


图片来源:Amii
Z Highlights
-
到了2024年,深度学习仍然在快速发展,但我们应该重新审视它的局限性。因为对于智能体来说,对于我们真正需要的强化学习来说,传统的深度学习效果并不好。
-
我们应该有一个稳定的主干网络,并且依赖这个主干,在此基础上不断积累更多的知识。这种持续的积累和保护,将是实现动态深度学习的关键。
-
而在主干的外围,有一个更加动态的边缘网络。边缘部分的任务是探索新可能性,尝试变得有用并为主干提供支持。
导言:原理与愿景
大家好,欢迎大家的到来。今天我要讲的主题是“迈向更好的深度学习”。如你们所知,目前我在大学任职,同时也在AMI (Alberta Machine Intelligence Institute) 和Keen Technologies工作。我目前的主要职务是在Technologies,这是一家专注于通用人工智能的初创公司。除此之外,我还创办了Openmind Research Institute,目前这个研究所发展得非常顺利。我们很快就会公布首批研究员名单。
我将这次演讲的副标题定为“原理与愿景”。因此,这次演讲主要是探讨如何实现更好的深度学习。我并不是要提出一个完整的算法,毕竟,要在现有这个庞大而成熟的深度学习领域中实现改进,是一个极具挑战性的目标。甚至可以说,批评这个领域并讨论它的局限性,多少显得有些自负。但我们今天的确会深入探讨这些问题。
这是一个全新的研究项目,目前尚未完成。但与此同时,它是基于许多已经完成的研究工作的成果之上。这些工作有的已经发表,也有的出现在学术论文和研究生的论文中。这些研究来自于Khurram Javed、Arsalan Sharifnassab、Shibhansh、Nassarah Shabane、Parash、Qingfeng、Rupam Mahmood 的学生 Mohamed Elsayed,以及我的好同事Joseph Modayil等人。
为了确保我把所有关键内容都讲到,我会在第一张幻灯片上做一个概要总结。正如我之前所提到的,这次演讲的主题是“原理与愿景”。在幻灯片中,“原理”用蓝色表示,“愿景”用绿色表示,都是为了探索如何实现更好的深度学习。接下来,我会解释我所理解的“更好的深度学习”的含义,尤其是为什么我要将重点放在持续学习(Continual Learning)上,而不是传统的瞬时学习(Transient Learning),稍后我会具体定义这两种学习模式。随后,我将讲述当前深度学习方法在持续学习场景中的局限性,以及如何通过新的、更好的深度学习方法来克服这些问题。
我为这个概念提出了一个名称,叫做动态深度学习(Dynamic Deep Learning),这个名字是在几天前想到的。我们可以看看这个想法是否行得通。在动态深度学习中,网络是按单元逐步增长的,并且随着时间推移,它会不断进行持续学习。
核心思想是,网络中有一个主干(Backbone),这个主干网络是稳定的。在主干的外围,有一个更加动态的边缘网络(Fringe)。边缘部分的任务是探索新可能性,尝试变得有用并为主干提供支持。如果边缘部分成功变得更有用了,就会被纳入主干网络。要实现这一机制,需要开发一系列新的算法。我将在本次演讲中对这些算法进行阐述。最后,我想说的是,尽管还有很多工作要做,但这些技术挑战看起来并不难以克服。因此,我们应该保持积极和乐观的态度。

图片来源:Amii
传统深度学习:可塑性丧失与遗忘
所谓的持续学习意味着你在任何时刻都在学习。每一刻都既是训练阶段,也是测试阶段。而传统的深度学习属于瞬时学习,因为它是在一个专门的训练阶段进行学习,随后在实际运行时就不再学习了。因此,将训练与测试分开,是一种非常不自然的做法。瞬时学习本身就是人为的设定,而自然界中的所有系统都是在持续学习。
从我的角度来看,持续学习其实就是正常的学习,根本不需要一个特别的名称。因为现实中,每个动物、每个人都在进行持续学习,而不是瞬时学习。因此,传统的深度学习是不令人满意的。至少对于持续学习而言,它的表现是令人失望的。原因很简单,这也是深度学习领域的标准观点:随着时间的推移,模型会逐渐失去可塑性。
神经网络在学习新事物的过程中会逐渐失去学习新知识的能力,并且可能出现灾难性的遗忘。当它们学到新东西时,往往会忘记之前学过的内容,而且这种遗忘远超出实际所需的程度。更糟糕的是,它们通常优先遗忘过去学到的最重要的知识。在强化学习(Reinforcement Learning)中,你还可以观察到另一个严重的问题——策略崩溃(Policy Collapse)。深度强化学习智能体在训练过程中,一开始可能表现良好并成功解决问题,但如果继续运行下去,它们的性能会急剧下降,甚至完全崩溃。这种现象已经在多项研究中得到了验证。
事实上,无论是丧失可塑性还是策略崩溃,这些问题都已经被Shibhansh、Fernando等人的研究所证实。这些研究成果将在未来几周内发表在重要的学术期刊上。总的来说,深度学习的过程是缓慢且脆弱的。在训练过程中,所有训练集样本都必须多次重复呈现,而且必须以无关联的方式进行。如果处理稍有不当,就会导致遗忘或可塑性丧失的问题。
从这些问题中,我们可以得出一个重要的结论:仅靠传统的反向传播(Back Propagation)和现有的深度学习方法,远远不够。我们需要勇敢地突破传统思维,用一种全新的方式来思考和解决问题。
到了2024年,深度学习仍然在快速发展,但我们应该重新审视它的局限性。因为对于智能体来说,对于我们真正需要的强化学习来说,传统的深度学习效果并不好。也许我们应该学会放手,放下已有的框架,放松心态,勇敢地去尝试新的思路。
动态深度学习网络:主干与边缘
首先,我们来区分一下传统的深度学习网络。它们通常是固定设计结构,比如分层结构,或者每一层都有特定角色的网络。这种结构是事先设计好的,没有太多灵活性。而我所设想的是一种更有机的系统,即动态深度学习网络。这种网络是通过逐单元(Unit by Unit)的方式积累和生长起来的,从而形成一个最大化灵活性的结构。
这些网络的确是逐步生长起来的。比如说,这个网络最初只有一个输出节点和多个输入节点,然后随着中间单元的引入,网络逐渐变得复杂。这些中间单元充当了特征单元,随着更多单元的加入,网络最终演变成了一个多层网络。这正是我们在动态深度学习中应该追求的方向。至于网络具体如何“生长”,我这次不会给出一个具体的算法描述。但我们可以一起探讨这个问题,共同思考如何实现这一目标。
接下来我们来看第一大步骤,也是整个过程最重要的步骤,那就是要区分网络中已经学习到的部分和其他部分。我把已经学习到的部分称为主干。在图中,蓝色的节点表示无用单元,而黑色的节点代表网络的主干部分。
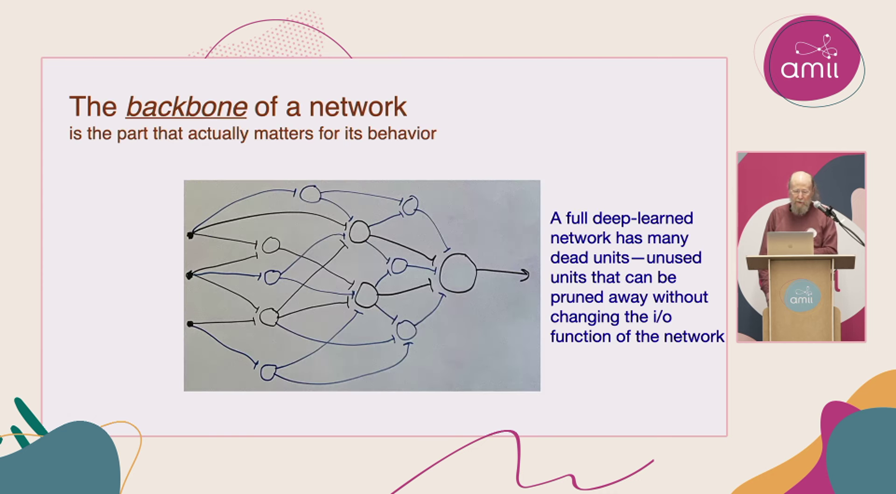
图片来源:Amii
一个完整的深度学习网络中往往包含大量的无用单元,这些单元对网络的功能没有任何贡献,甚至从未被使用过。Shibhansh和Fernando的研究通过持续反向传播(Continual Backprop)验证了这一现象。他们发现,在网络学习结束时,甚至有可能超过一半的单元已经成为死亡单元。因此,我们需要彻底修剪和移除这些无用单元,让网络更加高效和精简。
接下来,我们就只剩下主干了。主干是网络中已经学习到的部分。如果从知识的角度来看,它代表了网络已经获取的知识。这种知识应该被保留和保护,尤其是在你继续学习新知识的时候,绝不能拆解或破坏你已经掌握的内容。然而,很遗憾的是,传统的深度学习方法确实存在这个问题。在学习新知识时,它可能会破坏之前已经学到的内容。这种做法是不可取的。我们应该有一个稳定的主干网络,并且依赖这个主干,在此基础上不断积累更多的知识。这种持续的积累和保护,将是实现动态深度学习的关键。
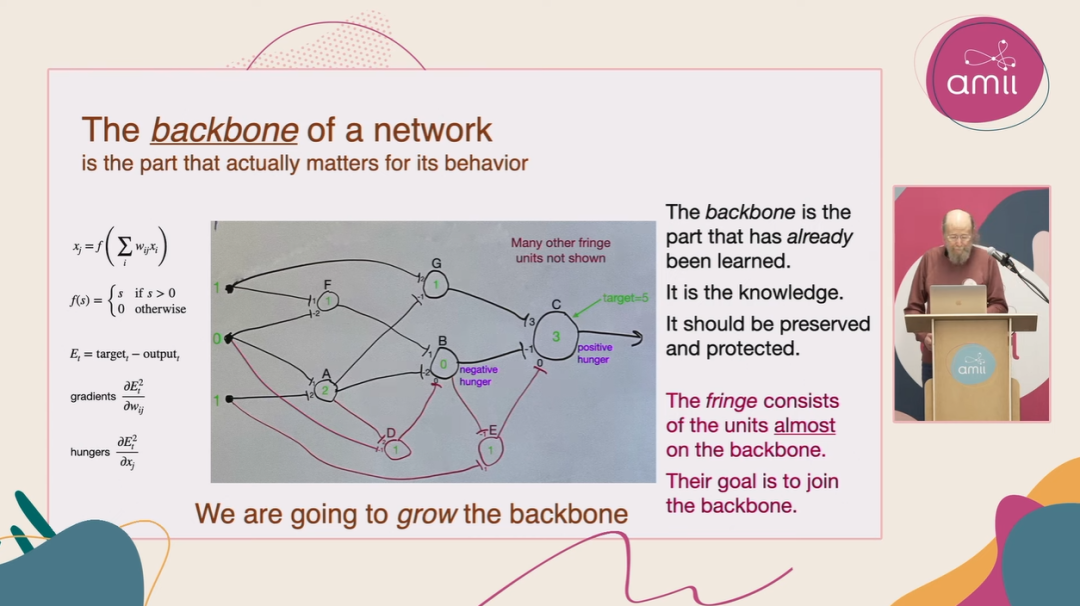
图片来源:Amii
现在,我们来看看网络中除了主干之外的部分。我将这些部分称为边缘。边缘单元是那些更具探索性和试探性的单元。它们在网络中不断变化,试图提出一些对主干有用的内容。如果这些边缘单元的输出被证明是有用的,那么主干就会开始接受它们的输出,并将它们的功能整合进主干中,使其成为网络的一部分。在网络的早期阶段,边缘单元的数量应该会远多于主干单元的数量。在这里,我只展示了少量边缘单元作为示例。请注意这个示例中的输出连接。在这个例子中,有一个单元的输出权重为3,这表示它有一个输出连接。所以,每个单元都有输入权重和输出权重。
通常来说,边缘单元的输出权重一般为0,因为它们暂时不会影响系统的整体行为,对系统的功能贡献有限。根据定义,边缘单元之所以被称为“边缘”,是因为它们暂时不会对系统的整体行为产生影响。从边缘单元到主干的权重值必须为0。然而,这些权重是可以被调整和学习的。如果某个边缘单元形成了一个有用的特征,主干网络就可以选择增大这个权重值,从而将这个边缘单元纳入主干网络的功能中,成为主干的一部分。这就是边缘单元的核心理念——它们是接近主干的单元,目标是加入主干,通过这个过程,我们可以逐步扩展主干网络。
为了进一步探讨这个过程,我们可以设定一个目标值,因为这个过程与常规的监督学习非常类似。在这个示例中,目标值从输出节点反馈回来,目标值是5,而当前的输出值是3。因此,出现了一个正误差。这个正误差就是目标值与实际输出值之间的差异,表示当前的输出值低于目标值,需要进一步调整网络的权重。你可以将损失函数理解为目标值误差的平方。
不过,值得注意的是,“梯度(Gradient)”这个词其实有些误导性。真正的梯度是由所有偏导数组成的一个向量。然而,按照惯例,我们通常也会将单个权重的偏导数称为梯度。例如一个权重的梯度就是它的偏导数。所以,这些偏导数就是我们通常所说的梯度。
接下来,我还想讨论一下平方误差对于单元激活值的梯度。这和权重的梯度是不同的东西。我打算把这种梯度称为饥渴值(Hungers)。
为什么用“饥渴值”这个词?因为主干网络已经在它的现有结构内尽可能地优化了。它通过减少误差来学习,也就是通过减少这些饥渴值来提升性能。但总会有一些残留的饥渴值是无法完全消除的,因为主干网络缺乏必要的资源、信号或特征,无法将这些饥渴值降到0。当然,如果所有的饥渴值都被降到了0,那么学习任务就完成了。但在实际情况中,通常会有一些饥渴值无法被完全消除。这些饥渴值代表了网络对新特征的渴求。它们希望通过引入新的特征来更好地降低误差。这种对改进的渴望,我称之为“饥渴”。
举个例子,在上述网络中,输出节点的饥渴值是正的,因为目标值大于当前的输出值。而另一个节点的饥渴值是负的,这是因为它的权重是负的。为了让输出节点的值更高,这个输入节点会希望自己的值更低,甚至希望自己完全不被激活。这就是为什么我把这种现象称作“饥渴”。
想象一下,这个网络在“生命历程”中会经历怎样的变化。我现在展示的是网络在某个时间点的快照,包括某个特定输入和特定输出的场景,以及网络中所有的中间值。在这个时间点,网络中存在一些误差。到了下一个时间,网络将接收到另一个样本和目标值,这时会出现一组新的误差。所有这些误差都可以看作饥渴值,是我们希望持续减少的目标。为了减少这些误差,我们需要找到能够提供新特征的边缘单元,因为这些新特征可以帮助网络更有效地降低误差。
我希望大家已经理解了这个核心概念。因为要实现这个设计,我们不仅需要现有的算法,还需要开发多种新算法来支持网络的持续生长和优化。我们需要在主干网络中进行学习,也需要在边缘网络中进行学习。同时,我们需要识别主干网络并维护主干与边缘的边界。接下来,我们简单讨论这些内容,并在脑海中思考它们的实现方式。
实现动态深度学习:识别与更新
首先,在主干网络中学习可以通过正常的反向传播来实现。同时,我们希望将其与步长优化(Step Size Optimization)结合使用。因为我们需要保护主干网络。主干网络代表我们已经掌握的知识,因此我们不希望对它进行大幅调整。我们希望以小步长的方式逐步优化,而步长优化可以帮助我们实现这一点,使网络在主干部分的调整更加稳定。
那么,在边缘网络中学习呢?这确实是一个挑战。因为我们无法在边缘网络中使用反向传播。在反向传播中,我们根据误差对权重的梯度来调整权重。这种方法对主干网络有效,但在边缘网络中却失效。根据定义,边缘单元的梯度值为0。为什么?因为边缘单元不会直接影响输出值,因此它们不会影响误差。结果是,边缘单元的所有梯度值都是0。因此,在边缘网络中,标准的反向传播算法无法起作用。我们必须寻找其他方法来实现学习。
是不是很有趣?我们可以清楚地看到,标准的反向传播算法在发现新特征时存在天然的局限性。它至少无法从无到有地创造出新特征。这说明,我们确实需要开发新的算法来解决这个问题。那么,我们该如何实现这个目标呢?我将会在后面告诉大家一个方法,这个方法叫做影子权重(Shadow Weights)。
接下来,我们的任务是找到主干网络。如何识别出对网络输出有实际影响的那部分网络,并将其与不影响网络输出的部分区分开来?如何确定哪些单元属于主干网络?根据定义,输出单元肯定是主干的一部分,因为它直接生成系统的输出。所以,我们至少知道输出单元一定在主干网络中。那么,接下来我们如何识别那些仍然活跃且对误差有贡献的单元呢?
如果某个单元对输出单元有一个非零权重,不论是正的还是负的,那么这个单元也应该属于主干网络。我很喜欢这个方法,因为它具有一种闭包性质。这意味着,如果某个单元属于主干网络,那么任何被这个单元使用的上游单元也应该属于主干网络。这个递归过程可以帮助我们逐层识别出更多的主干单元,从而更全面地定义主干网络的范围。
这种过程是逐步向后传播的,但它与反向传播不一样,这种传播方式仅依赖于权重值,而反向传播依赖于瞬时激活值。因此,这种缓慢的向后传播只取决于权重值的变化。在实现上,它相比反向传播有许多优势。在一些无法使用反向传播的情况下,你仍然可以采用这种缓慢的效用传播方法。这也是我所推荐的策略。
让我们继续深入讲解。接下来我要讲的正是效用(Utility)这个概念。你们可能之前就听过关于效用的讨论。在Shibhansh和Fernando的持续反向传播研究中,他们使用了这个概念。我们会将具有非平凡效用(Nontrivial Utility)的单元视为主干网络的一部分。
当然,输出单元一定是主干网络的一部分。我们会在每个输出单元处放置一个效用值,因为这是主干网络的起点。而每个主干单元都会将一部分效用值传递给那些对它具有非零权重的前驱单元。这些权重是它所依赖的连接,而这里的关键在于效用是守恒的。即当一个单元将效用值传递给某个前驱单元时,它自身的效用值就会减少。因为网络中的效用总量是有限的,所以必须在单元之间分配和传递。如果某个单元的效用值低于某个阈值,那么这个单元将不再被视为主干网络的一部分。这就是效用传播算法(Utility Propagation Algorithm)的基本框架。
现在,让我们讨论最大的问题——边缘网络中的学习机制是如何运作的。首先,我会用文字来解释这个概念,然后再通过图示进行说明。根据定义,我们关注的是边缘单元的权重梯度。然而,这些梯度值始终为0,因此我们无法使用反向传播来调整边缘单元的权重。
那么,边缘单元该如何学习呢?每个边缘单元都会有一个对应的主单元(Master Unit),这个主单元位于主干网络中。边缘单元的目标是让主单元倾听它的输出。换句话说,边缘单元希望为主单元提供价值,从而从主单元那里获得效用,并最终加入主干网络。
需要注意的是,边缘单元到主单元的权重在设计上必须非常小,甚至为0。为什么?因为如果权重过大,边缘单元的输出就会干扰主单元,从而干扰主干网络,破坏已有的学习成果。实际上,如果某个边缘单元的权重足够大,它就会直接被视为主干网络的一部分。
因此,根据定义和设计,边缘单元到主单元的权重必须是0或一个非常小的值。与此同时,这个权重的步长(Step Size)也必须很小。即使权重的初始值是0,如果步长过大,权重也会快速增大,从而干扰主干网络,影响已学到的知识。
边缘单元虽然初始权重为0,但它渴望增加这个权重,以便逐渐加入主干网络。为实现这一目标,边缘单元会设置一个影子权重。这个影子权重可以是+1或-1,用来表示边缘单元希望对主单元的权重进行正向或负向调整。这里的关键在于,真实的权重只能由主单元来调整,因为主单元会根据它自身感受到的误差或饥渴值来决定是否调整权重。而边缘单元可以任意设置影子权重,用来表达它希望对主单元的权重做出哪些改变。

图片来源:Amii
图片中是我们之前讨论的网络情况,但现在我要大家重点思考一下D和E两个新添加的单元。这两个单元刚刚被加入网络,而这个过程被称为印刻(Imprinting)。印刻过程就是边缘单元的创建过程。在这个过程中,新单元会被分配一个主单元。E的主单元是C,单元D的主单元是B。
在分配好主单元后,新单元还会被分配一个影子权重,这个影子权重反映了实际权重的方向。单元C的饥渴值是正的,因此分配的影子权重是+1。单元B的饥渴值是负的,因此分配的影子权重是-1。
还有一个最后的步骤。当我们将D和E印刻到网络中时,我们需要为它们添加输入连接。这些输入连接是如何选择的呢?在这里,我选择了一种方式,但实际上,这些连接可以通过多种方式确定。你可以想象,输入连接可能是从新单元的前驱单元中随机选择的,因为我们的目标是保留网络的前馈结构。
最后,边缘单元的权重值是在创建时通过印刻过程来确定的,这意味着这些权重是从新单元创建时的输入模式中提取的。最简单的理解方式是,你设定影子权重,然后重放输入样本。在这个例子中,我们已经设置了影子权重。当你重放样本时,网络产生了一个正的饥渴值。如果影子权重是真实权重,那么误差就会向后传播,梯度也会向后传播到单元E,从而促使E调整自己的权重。而权重调整过程,就是印刻过程的核心内容。
在这个例子中的C节点,影子权重是+1,梯度向后传播,我们希望增加这个节点的值。对于输入值为1的连接,我们设置一个正权重。对于输入值为0的连接,我们设置一个负权重。
而当饥渴值是负的时,比如在另一个例子B节点中,影子权重是-1。这时,你可能会认为我们应该降低这个节点的输出值,但实际上我们仍然希望单元D被激活。这样它就能对B产生负影响,从而帮助调整B的输出值。因此,即使影子权重是负的,我们仍然:对于输入值为1的连接设置正权重,对于输入值为0的连接设置负权重。
这就是印刻边缘单元的过程,以及边缘单元如何与主干网络建立联系的机制。简单来说,影子权重是边缘单元的期望连接方式。它们代表了这些单元希望如何连接到主干网络,这就是它们的愿景。
最后,我想再次提醒大家,步长优化是整个框架的核心组成部分。通过控制步长,我们可以有效防止灾难性遗忘,从而保护主干网络,避免它受到边缘网络的动态变化的干扰。
整个过程是这样的:边缘单元会创建一个影子权重,并通过这个影子权重连接到主单元。如果边缘单元提供的特征对主干网络有用,那么连接到主单元的权重的步长会先增加。而一旦步长值变得非平凡,该权重就会开始实际增加,从而使边缘单元正式加入主干网络。这就是我们所设想的印刻过程的运行机制。
总结与未来:更好的深度学习
好了,这就是我们所描绘的更好的深度学习愿景——一种更适合持续学习的框架,而非传统的瞬时学习框架。这是一种更深层次的学习,也是一种动态学习。为什么说它是动态的呢?因为我们不仅在持续学习,而且在不断调整网络结构。
这个框架的核心理念如下:主干网络保持稳定。边缘网络是动态且具有探索性的。当边缘网络取得成功时,它就会逐渐融入主干网络。其中,影子权重的概念是实现这一过程的关键。当然,要实现这个框架,我们还需要开发新的算法,而今天我们已经对这些算法进行了初步的构想。
显然,这项工作还有许多未完成的部分,也有一些细节尚未完全明确。但是,至少在我看来,这些挑战并不特别困难。我相信,我们完全可以打造出一种更好的深度学习框架。这种框架将更适合智能体和强化学习的应用场景。
原视频:Rich Sutton, Toward a better Deep Learning
https://www.youtube.com/watch?v=YLiXgPhb8cQ&t=228s
编译:Yvonne
(文:Z Potentials)