







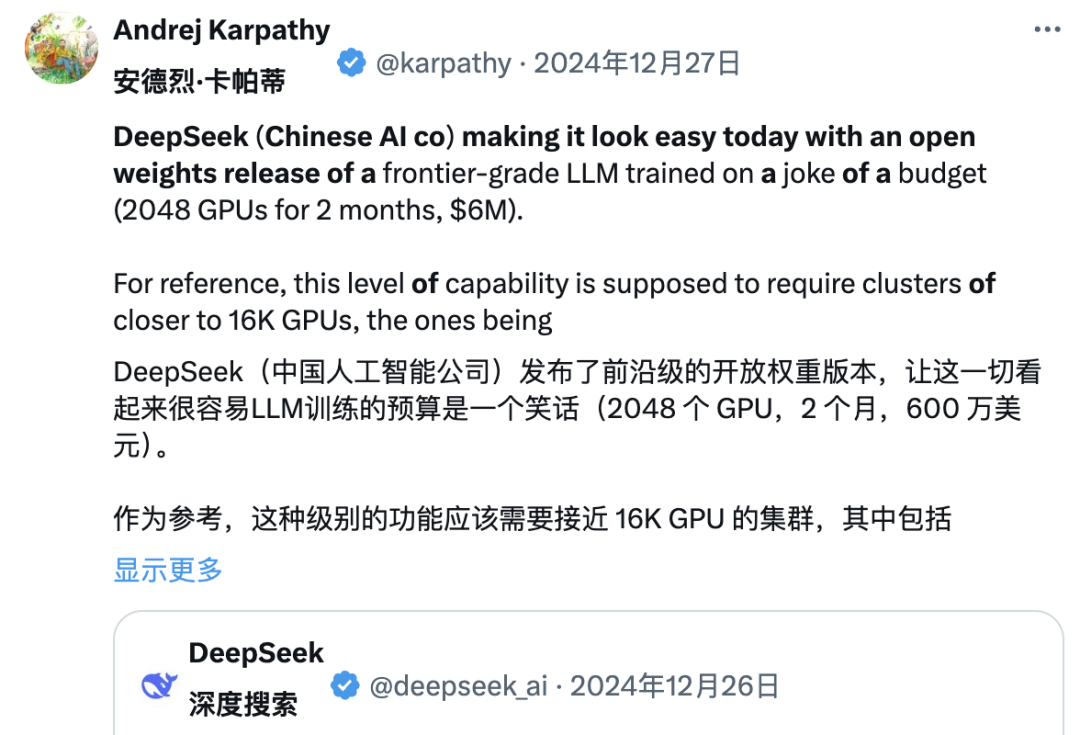
影响力既可以通过「ASI 内部实现」或「草莓计划」等传说般的项目实现,也可以简单地通过公开原始算法和 matplotlib 学习曲线来达成。







使用基于硬编码规则计算的真实奖励,而不是那些容易被强化学习「破解」的学习型奖励模型。
模型的思考时间随着训练进程的推进稳步增加,这不是预先编程的,而是一种自发的特性。
出现了自我反思和探索行为的现象。
使用 GRPO 代替 PPO:GRPO 去除了 PPO 中的评论员网络,转而使用多个样本的平均奖励。这是一种简单的方法,可以减少内存使用。
值得注意的是,GRPO 是由 DeepSeek 团队在 2024 年 2 月发明的,真的是一个非常强大的团队。


另一方面,我们也觉得无论是 API 还是 AI,都应该是普惠的、人人可以用得起的东西。」



(文:APPSO)