

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
在医学领域涉及大量复杂的推理过程,从症状分析到疾病诊断,每一步都需要综合考虑众多因素。例如,在诊断一种罕见疾病时,医生不仅要熟悉各种疾病的症状表现,还要了解患者的病史、家族遗传史、生活环境等多方面信息,通过层层推理才能做出准确的判断。
为了辅助医生实现更高效的推理,香港中文大学(深圳)和深圳市大数据研究院联合开源了专用于医疗领域的复杂大模型——华佗GPT-o1。

开源地址:https://huggingface.co/FreedomIntelligence/HuatuoGPT-o1-7B
Github:https://github.com/FreedomIntelligence/HuatuoGPT-o1
高质量医学数据集
开发高质量可验证医学数据集是华佗GPT-o1实现高质量推理的重要基石,研究人员从MedQA-USMLE和MedMCQA训练集中精心收集了192K医学多项选择题。
涵盖了内科学、外科学、妇产科学、儿科学、神经病学等众多医学学科的知识点,能全面地反映了医学领域的知识体系。
但原始数据存在诸多问题,需要进行严格筛选。首先,许多题目过于简单,无法有效训练模型的复杂推理能力。例如,一些题目仅考查单一知识点,且答案一目了然,对于模型来说缺乏挑战性。其次,部分题目答案不唯一或存在歧义,这会给模型的学习和验证带来困扰。此外,一些题目不适合转化为开放式问题,不利于模型进行深入推理。
为了筛选出合适的题目,研究人员采用了多轮筛选方法。第一轮,利用小型语言模型对题目进行初步筛选,去除那些所有小型模型都能轻易回答正确的简单题目。第二轮,由人工对剩余题目进行审核,排除答案不明确或存在歧义的题目。
最后,借助GPT-4o模型对筛选后的题目进行进一步优化和验证,确保每个题目都具有明确的、唯一的正确答案,并且能够转化为开放式问题。经过层层筛选,最终得到了一个包含40K可验证医学问题的数据集。
两阶段训练模式
在第一阶段,华佗GPT-o1首先会对给定的可验证医学问题进行初步分析,生成一个初始的思维链(CoT)和答案。例如,对于一个关于患者症状分析的问题,模型可能会根据症状的表现、出现的时间顺序、伴随症状等因素,初步推测可能的疾病范围,并给出一个初步诊断。
然后,医学验证器会对这个初始答案进行严格验证。如果答案不正确,模型将启动迭代优化过程。它会从预先设定的四种搜索策略(探索新路径、回溯、验证、修正)中随机选择一种,对之前的推理过程进行改进。
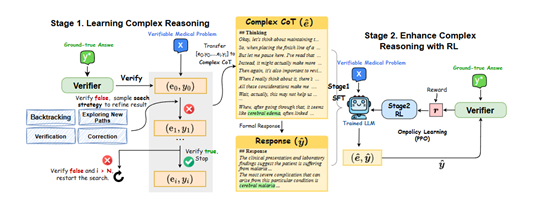
假设模型在诊断过程中忽略了某个重要症状,导致初步诊断错误。如果选择探索新路径策略,模型会尝试从新的角度分析症状,考虑其他可能的疾病因素;如果选择回溯策略,模型会回到之前的推理步骤,重新审视症状与疾病之间的关联;
如果选择验证策略,模型会对当前的推理过程进行再次评估,检查是否存在逻辑漏洞;如果选择修正策略,模型会根据验证器的反馈,纠正之前推理中的错误,调整诊断方向。
模型会不断重复这个过程,直到找到正确的答案。每次迭代都会生成新的CoT和答案,验证器会继续对新答案进行验证,直到答案被确认为正确为止。通过这种方式,模型能够在不断的尝试和改进中,学习到正确的医学推理方法,提高推理的准确性和可靠性。

当模型成功找到正确的推理轨迹后,这个轨迹将被重新格式化为一种更加自然、连贯的复杂CoT形式。例如,原始的推理过程可能是一系列分散的步骤和结论,经过格式化后,会变成一个逻辑清晰、语言流畅的推理叙述,使用自然的过渡词(如“嗯”“而且”“等等”)将各个步骤有机地连接起来,使整个推理过程更加符合人类的思维方式。
在格式化过程中,模型会突出关键的推理步骤和依据,使复杂CoT能够清晰地展示模型的思考过程。然后,模型会根据这个复杂CoT生成一个正式的回答,这个回答不仅包含最终的结论,还会对推理过程进行简要总结,以便更好地与用户进行沟通和解释。
通过构建SFT训练数据,模型能够学习到如何在回答问题之前进行深入的思考和推理,将复杂的医学知识和推理过程整合起来,形成一个完整的解决方案。这种训练方式有助于提高模型在实际应用中的表现,使其能够更好地应对各种复杂的医学问题。
实验数据
为了评估华佗GPT-o1的性能,在MedQA、MMLU-Pro、MedMCQA、PubMedQA等医学基准中进行了综合测试。结果显示,华佗GPT-o1-70B版本超越了其他所有开源模型,在多个数据集上取得了领先成绩。
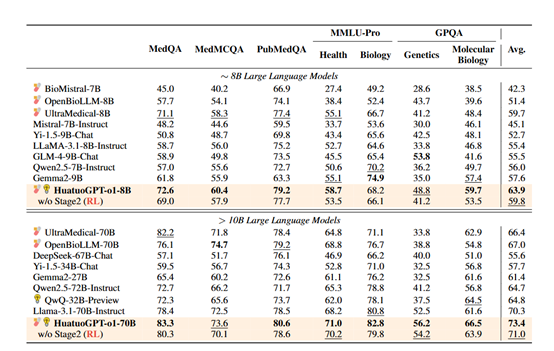
例如,在MMLU-Pro的健康和生物学赛道上,其准确率分别达到了73.6%和71.0%,在GPQA的遗传学和分子生物学赛道上,准确率也分别达到了66.5%和56.2%。
(文:AIGC开放社区)