
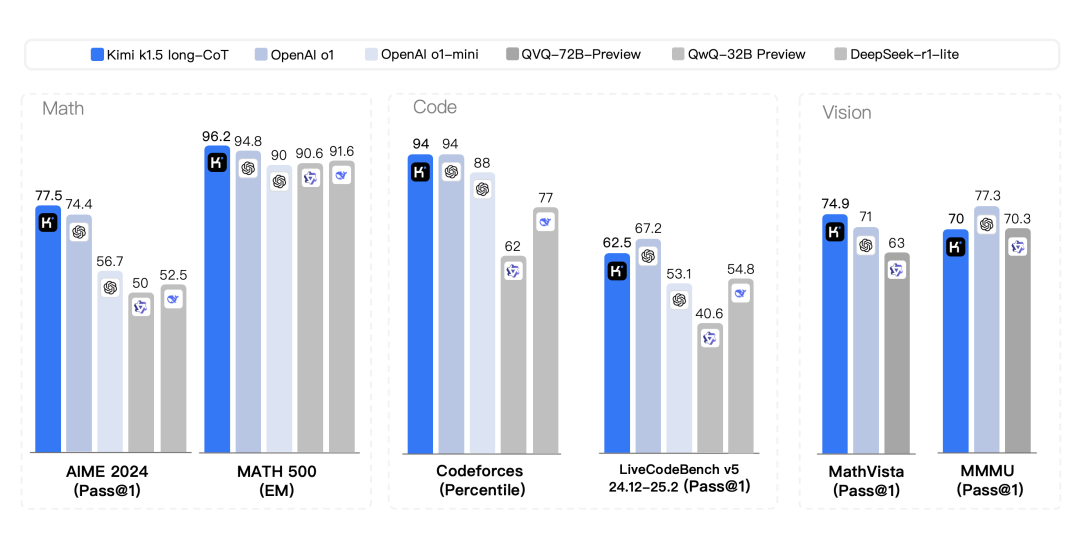
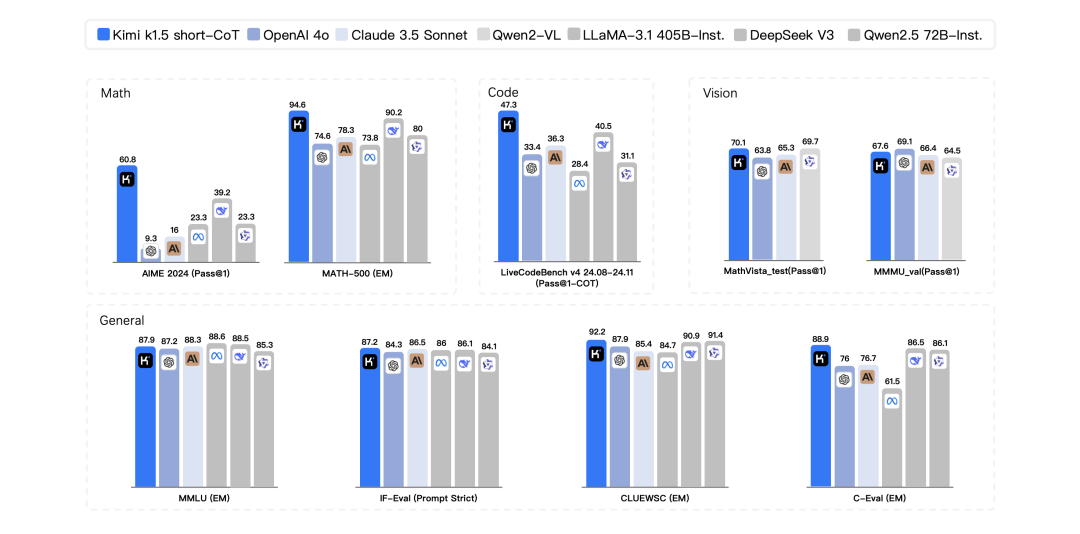
-
预训练:k1.5 的预训练涉及多模态数据(文本、视觉、OCR 等),并分为三个阶段:视觉-语言预训练、冷启动阶段和长文本激活阶段。
-
监督微调:使用高质量的标注数据进行分阶段学习率调整微调,涵盖问答、写作、数学、编程和视觉-文本数据。
25页的技术报告重点聚焦在强化学习部分:
数据构建 -> 预热 Long-CoT SFT -> RL -> Long2Short
https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
1. RL数据构建
数据质量和多样性对强化学习的效果至关重要。高质量的提示集可以引导模型进行稳健的推理,并减少 reward hacking 和 overfitting 的风险。
-
多样化覆盖:涵盖广泛的学科领域(如 STEM、编程和通用推理),以增强模型的适应性。 -
难度平衡:包含不同难度级别的问题,以支持模型的逐步学习。 -
可验证性:答案和推理过程应能够被准确验证,避免模型通过错误的推理过程得出正确答案。
2、预热-Long-CoT微调
通过构建小的高质量 Long-CoT 热身数据集并进行微调,目的是让模型内化人类推理的关键认知过程(如规划、评估、反思和探索),从而提升其在复杂推理任务中的表现和逻辑连贯性。
3、强化学习
强化学习是 k1.5 的核心训练阶段,无需依赖蒙特卡洛树搜索(MCTS)、价值函数或过程奖励模型等复杂技术,通过长上下文扩展和策略优化实现高效学习。
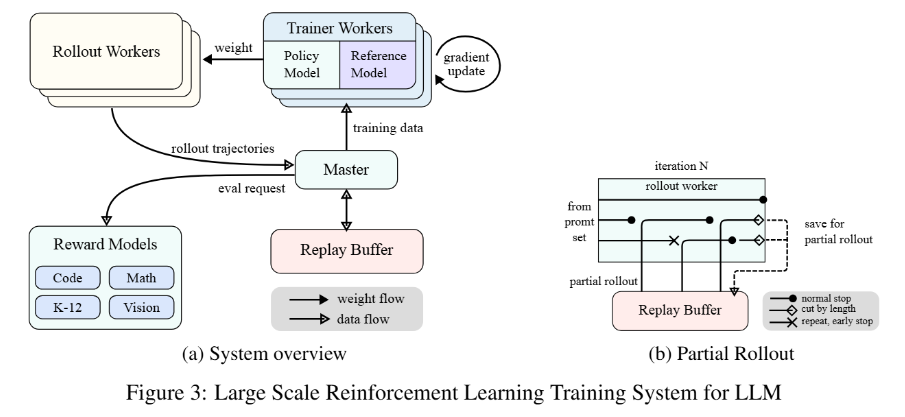
-
长上下文扩展是k1.5的核心创新之一。通过将上下文窗口扩展到128k,模型能够处理更复杂的推理任务。背后的关键技术是 partial rollout ,它允许模型在训练过程中复用之前生成的轨迹片段,避免从头开始生成新轨迹,从而显著提高训练效率。
-
k1.5采用在线镜像下降算法的变体进行策略优化,通过采样策略、长度惩罚和数据配方优化,进一步提升模型性能。长度惩罚机制通过限制模型生成过长的推理过程,提高推理效率,同时避免“过度思考”问题。此外,模型还采用了curriculum sampling和 prioritized sampling 策略,优先训练模型在困难问题上的表现。
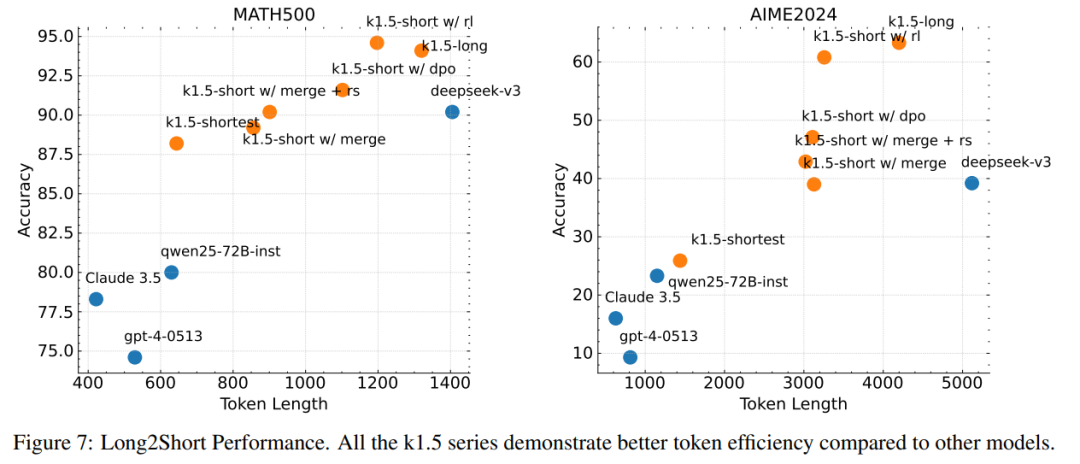
4、Long2short
Long-CoT模型表现出色,但在测试时消耗的token数量比Short-CoT更多。有没可能将Long-CoT推理模型的思维先验转移到Short-CoT推理模型中,从而即使在测试时的token预算有限的情况下,也能提升性能,答案是肯定,k1.5尝试了以下方法:
-
模型融合(Model Merging):通过平均权重合并Long-CoT 和Short-CoT 模型。
-
最短拒绝采样(Shortest Rejection Sampling):从多次采样中选择最短的正确答案。
-
直接偏好优化(DPO):通过正负样本对训练Short-CoT 模型。
-
Long2Short RL 训练:通过 RL 进一步优化Short-CoT 模型的性能。
(文:PaperAgent)