
虽然大多数人天生就能用双手与他人交流或抓取和操纵物体,但许多现有的机器人系统只擅长简单的手动任务。近年来,世界各地的计算机科学家一直在开发基于机器学习的模型,这些模型可以处理人类完成手动任务的图像,利用获取的信息来改进机器人的操控能力,从而增强机器人与周围人类和物体的互动。

近日Meta元宇宙业务部门Reality Labs的研究人员最近推出了 HOT3D数据集,能够帮助加速机器学习研究以分析手与物体的交互。该数据集在arXiv预印本服务器上发表的一篇论文中提出,包含以自我为中心的高质量 3D 视频,包含以第一人称视角的用户抓取和操纵各种物体。
▍HOT3D数据集采集、注释与构建详解
HOT3D数据集是一个公开的、用于第一人称视角(egocentric)手与物体3D跟踪的数据集。
它提供了超过833分钟(超过370万张图像)的多视角RGB/单色图像流,展示了19名受试者与33种不同刚性物体的交互,以及多模态信号,如眼动跟踪或场景点云,还有全面的真实值注释,包括物体、手和相机的3D姿态,以及手和物体的3D模型。

除了简单的拿起/观察/放下动作外,HOT3D还包含了类似厨房、办公室和客厅环境中典型动作的场景。
数据采集设备:
HOT3D数据集由Meta的两款头戴设备录制:Project Aria和Quest 3。Project Aria是一款轻量级AR/AI眼镜的研究原型,而Quest 3是一款已售出数百万台的VR头显。


Project Aria:具有一个滚动快门RGB相机(1408×1408分辨率,30fps),两个全局快门单色相机(640×480分辨率,30fps),两个单色眼动跟踪相机(320×240分辨率,10fps),两个IMU(800Hz和1000Hz),一个气压计(50fps)和一个磁力计(10fps)。此外,还提供了SLAM生成的3D点云和眼动跟踪信息。

Quest 3:使用了两个前置的全局快门单色相机(1280×1024分辨率,30fps),用于录制相关场景。
数据内容与注释:
图像与视频:数据集包含超过370万张图像,分为RGB和单色图像流。每个Aria帧由一个RGB图像和两个单色图像组成,而每个Quest 3帧由两个单色图像组成。所有流都是硬件触发同步的,即在同一时间戳捕获。
真实值注释:包括手和物体的3D姿态,物体由带有物理基渲染(PBR)材料的3D网格表示,手和物体的注释分别使用UmeTrack和MANO格式。
物体模型:提供了33个物体的3D网格模型,这些模型通过内部扫描的3D物体重建管道获得,包括高分辨率几何形状和PBR材料。
场景多样性:除了简单的检查场景外,还包含了厨房、办公室和客厅中的典型动作场景。为了增加多样性,捕捉实验室中的照明、家具和装饰物被定期随机化。
数据集结构与划分
训练集与测试集:训练集包含13名受试者的记录(100万张多视角帧),测试集包含剩余6名受试者的记录(50万张多视角帧)。真实值注释仅对训练集公开,测试集的真实值注释只能通过专用的评估服务器访问。

精选片段:为了促进各种跟踪和姿态估计方法的基准测试,还发布了从完整记录中提取的3832个精选片段,每个片段有150帧(5秒),所有建模的物体和手的真实值注释都可用,并通过了视觉检查。

物体上板序列:为了基准测试无模型物体跟踪方法和3D物体重建方法,HOT3D还包括两种类型的上板序列,展示了每个物体的所有可能视图:(1)物体静止在桌面上的序列,物体直立和倒立;(2)物体被手操作的序列。静态上板设置适合NeRF类重建方法,而后者更适合AR/VR应用,但更具挑战性。
▍HOT3D数据集的应用与实验
HOT3D数据集主要用于训练和评估第一人称视角的3D手与物体跟踪方法。通过四项实验,验证了多视角数据在手与物体交互任务中的有效性。
1.3D手姿态跟踪
实验比较了UmeTrack手跟踪器在单视角和多视角模式下的性能。使用三种训练数据变体:(1)UmeTrack数据集的训练序列;(2)HOT3D的Quest 3训练序列;(3)两者的组合。在UmeTrack和HOT3D测试集上评估了模型。
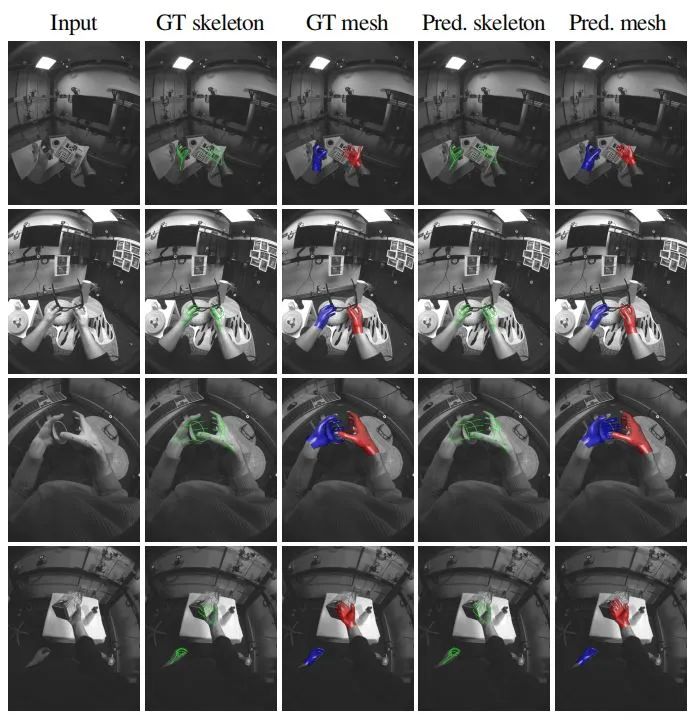
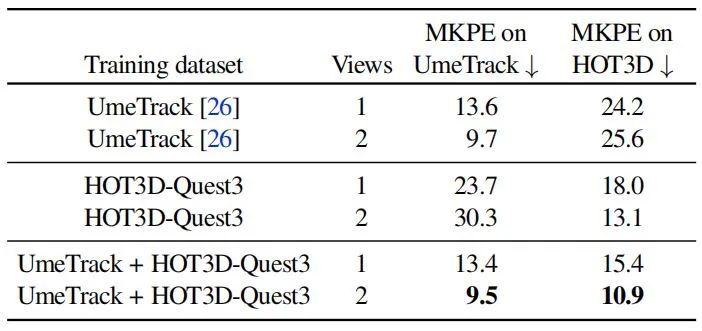
结果显示,当仅在UmeTrack数据集上训练时,UmeTrack跟踪器在HOT3D上的性能较差,尤其是在包含手与物体交互的帧上。反之亦然。当在两个数据集上训练时,域差距被有效缩小,单视角模式下的性能得到提升。使用双视角输入时,性能显著提高,平均关键点位置误差(MPKE)降低了41%。
2.6DoF未知物体姿态估计
实验关注于基于CAD模型的未知物体6DoF姿态估计任务。评估了原始FoundPose方法及其扩展到多视角输入的性能。FoundPose方法通过渲染RGB-D模板,从RGB通道中提取DINOv2补丁特征,并使用深度通道在3D中注册这些特征。

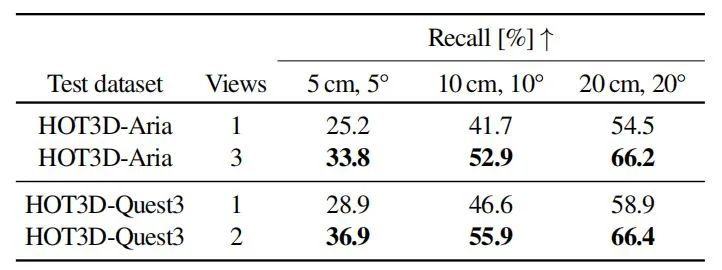
在推理时,从图像裁剪中提取特征,并与模板建立2D-3D对应关系,通过PnP-RANSAC生成姿态假设。多视角扩展版本在推理时从所有可用视图中裁剪物体,检索具有最高相似度总和的模板,并建立多视角2D-3D对应关系。结果显示,多视角扩展版本显著优于单视角版本,在Aria和Quest 3数据上的召回率提高了8-12%。
3. 手中物体2D分割
给定输入图像,任务是预测手中物体的二值2D掩码。评估了三种方法,包括现成的EgoHOS模型和两种基于Mask R-CNN的变体。

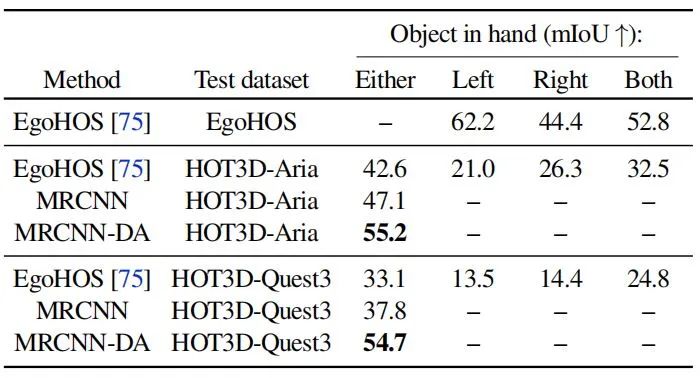
结果显示,EgoHOS模型在HOT3D数据集上的性能相比其在EgoHOS数据集上的性能有所下降,这归因于训练数据集之间的域差距。基于Mask R-CNN并使用预测的深度图的方法(MRCNN-DA)表现最佳,在Aria和Quest 3帧上分别比EgoHOS高出30%和65%的mIoU。
4. 手中物体3D提升
任务是估计手中未知物体的3D位置。研究团队开发了三种方法:(1)使用手的3D掌心作为物体位置(HandProxy);(2)通过单目深度估计提升(MonoDepth);(3)通过立体匹配提升(StereoMatch)。

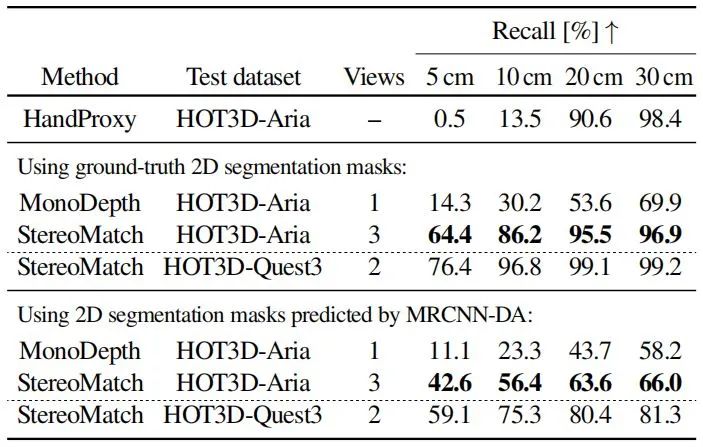
结果显示,StereoMatch方法在更严格的阈值水平上明显优于其他两种方法,尤其是在Quest 3数据上。
▍ HOT3D数据集与其他数据集的比较
HOT3D数据集与其他数据集(如ARTIC、HOI4D、DexYCB等)相比,HOT3D在图像数量、真实值注释质量和场景多样性方面均表现出色。需要特别注意的是,HOT3D是首个提供多视角、硬件时间同步的以自我为中心的视频数据集,这一特性得益于其使用真实的头戴设备(如Meta的Project Aria和Quest 3)进行录制,从而能够捕获更加自然和真实的交互场景。
另外,HOT3D数据集包含了超过833分钟的多视角RGB/单色图像流,总计超过370万张图像,远超同类数据集。庞大的数据量,为手与物体交互研究提供了充足的训练素材,有助于开发更加鲁棒和准确的算法模型。
需要补充的是,HOT3D数据集不仅提供了高精度的手和物体3D姿态注释,还包含了详细的3D物体模型和材质信息,支持物理基渲染。同时还融合了多种模态信号,如眼动追踪信息和3D点云。这些额外信息不仅丰富了数据集的内容,还为研究者提供了更全面的视角来理解手与物体的交互过程。
▍ 结语与未来:
Meta Reality Labs开发的HOT3D数据集为手与物体交互研究提供了高质量、多视角的3D数据支持,极大地丰富了该领域的研究资源。这一数据集不仅促进了计算机视觉和机器人技术的发展,还为AR/VR等前沿应用提供了更为自然和真实的交互体验基础。它的出现,为研究人员深入理解人类操作行为、开发智能交互系统提供了有力支撑,推动相关领域的科技创新和实际应用取得更大突破。
论文下载:https://arxiv.org/pdf/2411.19167
开源地址:https://facebookresearch.github.io/hot3d/
来源:具身智能大讲堂
(文:机器人大讲堂)