

论文链接:
https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
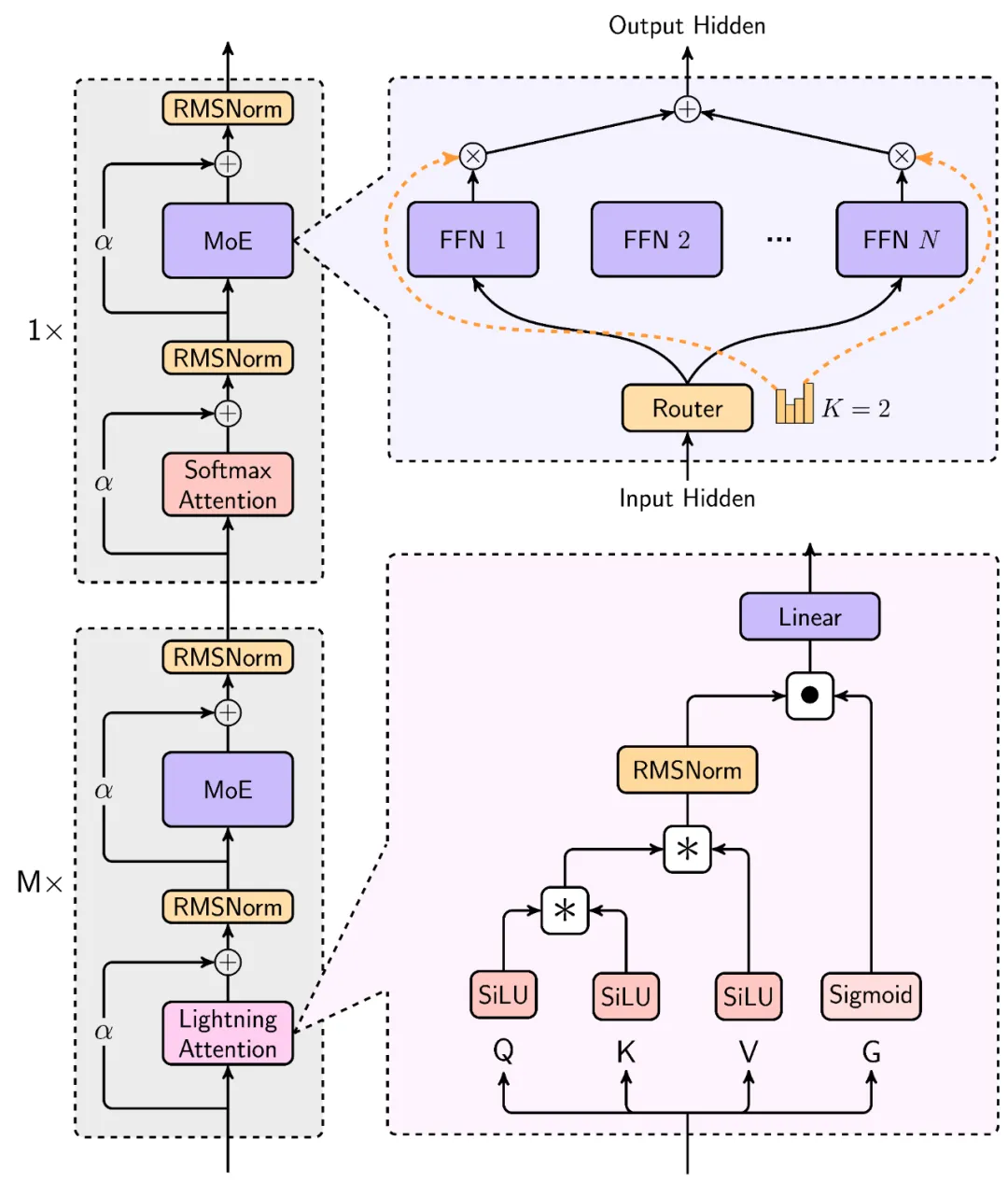
在 MiniMax-01系列模型中,我们做了大胆创新:首次大规模实现线性注意力机制,传统Transformer架构不再是唯一的选择。这个模型的参数量高达4560亿,其中单次激活459亿。模型综合性能比肩海外顶尖模型,同时能够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
我们相信2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent的系统中Agent之间大量的相互通信,都需要越来越长的上下文。在这个模型中,我们走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。
极致性价比、不断创新
受益于架构的创新、效率的优化、集群训推一体的设计以及我们内部大量并发算力复用,我们得以用业内最低的价格区间提供文本和多模态理解的API,标准定价是输入token 1元/百万token,输出token 8元/百万token。欢迎大家在MiniMax开放平台体验、使用。
https://www.minimaxi.com/en/platform
MiniMax 的 Hugging Face 主页:
https://huggingface.co/MiniMaxAI

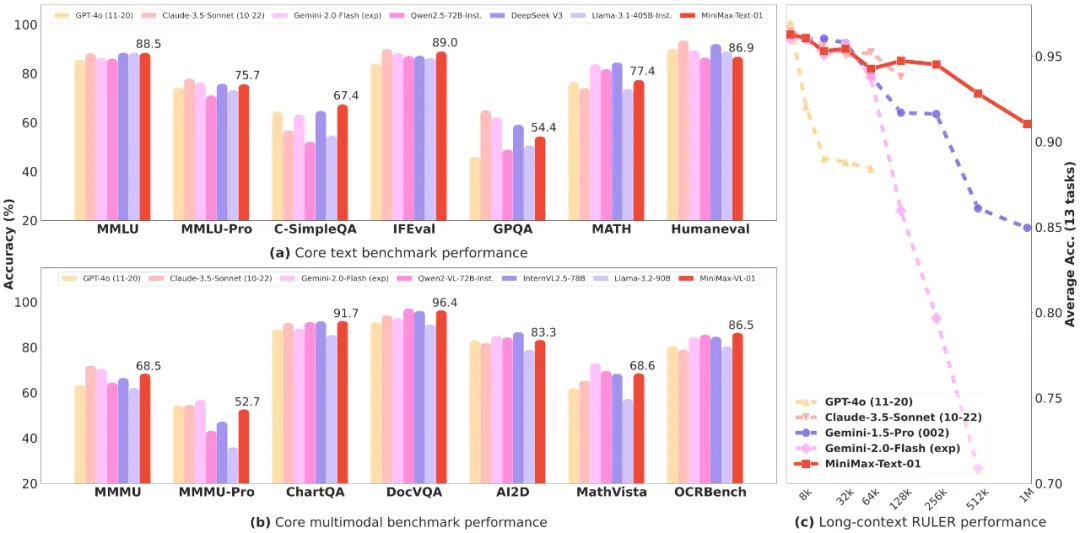
在长文任务上,我们对比了之前长文最好的模型Google的Gemini。如图(c)所示,随着输入长度变长,MiniMax-Text-01是性能衰减最慢的模型,显著优于Google Gemini。
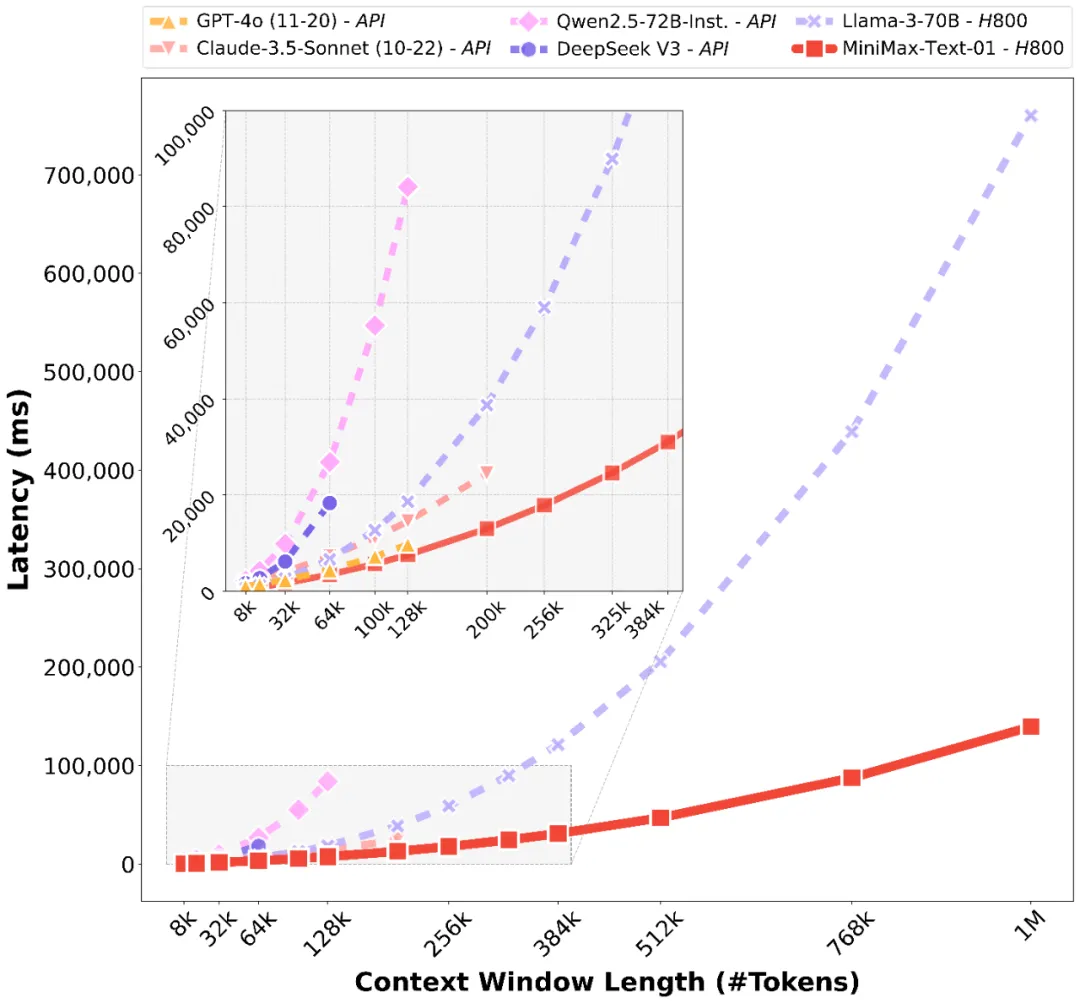
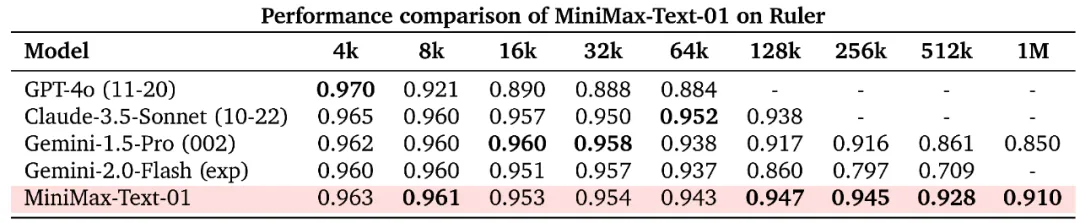
受益于我们的架构创新,我们的模型在处理长输入的时候有非常高的效率,接近线性复杂度。和其他全球顶尖模型的对比如下:
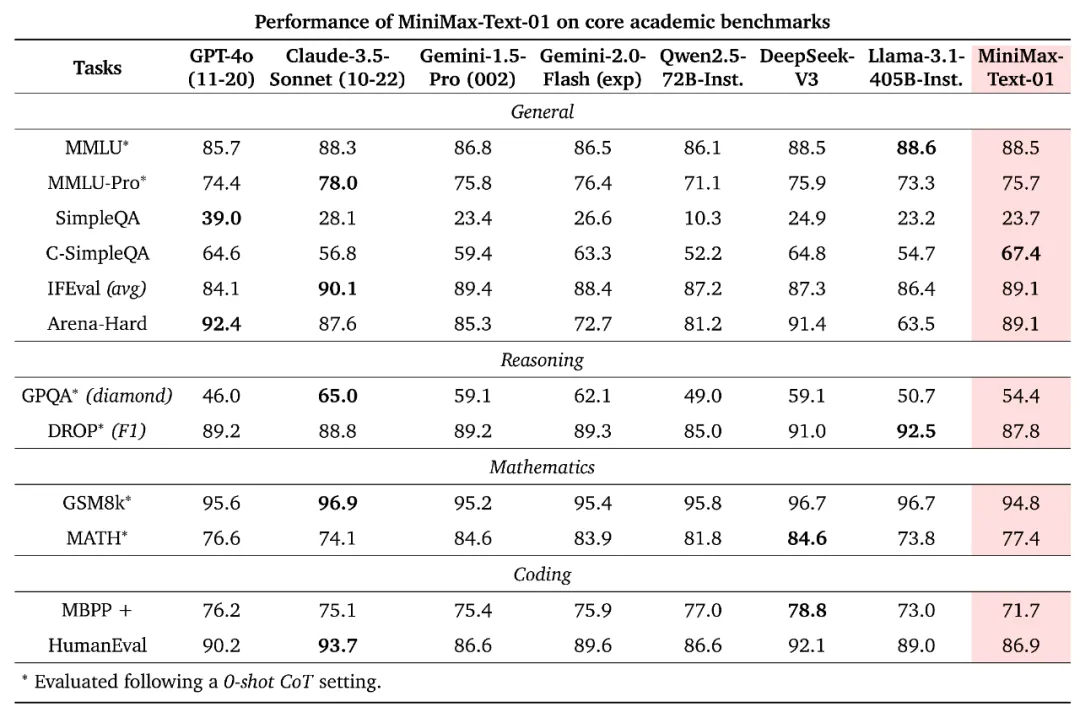
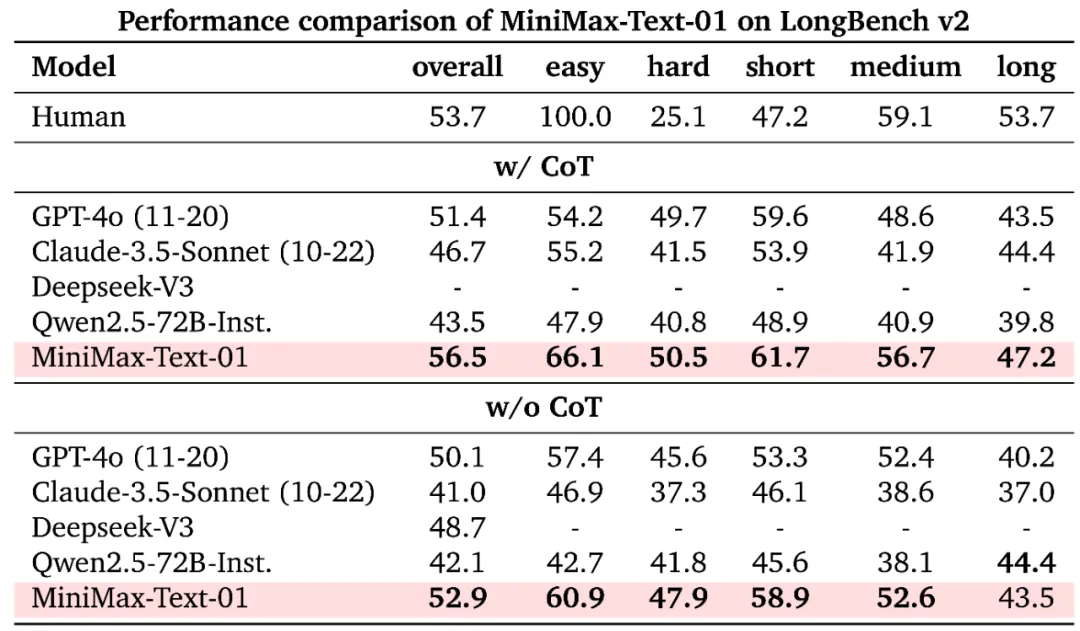
在大部份的学术集上,我们都取得了比肩海外第一梯队的结果:
在长上下文的测评集上,我们显著领先:
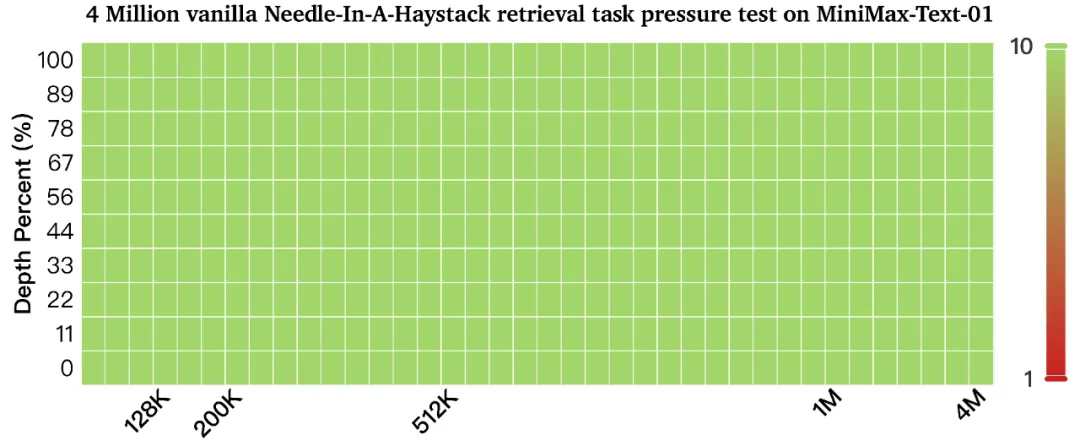
在400万的Needle-In-A-Haystack(大海捞针)检索任务上全绿:
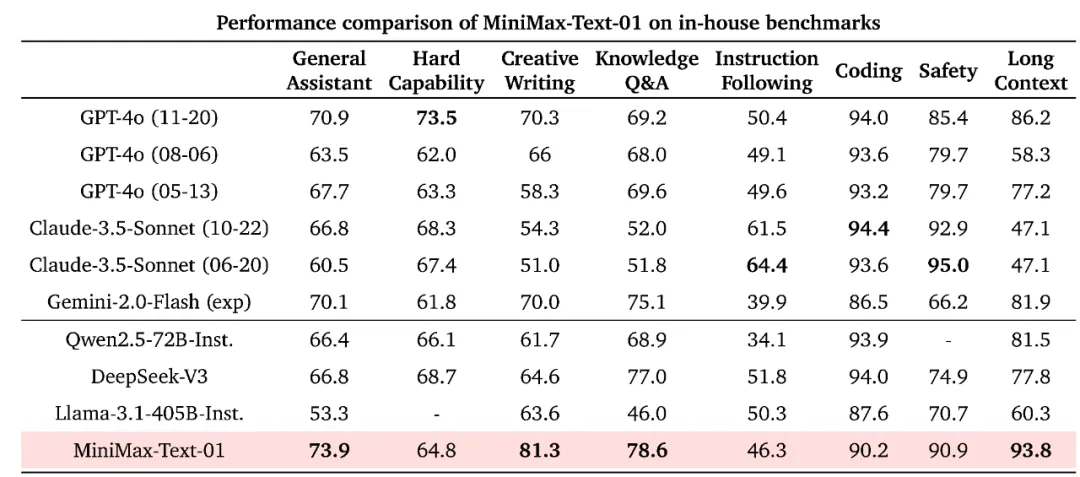
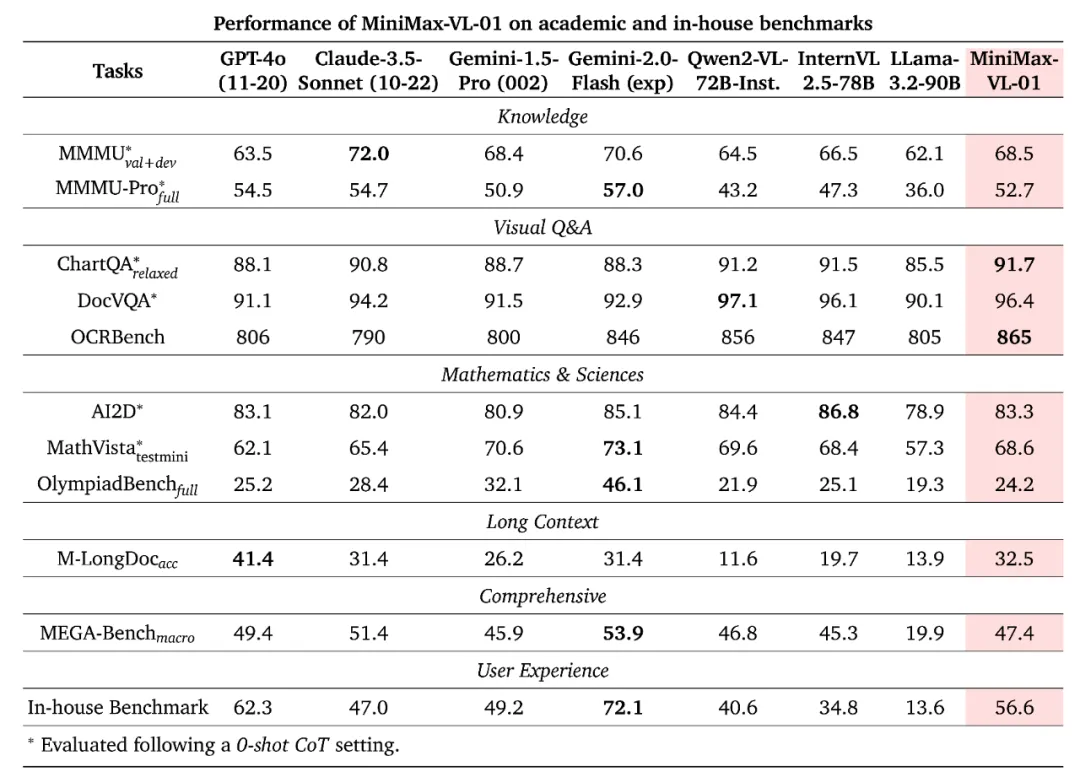
在多模态理解的测试集中,MiniMax-VL-01的模型也较为领先:

欢迎访问 MiniMaxAI 的 Hugging Face 主页
https://huggingface.co/MiniMaxAI
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
https://hf.link/tougao
(文:Hugging Face)