
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
几乎不论是什么行业,都有一条通用的“金科玉律”:越“卷”越强。
这话放到AI领域,那简直是太对了。
回想2023年,还是OpenAI、ChatGPT“独霸天下”的时代。短短不到两年过去了,国外有“御三家”:Anthropic的Claude 3.5 Sonnet,谷歌的Gemini-Exp-1206、Gemini-2.0-Flash,马斯克的xAI,Meta的Llama 3.1 405B,这些AI模型都足以和GPT-4分庭抗礼;国内更不用多说,最近各个AI厂商都在紧锣密鼓的发布自家的新模型,包括:DeepSeek的DeepSeek-V3、DeepSeek-R1,MiniMax的MiniMax 01,阶跃星辰的Step R-mini,面壁智能的MiniCPM-o 2.6,Kimi的K 1.5,以及字节旗下豆包昨天发布的Doubao-1.5-pro。
网友直呼:AI界的“春晚”提前来了,好不热闹!
马上要过年了,怎么少得了外国“友人”的祝福。独乐乐不如众乐乐,前方谷歌发来贺电。
北美时间1月21日(昨天),就在我们的国产模型DeepSeek-R1刷屏海外AI圈的一天后,谷歌不甘示弱的发布了Gemini系列中新一代的推理模型:Gemini-2.0-Flash-Thinking-Exp-01-21。

划重点,新版本的Gemini 2.0 Flash Thinking依旧在谷歌AI Studio里向所有用户免费提供使用,并且支持API调用,当然也是免费的(会有速率RPM限制)。
插播一句,关于如何使用谷歌AI Studio,看这里:手把手教你免费使用排名第一的谷歌Gemini模型!
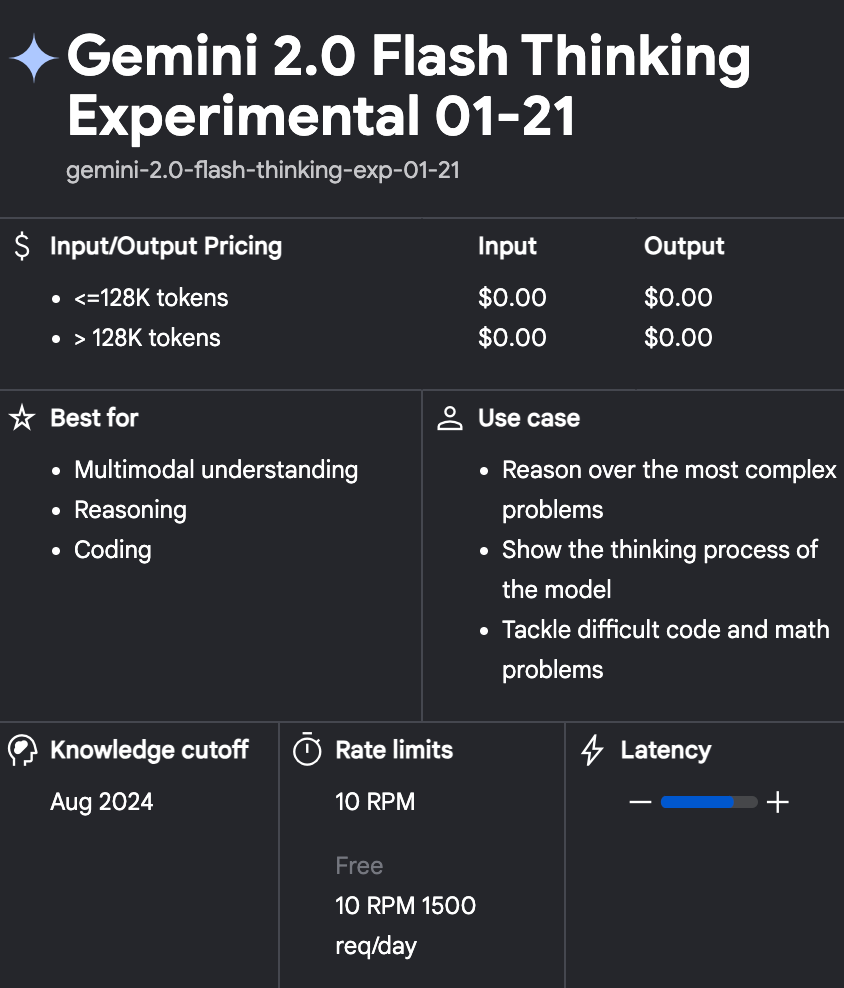
这是AI Studio里Gemini 2.0 Flash Thinking的模型卡片,可以看到费用(Pricing)都是0,擅长推理、代码(推理模型的强项)和多模态理解。速率限制是每账号10 RPM(requests per minute),也就是每分钟可以进行10次对话,每天的上限是1500次,正经人都够了吧!
那么,新版本的Gemini 2.0 Flash Thinking有什么特点?
从官方的介绍来看,有这么4点。一是100万tokens的上下文窗口。长上下文一直是谷歌Gemini系列模型的强项,目前排名第一的通用模型Gemini-Exp-1206上下文长度是200万tokens,你品一品。
二是代码执行功能。Gemini 2.0 Flash Thinking支持原生代码执行,执行过程是在沙盒里完成的。只需在使用时把Code execution工具的开关打开即可。
三是更长的输出长度。但谷歌官方并没有明确说明Gemini 2.0 Flash Thinking具体的输出长度。从技术文档可以查到,基座模型Gemini 2.0 Flash的输出长度为8192 tokens。
四是减少了模型矛盾。意思是提高了这个推理模型的可靠性和一致性。(也就是我经常提到的推理模型的“自我怀疑”、“自我否定”)
新模型的发布少不了基准测试对比。
这是Gemini 2.0 Flash Thinking的基准测试结果,包括AIME 2024(73.3%)和GPQA Diamond(74.2%)。可以看到这个新模型和前代模型相比明显的进步。
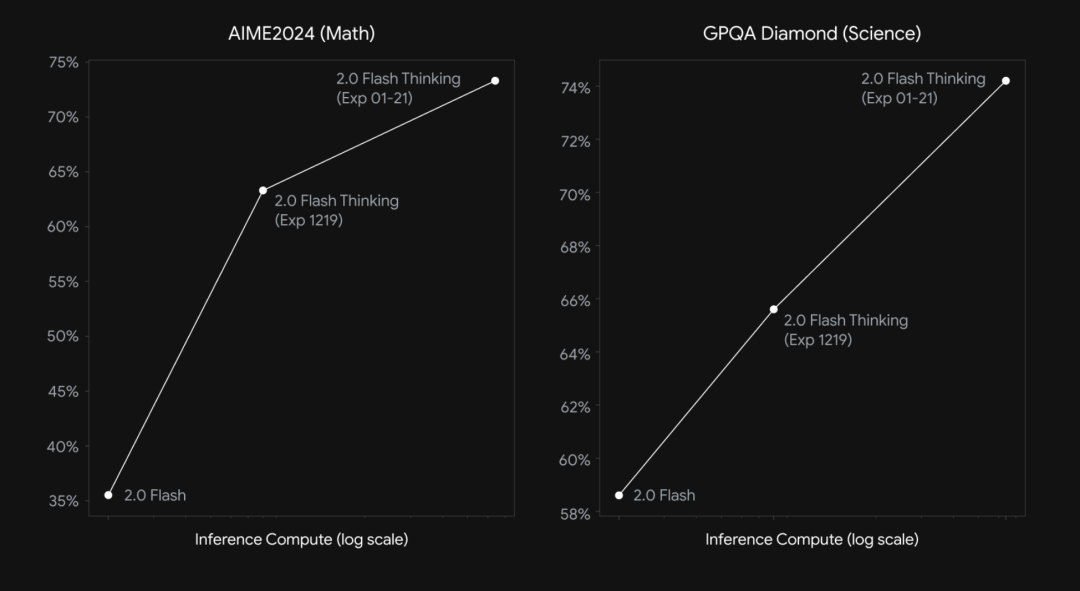
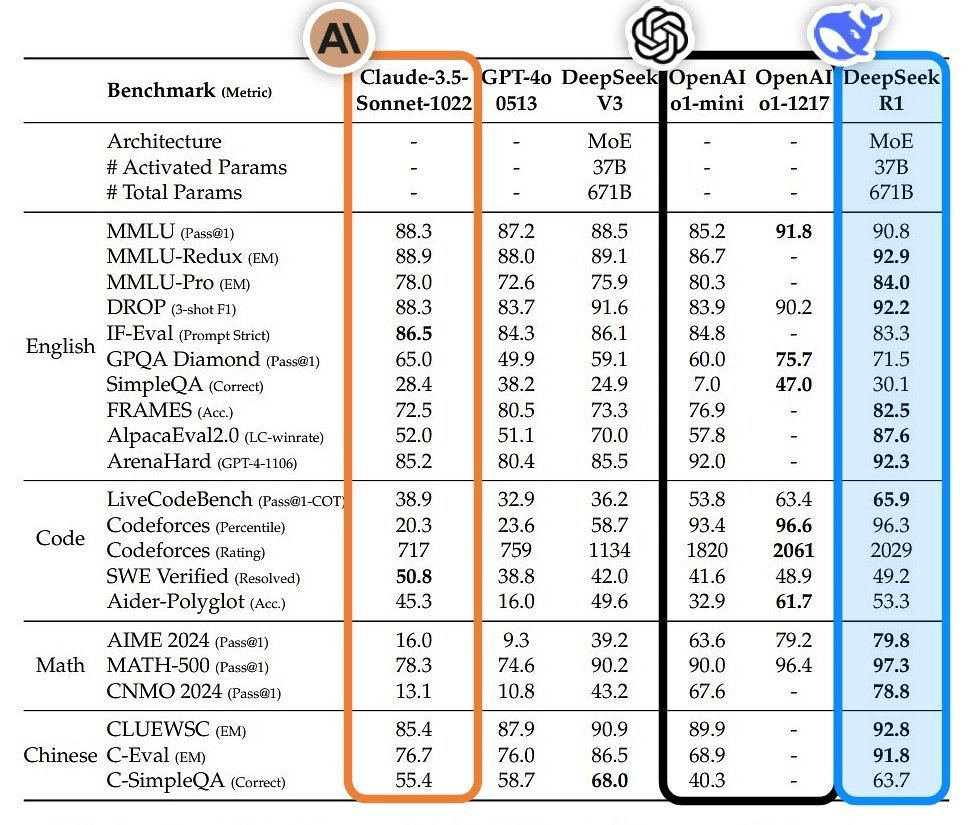
以难度非常大的GPQA Diamond测试为例,Gemini 2.0 Flash Thinking的得分(74.2%)应该是介于OpenAI满血版o1(75.7%)和DeepSeek-R1(71.5%)之间。
结语
谷歌和它的AI Studio,狠狠推荐!
(文:AI信息Gap)
谷歌新推的Gemini 2.0 Flash Thinking model Parameter 100w上下文窗口,代码执行功能,输出长8k tokens,还更稳定!这也太牛了吧!
AI又要卷到不能再卷了!新版本Gemini 2.0 Flash Thinking简直太强了,那些什么DeepSeek-R1、Minimax等等根本比不过它!