

-
要了解系统能够做什么以及它被应用在何处
-
破坏AI系统并不一定要计算梯度
-
AI红队测试并非安全基准测试
-
自动化有助于覆盖更多的风险领域
-
人类因素在AI红队测试中至关重要
-
负责任的AI危害普遍存在但难以衡量
-
大语言模型(LLM)会放大现有的安全风险并引入新的风险
-
保障AI系统安全的工作永远不会完结
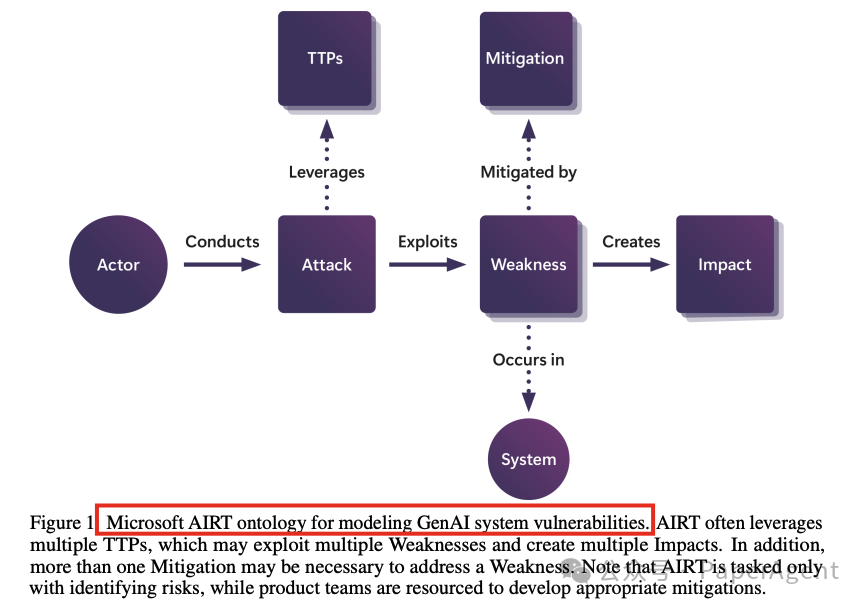
微软AIRT用于建模GenAI系统风险的本体论。AIRT经常利用多个战术、技术及程序(TTPs),这些TTPs可能会利用多个弱点并产生多个影响。此外,解决一个弱点可能需要不止一种缓解措施。需要注意的是,AIRT的任务仅是识别风险,而产品团队则负责开发适当的缓解措施。
案例研究 # 1: 视觉语言模型(VLM)生成不好内容

案例研究 #2: 大模型(LLM)越狱(STT/TTS结合)

案例研究 #3: 评估大模型聊天机器人如何回应处于困境中的用户

案例研究 #4: 探测文本到图像生成器的偏见

案例研究 #5: 视频处理GenAI应用中的SSRF漏洞

https://arxiv.org/pdf/2501.07238Lessons From Red Teaming 100 Generative AI Products
(文:PaperAgent)