.4及以上版本(针对GPU用户)
-
nInternLM-XComposer2.5 的高分辨率使用需要 flash-attention2。
2、安装依赖
Step 1. 创建一个 conda 环境并激活。
conda create -n intern_clean python=3.9 -yconda activate intern_clean
Step 2. 安装 PyTorch (我们使用 PyTorch 2.0.1 / CUDA 11.7 测试通过)
pip3 install torch torchvision torchaudio# 推荐使用以下命令安装Pytorch,以准确复现结果:
Step 3. 安装需要的包
pip install transformers==4.30.2 timm==0.4.12 sentencepiece==0.1.99 gradio==3.44.4 markdown2==2.4.10 xlsxwriter==3.1.2 einops3、下载模型
使用 modelscope 中的 snapshot_download 函数下载模型(提前安装modelscope :pip install modelscope)。第一个参数为模型名称,参数 cache_dir 用于指定模型的下载路径。在 /root/autodl-tmp 路径下新建 download.py 文件,并在其中输入以下内容:
from modelscope import snapshot_downloadmodel_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b', cache_dir='/root/autodl-tmp', revision='master')
4、声音理解代码示例
使用ms-swift进行推理,提前安装ms-swift(pip install git+https://github.com/modelscope/ms-swift.git)
import osos.environ['USE_HF'] = 'True'import torchfrom swift.llm import (get_model_tokenizer, get_template, ModelType,get_default_template_type, inference)from swift.utils import seed_everythingmodel_type = ModelType.qwen2_audio_7b_instructmodel_id_or_path = 'internlm/internlm-xcomposer2d5-ol-7b'template_type = get_default_template_type(model_type)print(f'template_type: {template_type}')model, tokenizer = get_model_tokenizer(model_type, torch.float16, model_id_or_path=model_id_or_path, model_dir='audio',model_kwargs={'device_map': 'cuda:0'})model.generation_config.max_new_tokens = 256template = get_template(template_type, tokenizer)seed_everything(42)# Chinese ASRquery = '<audio>Detect the language and recognize the speech.'response, _ = inference(model, template, query, audios='examples/audios/chinese.mp3')print(f'query: {query}')print(f'response: {response}')
5、图片理解代码示例
import torchfrom transformers import AutoModel, AutoTokenizertorch.set_grad_enabled(False)# init model and tokenizermodel = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-ol-7b', model_dir='base', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-ol-7b', model_dir='base', trust_remote_code=True)model.tokenizer = tokenizerquery = 'Analyze the given image in a detail manner'image = ['examples/images/dubai.png']with torch.autocast(device_type='cuda', dtype=torch.float16):response, _ = model.chat(tokenizer, query, image, do_sample=False, num_beams=3, use_meta=True)print(response)
6、命令部署推理示例
# 克隆仓库代码git clone https://github.com/InternLM/InternLM-XComposer.gitcd InternLM-XComposer/InternLM-XComposer-2.5-OmniLive# 音频模型推理python examples/infer_audio.py# 基础模型推理python examples/infer_llm_base.py# 带记忆的模型推理python examples/merge_lora.pypython examples/infer_llm_with_memory.py
六、应用场景
1、在AI眼镜领域,InternLM-XComposer-2.5-OmniLive可以为用户提供实时的视觉和听觉辅助。例如,当用户看到一个陌生的物体或场景时,通过AI眼镜的摄像头获取图像信息,模型可以实时识别并提供相关的文字说明或语音讲解;同时,对于周围的环境声音,也能进行分析并给予用户提示,如识别出紧急的警报声并提醒用户注意安全。
2、在机器人领域,机器人可以利用该模型实现更加智能的人机交互。在家庭服务机器人中,能够理解主人的语音指令以及周围环境的视觉信息,如根据主人的要求找到特定的物品、识别家庭成员的面孔并进行个性化的互动;在工业机器人中,可以对生产线上的产品进行视觉检测,同时结合语音指令进行操作控制,提高生产效率和质量控制水平。
3、对于手机AI视觉,用户可以在拍摄照片或视频时,借助模型实现实时的图像优化、场景识别与标注。例如,在拍摄风景照时,模型可以自动调整相机参数以获得更好的拍摄效果,并为照片添加地理位置、景点名称等标注;在拍摄视频时,能够对视频内容进行实时分析,提供拍摄建议,如调整拍摄角度、捕捉关键瞬间等,还可以在拍摄后快速生成视频的文字描述或制作成简单的网页分享。
七、结语
InternLM-XComposer-2.5-OmniLive具有诸多显著优势,其先进的技术架构实现了高效的多模态信息融合与交互,强大的核心功能满足了多种复杂任务的需求,优秀的性能评测结果证明了其在多模态大模型领域的竞争力,丰富的开源资源和实用的实践教程促进了社区的发展与应用的推广。
八、项目相关资料
-
模型地址:https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b
-
代码仓库:https://github.com/InternLM/InternLM-XComposer/blob/main/InternLM-XComposer-2.5-OmniLive
-
技术报告:https://github.com/InternLM/InternLM-XComposer/blob/main/InternLM-XComposer-2.5-OmniLive/IXC2.5-OL.pdf
(文:小兵的AI视界)