


“尺度定律”之下,大模型除了要突破算力瓶颈,亦面临高质量数据即将“见底”难题。如何通过“通专融合”技术路径实现通用人工智能,正日益成为业内共识。
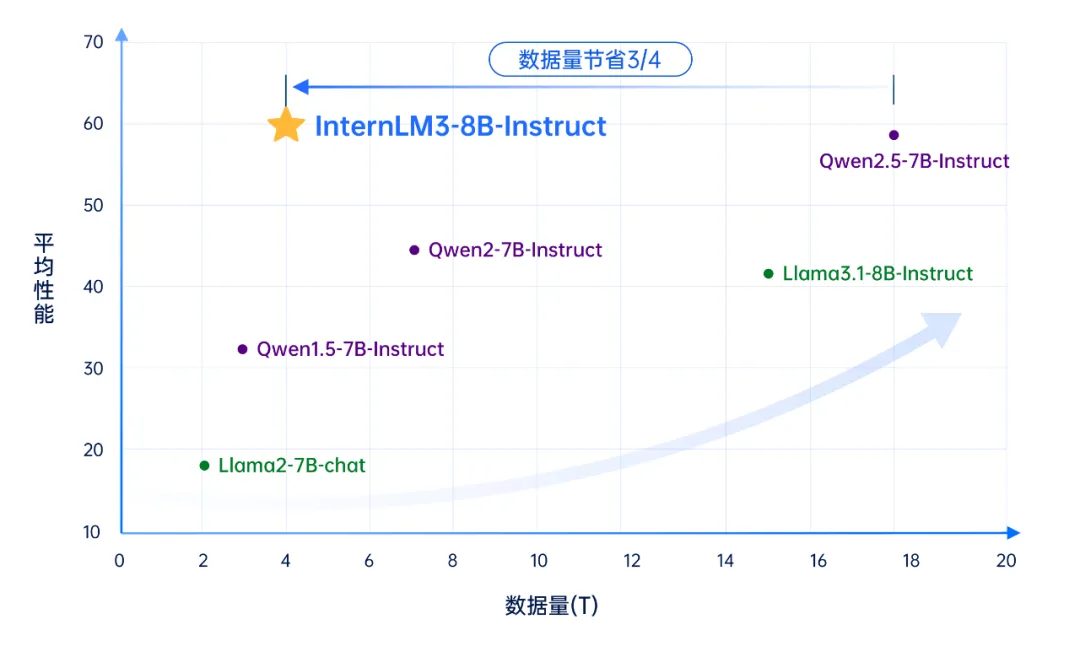
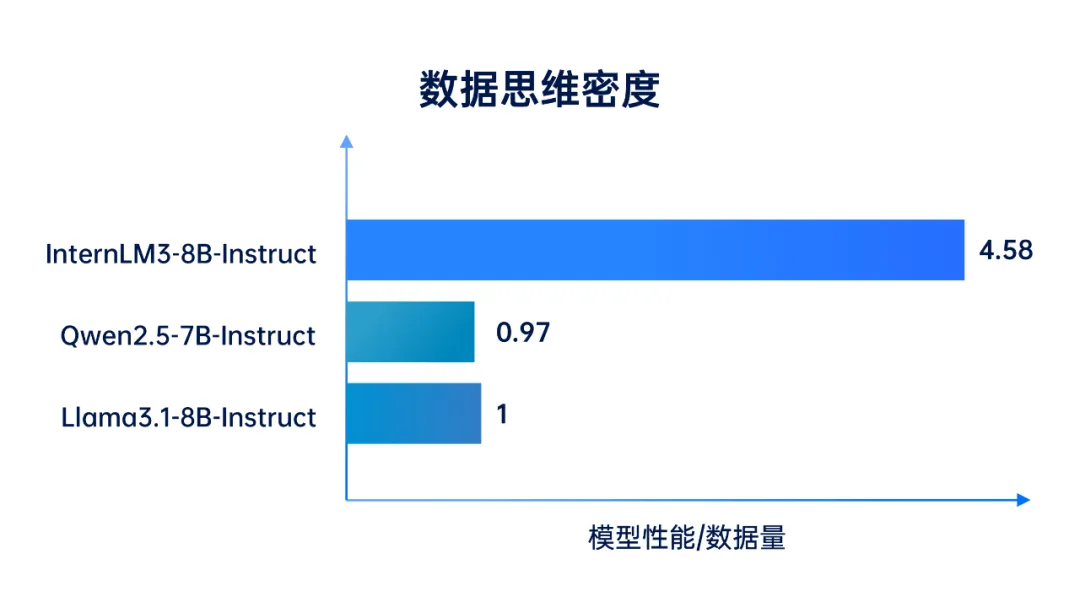
1月15日,上海人工智能实验室对书生大模型进行重要版本升级,书生·浦语3.0(InternLM3)通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8B-Instruct,其综合性能超过了同量级开源模型,节约训练成本75%以上;同时,书生·浦语3.0首次在通用模型中实现了常规对话与深度思考能力融合,可应对更多真实使用场景。

高思维密度带动高性能推理
-
数据处理的智能化:为了实现数据的精细化处理,研究团队将数据分为千万个领域,在此类人力难以负担的规模上,通过智能体自我演进技术,大规模自动化质检,根据错例进行反思,为每个领域进行定制化处理。 -
高价值数据的合成:基于通专融合的方式,以通用模型快速迭代合成算法,再精选数据训练专用模型,通过在海量天然数据中进行素材挖掘,改进的树状搜索策略,以及多维度质量验证,合成大量内容丰富,质量可靠的高价值数据。
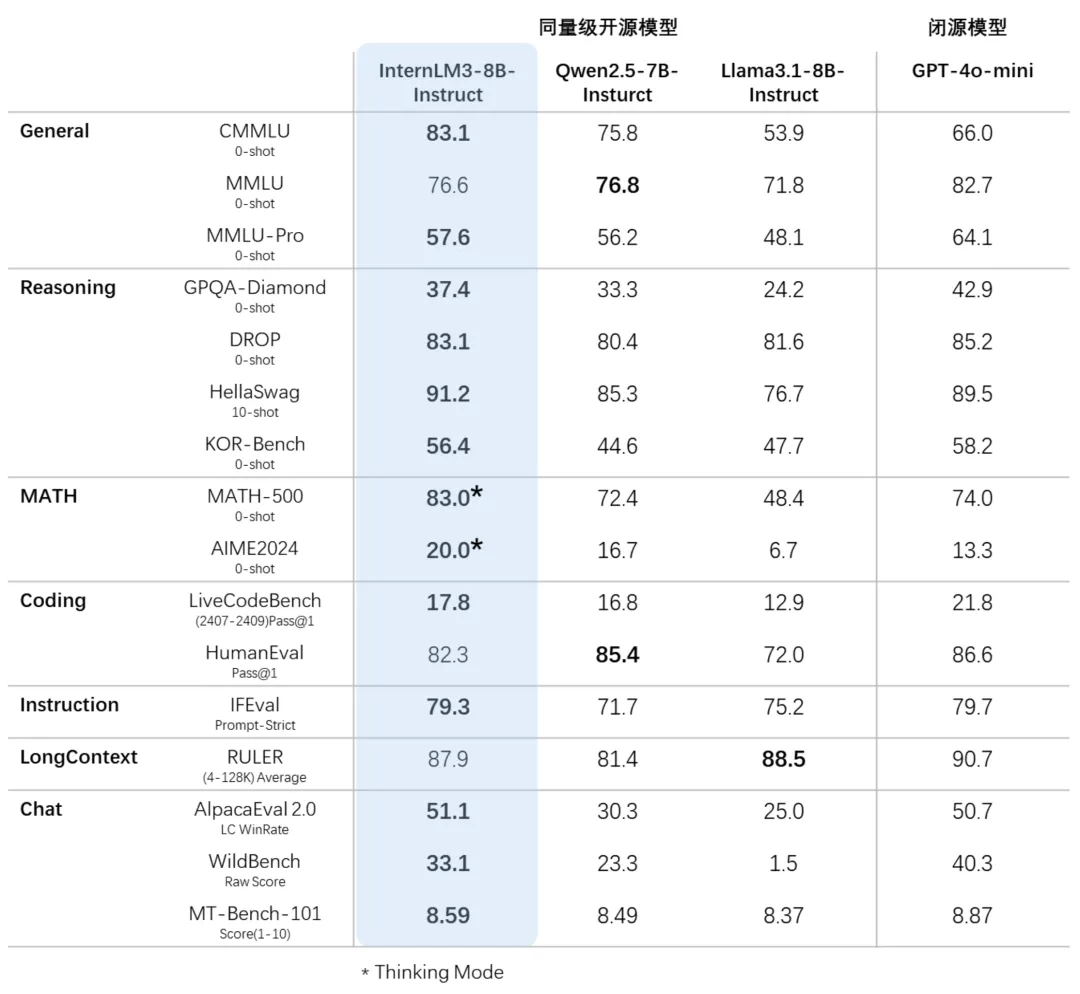
深度思考和常规对话融合,“能言”亦“巧思”

积极拥抱开源社区和国产生态,书生·浦语开箱即用

体验案例展示
书生·浦语3.0可用于解答有趣的推理谜题,在箭头迷宫问题中,让模型在棋盘格中找到从起点到终点的可行路径。这道题目需要空间理解和算法综合应用能力,对于OpenAI o1模型而言也极具挑战。
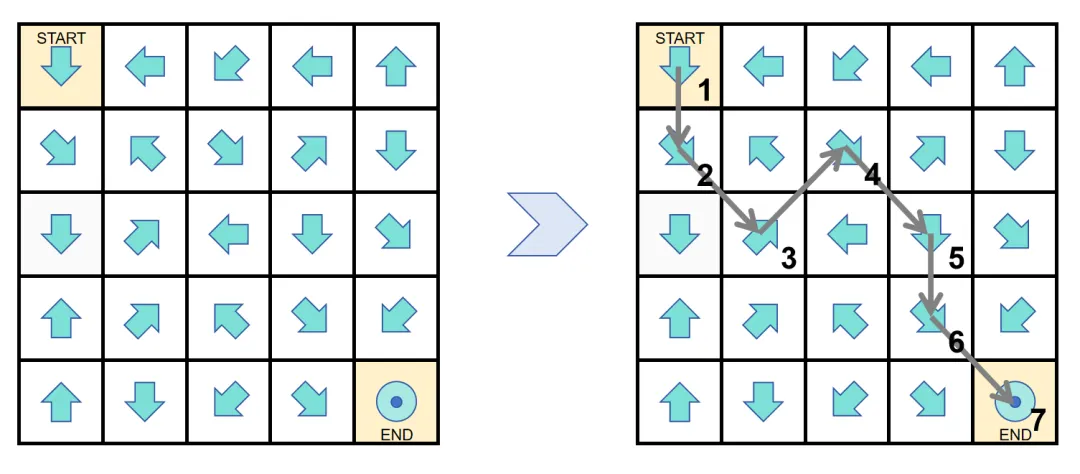
书生·浦语3.0通过深度推理,圆满地找到了可行的路径:

对于经典的猜数字问题,书生·浦语3.0也可轻松应对:

在“高智商”之外,书生·浦语3.0同样拥有“高情商”和优秀创作能力。
书生·浦语3.0也将深度思考能力拓展到了智能体任务,成为了开源社区内首个支持浏览器使用的通用对话模型,支持20步以上网页跳转以完成深度信息挖掘。
如以下视频所示,模型针对买房推荐问题,细致全面地进行分析和规划,在二手房网站上像人一样进行操作和浏览,来找出符合要求的房源。
(文:GiantPandaCV)