




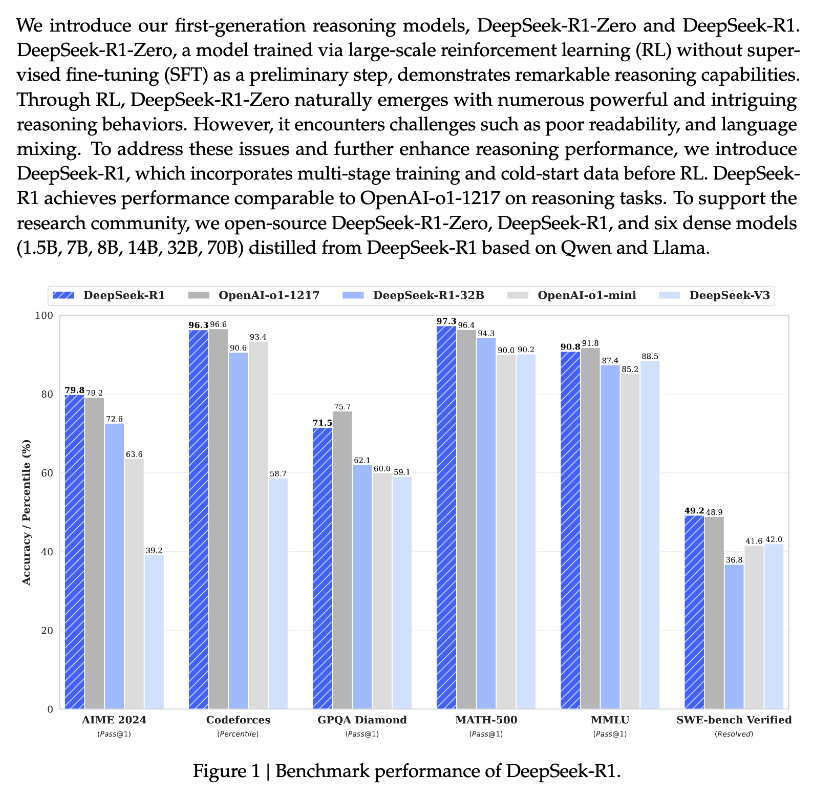
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek\_R1.pdf

https://huggingface.co/deepseek-ai

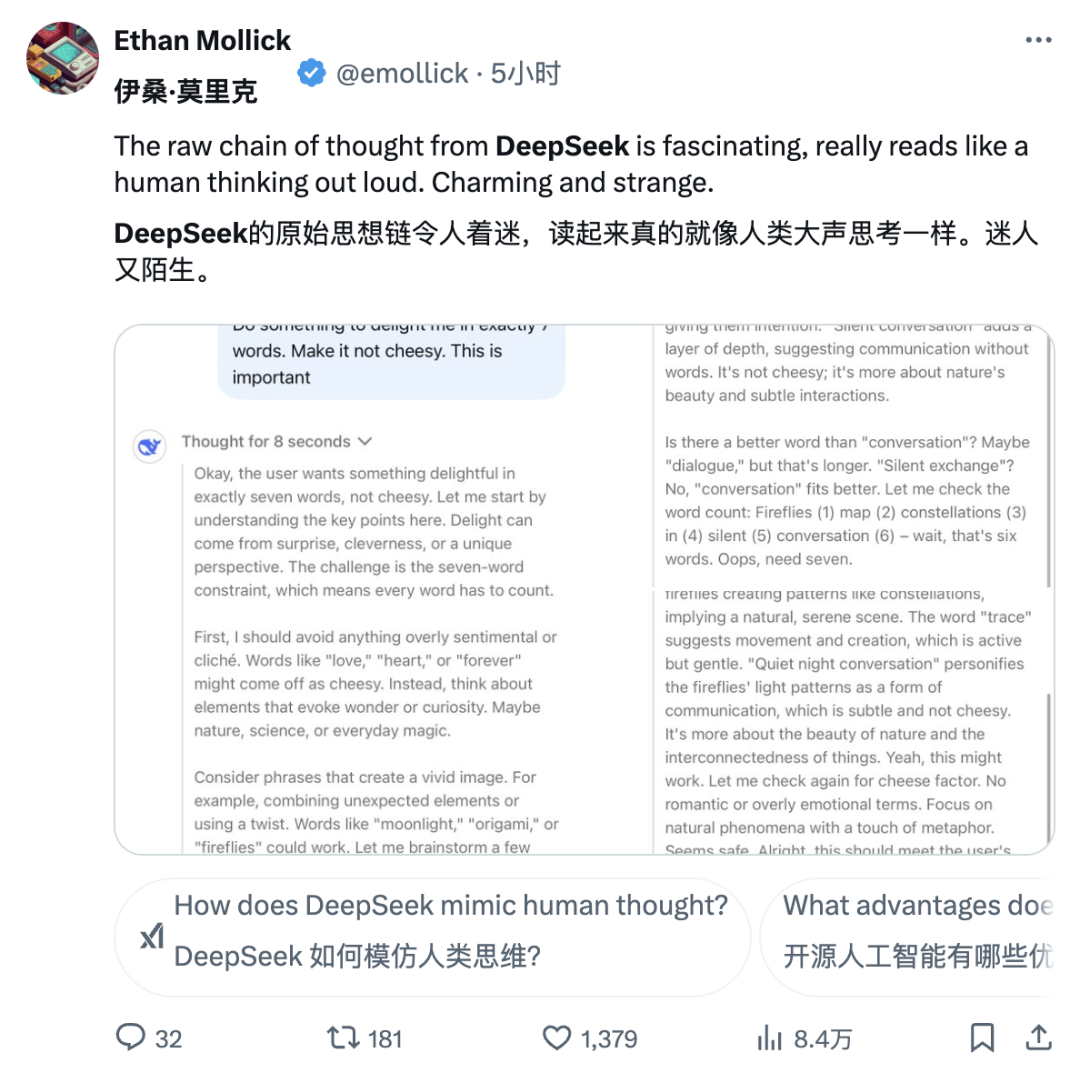
影响力既可以通过『ASI 内部实现』或『草莓计划』等传说般的项目实现,也可以简单地通过公开原始算法和 matplotlib 学习曲线来达成。
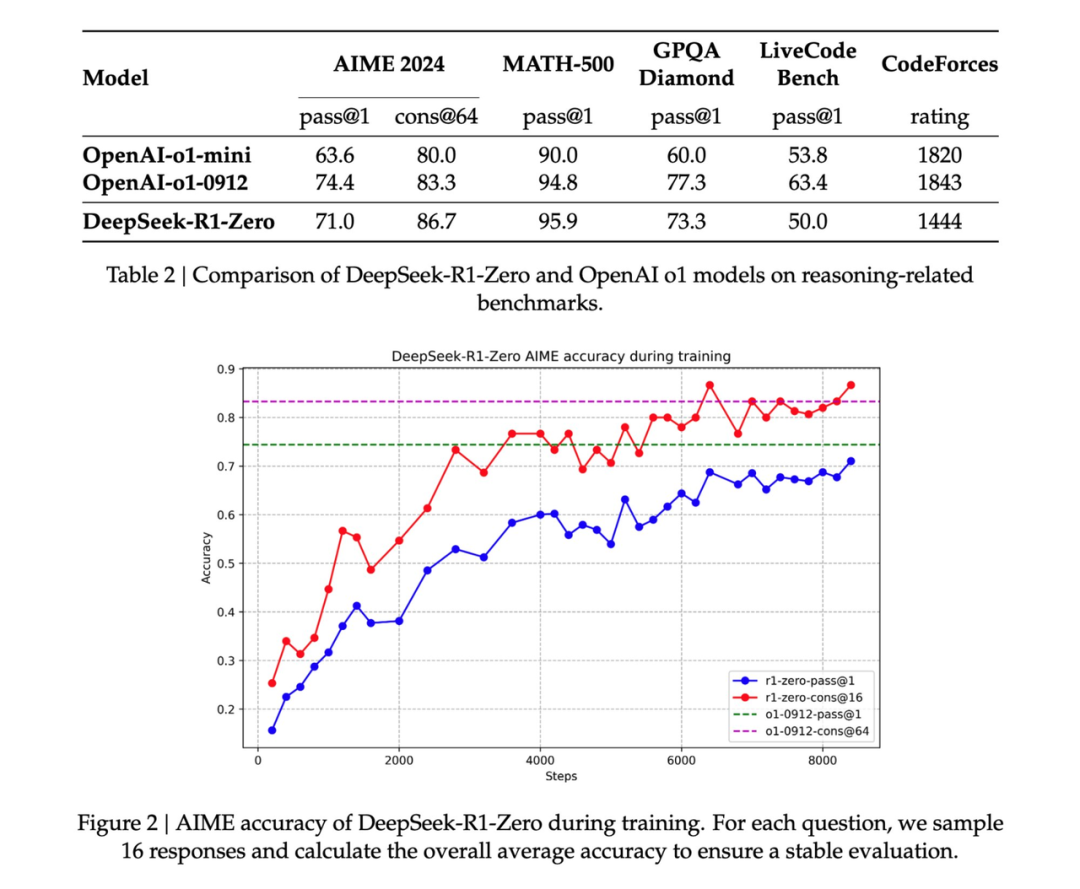
避免使用强化学习容易破解的学习奖励模型。随着训练进展,模型的思考时间逐步增加——这不是预先编写的程序,而是一种涌现特性!自我反思和探索行为的涌现。
GRPO 替代了 PPO:它移除了 PPO 的评论网络,改用多个样本的平均奖励。这是一种减少内存使用的简单方法。需要注意的是,GRPO 是作者团队提出的一种创新方法。
整体来看,这项工作展示了强化学习在大规模场景中实际应用的开创性潜力,并证明某些复杂行为可以通过更简单的算法结构实现,而无需进行繁琐的调整或人工干预。
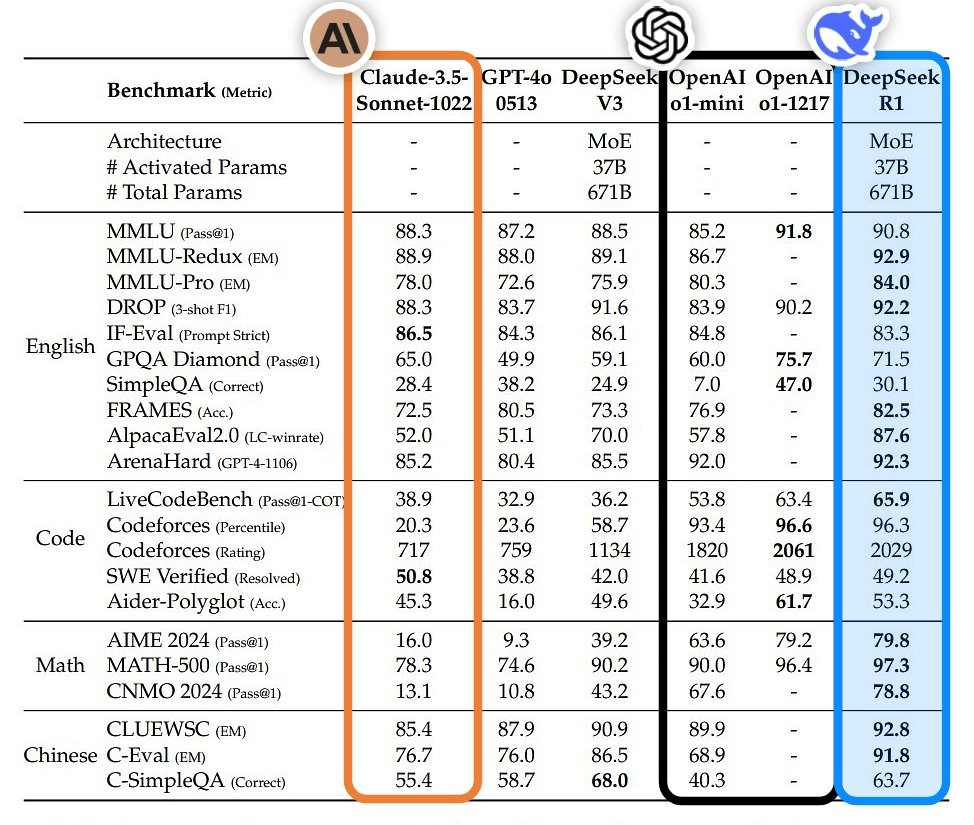
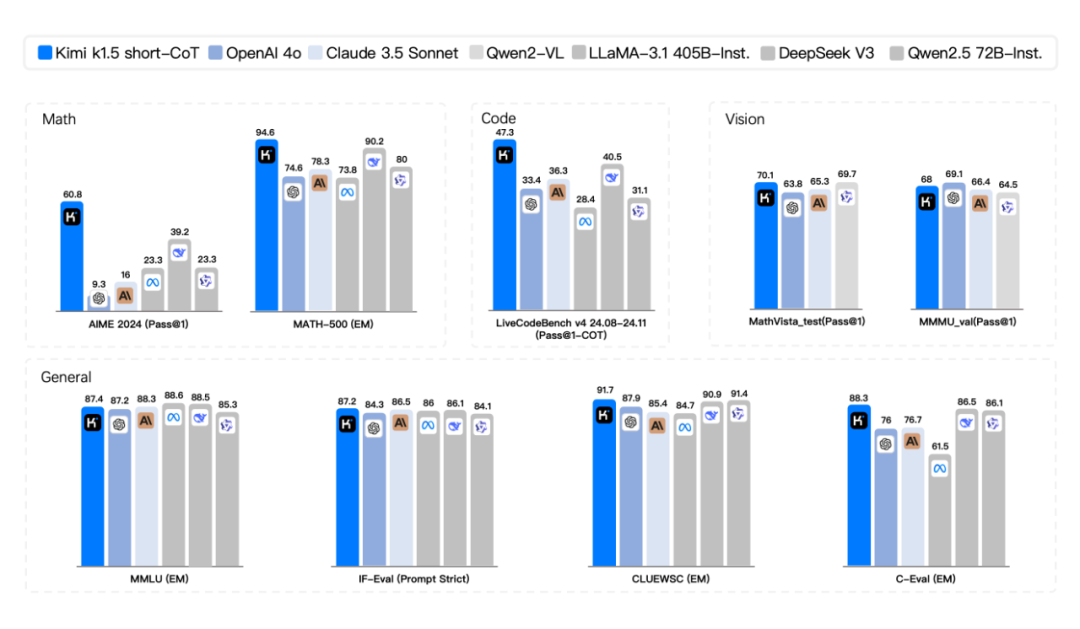
https://github.com/MoonshotAI/kimi-k1.5
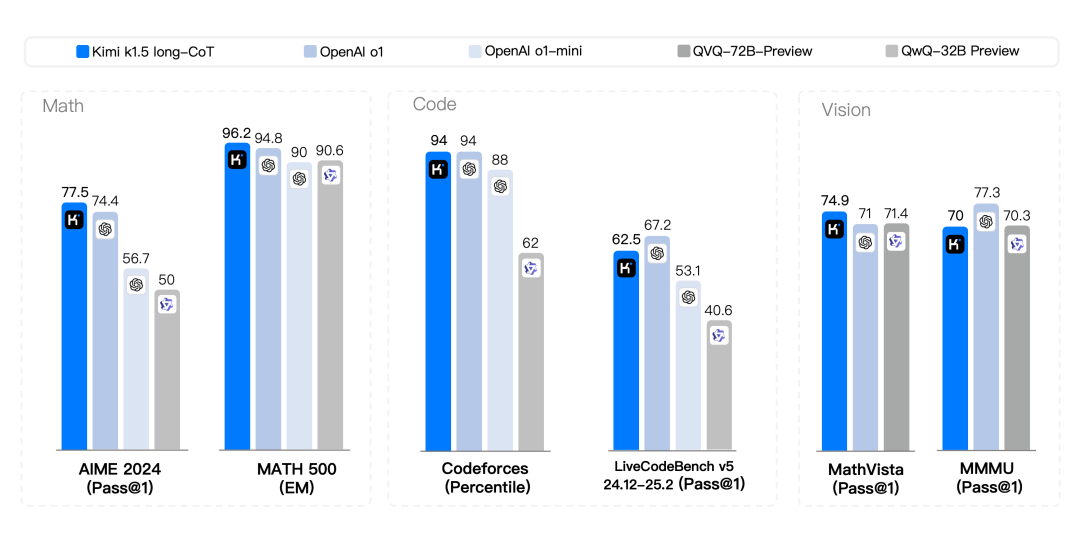
长上下文扩展。我们将 RL 的上下文窗口扩展到 128k,并观察到随着上下文长度的增加,性能持续提升。我们的方法背后的一个关键思想是,使用部分展开(partial rollouts)来提高训练效率——即通过重用大量先前的轨迹来采样新的轨迹,避免了从头开始重新生成新轨迹的成本。我们的观察表明,上下文长度是通过 LLMs 持续扩展RL的一个关键维度。


(文:APPSO)