

从 2022.11.30 OpenAI 发布 ChatGPT 3.0 后,大模型呈现大爆炸式发展,AI 的重要性一下子大提升,经历了拉资源、AI 创业公司、大厂提升到战略高度、百模大战、大规模推理应用。而这一切都离不开数据,训练数据成为模型效果的核心要素之一。在 AICon(全球人工智能开发与应用大会) 也经常会有大模型数据相关专题技术分享。
阿里巴巴国际数字商业集团(Alibaba International Digital Commerce,简称 AIDC),是一家跨境电子商务集团,主要业务在跨境电子商务上,旗下业务包含 AliExpress、Lazada、阿里巴巴国际站 ICBU、Trendyol、Daraz、Miravia 等。在这样的全球电商业务背景下,我们需要解决的是多语言场景下的内容本地化、全球用户服务、全球市场营销等全球业务问题。在这样的业务背景和大模型技术背景下,AIDC 研发了多语言大模型,以提升效率和解决业务发展中遇到的问题。大语言模型其中一个典型的业务场景是翻译,翻译作为 NLP 的一个细分子领域,在近年来一直以 NMT 技术为主,基于大模型的翻译蕴藏着巨大的机会
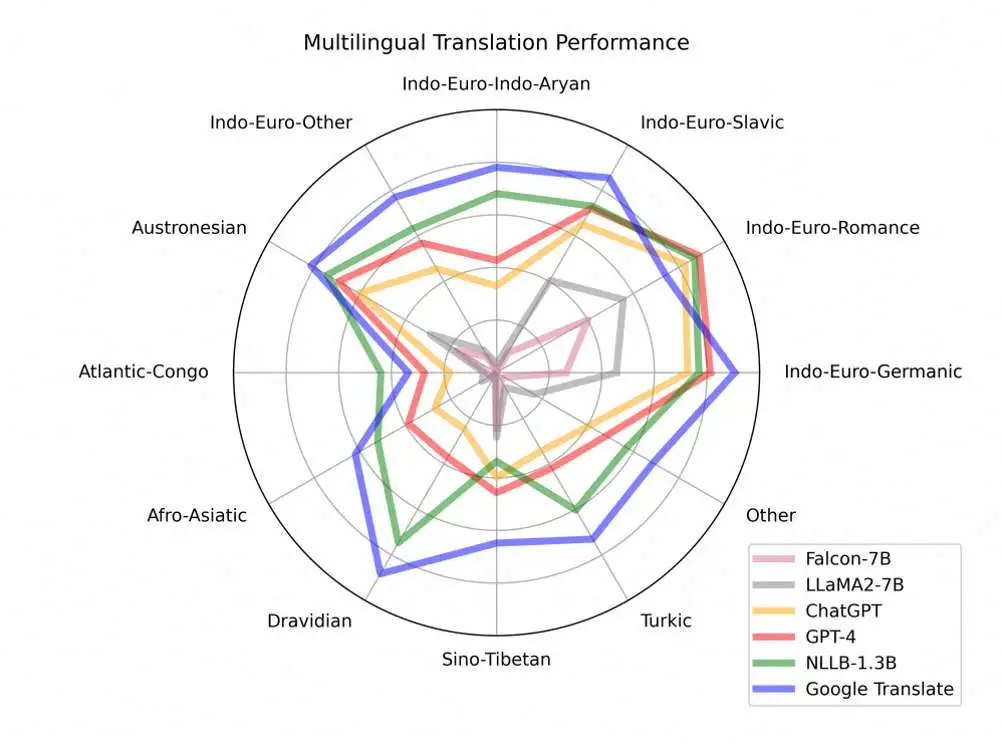
目前业界翻译技术的水平在各个语系下表现如下图,从图可以清晰看到 Google Translate 表现强劲,其核心技术就是 NMT,GPT-4 在一些语系上表现优秀,但是在很多语系上表现仍然有不小的差距。阿里国际多语言翻译大模型就是在这样的技术背景和业务背景下开始的。
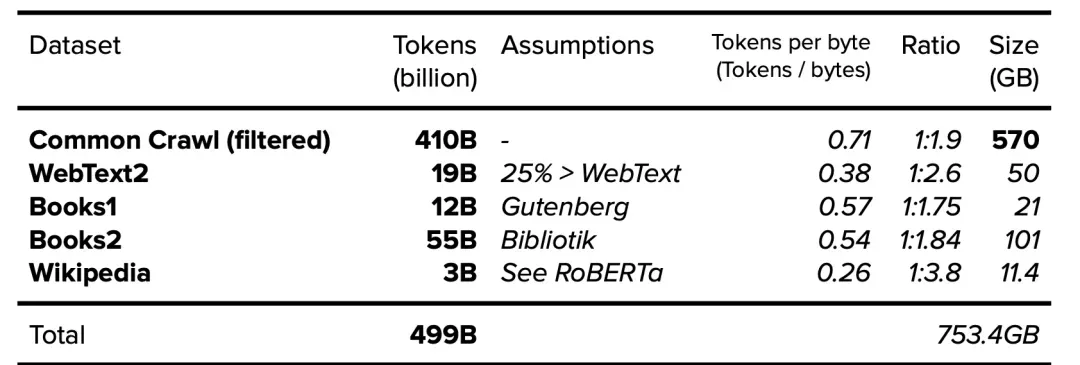
数据的重要性一直被提起和强调,在很多言论中,把数据类比成石油,可见其重要性。这里尝试对数据做一个大概的定义,在大模型之前,业界提到数据更多的偏向于商品、客户、消费、订单交易、支付、物流等生产经营类数据,那个阶段市面上经常讲是精准营销、风险控制、销量预测与库存优化等一些数据驱动的数据智能案例。那么这里把这一个阶段数据从业务上定义为生产经营类数据,从数据形态上看,更多业务结构化数据,从数据处理技术看更多是分布式数据计算、离线实时计算,用到的计算引擎偏类 Hadoop、Spark 类的计算引擎,业界大概称之为数据仓库、数据中台。到大模型时代,这个数据的定义很显然了发生了巨大的变化,看 ChatGPT3.0 公开的训练数据清单,如下图
Llama3 公开的训练数据规模是超过 15T 的 Token ,DeepSeek3 公开的训练数据规模是 14.8T 的 Token。
这里有两个重要变化,1)数据计量单位 Token 2)数据不是企业内部生产经营数据。这背后意味着,数据全生命周期的数据采集、数据范围、数据结构、处理方法、数据使用等各个阶段任务发生了巨大变化。
多语言大模型研发,数据上核心要解决多语言数据问题,我们在整个研发流程中核心从四个方面来解决多语言数据,一是全球多语言网页数据的获取与处理,二是平行语料的获取与加工,三是多语言数据的合成,四是业务积累数据的使用。
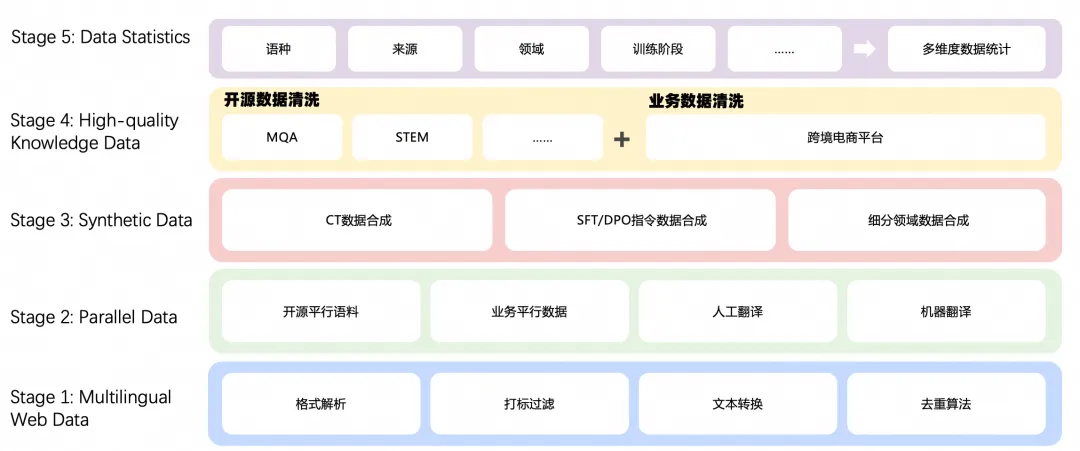
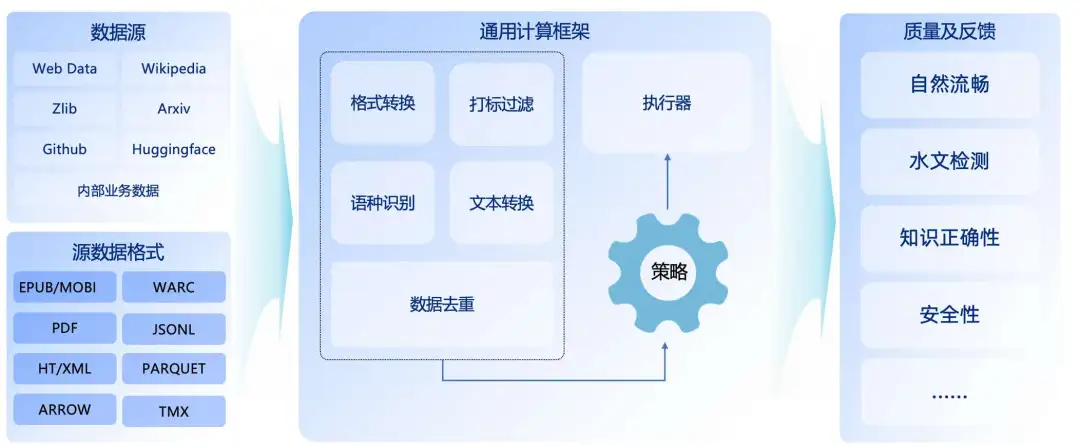
在模型训练的 CT、SFT 、DPO 等各个阶段,都涉及基础的数据处理方法,因此对这些基础处理方法进行抽象,设计出一个通用的数据计算处理框架,融入多语言计算逻辑,如语种识别、各语种语法、各语种标点符号等

对于不同的数据,我们使用这个通用的计算框架,再在处理之后做一定的处理就可以,如多语言数据的处理流程,在数据收集完成之后,使用通用计算框架,配置执行策略,对数据进行格式转换、打标过滤、语种识别、文本转换、数据去重,在通用框架计算之后,使用质量与反馈的一系列方法最终产出多语言的训练语料。
平行语料使用了开源的数据语料清洗,如 OPUS、 CCAligned;也做了大量的专家翻译,作为核心平行语料数据。在此基础上,一方面,我们使用种子词,让 LLM 根据关键词和主题等属性生成训练数据 ;另一方面我们也基于单语的多语言数据,合成平行语料,设计 Translate Template,以提高输入的多样性,使用了 In-Context Learning 和多语言翻译技术来生成多语言数据,以增强多语言平行句子之间的语义对齐。从实践经验上看,平行数据对增强 LLM 的多语言能力非常重要,尤其是对翻译任务。

基于关键词的数据合成

基于 Translate Template 合成平行语料
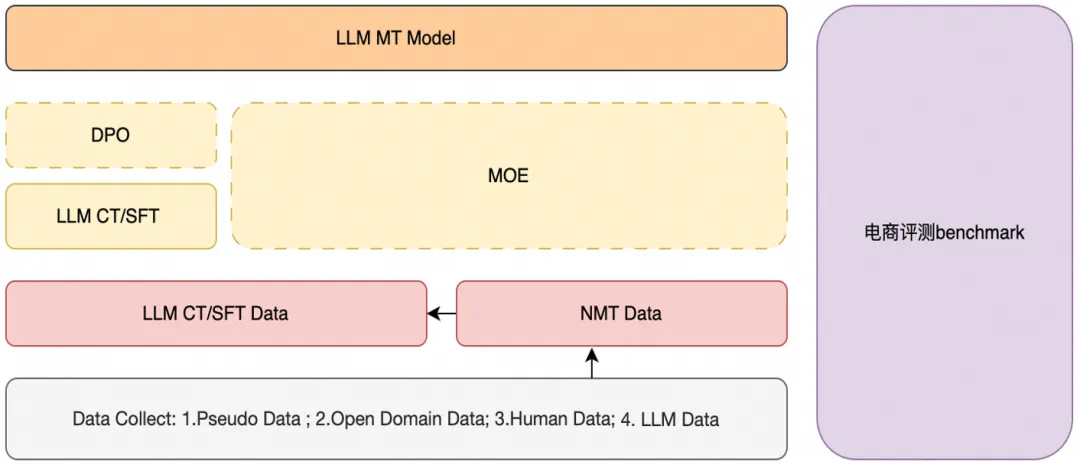
电商翻译 CT,基于标题 / 详情 / 评论 / 对话 / 搜索等大量电商语料进行 CT,构建多语言翻译大模型底座,目前支持 20+ 语言。电商翻译 SFT,通过加入电商高质量的平行语料进行 SFT,进一步提升 LLM 的翻译效果,同时翻译结果具备一定的电商风格。电商翻译偏好对齐,通过 DPO,使用特定的偏好数据训练,缓解 LLM 翻译的幻觉问题,同时提升翻译场景特有词的翻译效果。
我们在模型训练上采用了一种两阶段 CT 学习方法,旨在促进将主要以英语和中文获得的常识性知识转移到各种低资源语言,以及机器翻译等特定的 NLP 下游任务。在持续预训练方面,数据混合和学习率是优化 Marco 的两个关键超参数。在我们的实践中,我们在两阶段训练中使用了不同的超参数。具体来说,我们选择混合数据来平衡第一阶段的多语言能力和灾难性遗忘的适应性,而第二阶段的目标是通过降低最大学习率来进一步增强 Marco-LLM 的多语言能力。
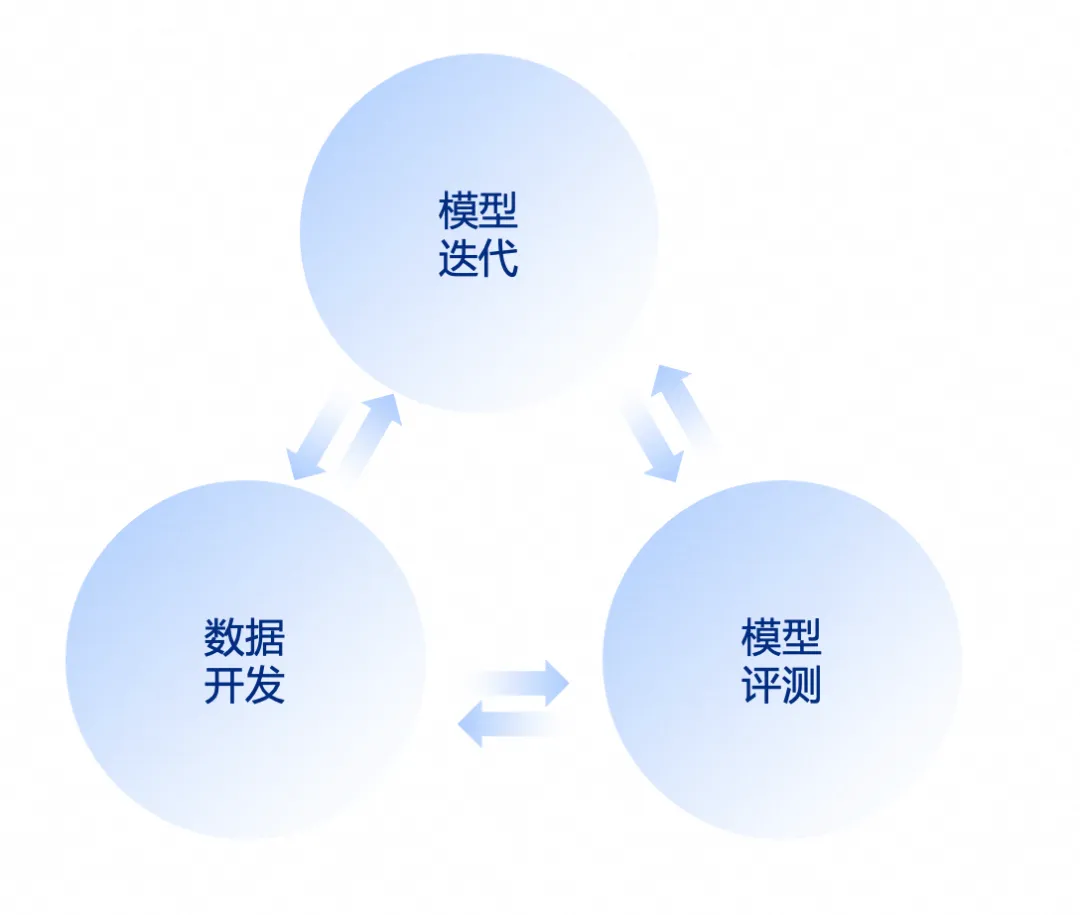
模型评估是模型研发迭代非常重要一环,通过模型在多语言领域通用 Benchmark 评测,补充对应语种、语向数据,以提升模型表现;在模型业务评测上,以 Human Feedback 作为 Ground Truth 进行训练裁判模型,以此获得自动化模型业务表现的评估能力。只需要构建多语言模型的业务评测集,使用人工评测与模型评测相结合,在细分业务场景补充数据,以提升模型业务表现
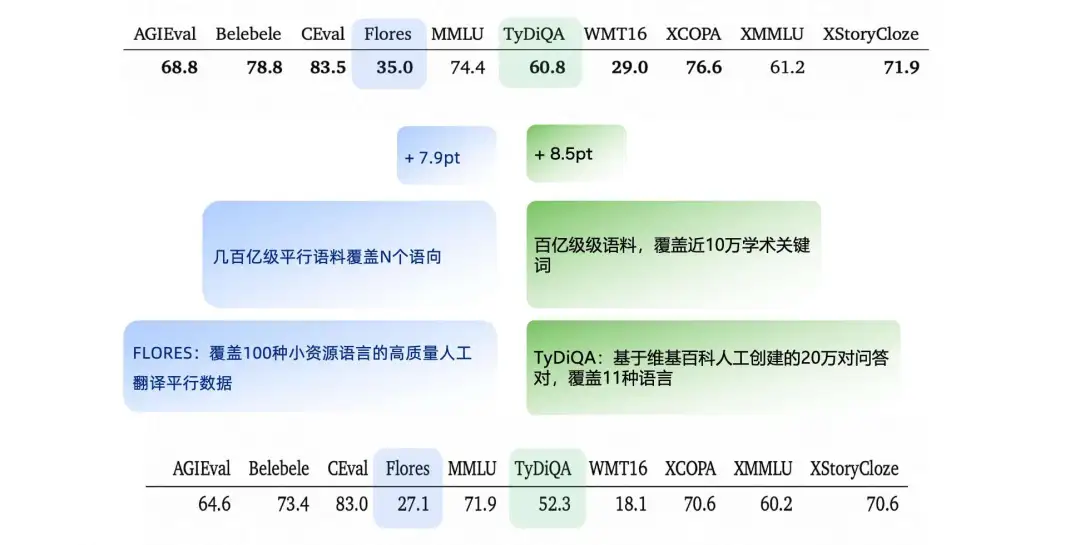
一次通用 Benchmark 的评测上,我们的模型在 Flores、TyDiQA 两个 Benchmark 上表现有较大提升空间,我们增加对应的训练语料,以提升模型表现。
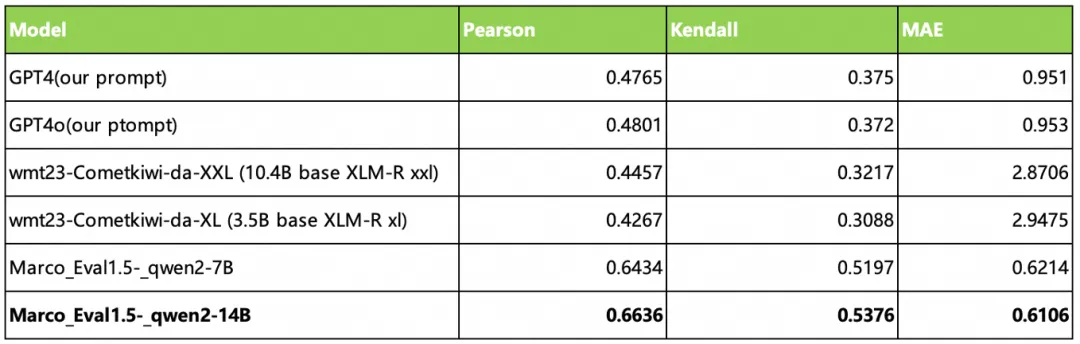
对于我们自身跨境电商业务,我们大量使用到 LLM 和 MLLM 能力,模型在跨境电商业务领域的 Benchmark 上的表现更加重要。模型在阿里国际的 AliExpress、Lazada、ICBU 等业务的商品翻译、营销、对话、搜索等业务表现,我们通过自研裁判模型,结合 RAG、Prompt Engineering 手段,进行模型业务领域的上线前评测、多版本效果比对、上线后日常巡检、BadCase 识别及归因分析。基于 Qwen 训练的裁判模型,在 Pearson、Kendall、MAE 等各个维度都能很好的进行自动化评测,并且还在不断优化迭代中。
在一次模型迭代过程,我们往往会经历多个步骤,下图是一个日常模型迭代的 case
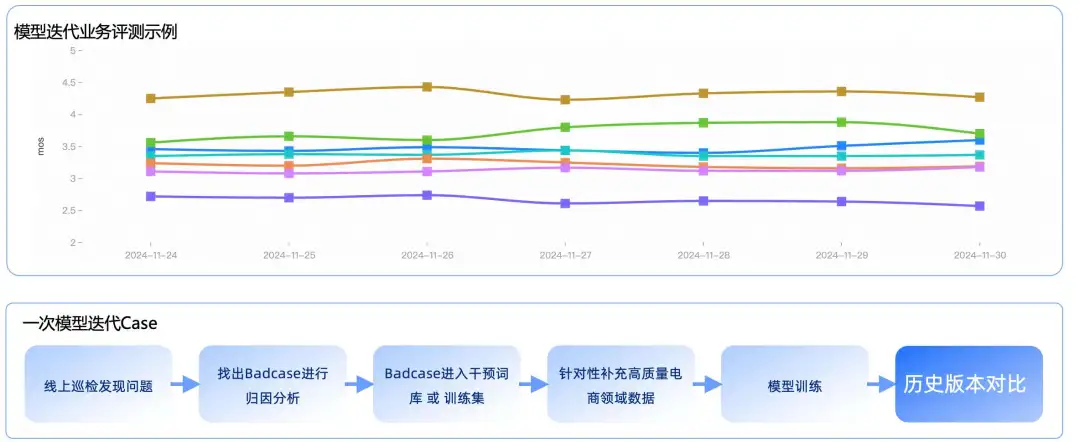
在每一次模型迭代发布,我们会对历史业务数据对模型效果进行回放,只有效果由于上一个版本,模型才能被允许发布。
自 ChatGPT 3.0 发布两年多的时间以来,大语言模型和多模态模型的基础能力越来越强,越来越多的企业转向大模型为核心的 AI 系统构建,去服务和拓展业务。
AI 应用系统的构建,对大模型数据提出了更高的挑战。在 Foundation Model 研发阶段,大模型数据核心是在数量、质量、多样性上满足模型训练的要求。而 AI 应用研发上,大模型数据在于专业领域上更高质量的数据,这里有两个最基本的挑战
一是从海量数据中清洗出某一业务领域数据。从海量数据清洗出指定业务数据,从算力算法上都是提出了更高的要求,需要有更多的算力,更精准的算法做识别,比如要从百亿图片中挑选出国画风格的图片,需要对全部图片进行一次扫描,对这一风格确定算法有较好的表现,又如从 PB 级千万亿 Token 文本数据中清洗出幽默、冷笑话并剔除黄色暴力内容的语料,其计算量巨大,其文本内容理解能力求更高。
二是业务领域数据的整合清洗与质量提升。每一个企业内部都有各种数据沉淀,包括需求文档、设计文档、产品使用手册、代码库、上线记录、客户服务、生成交易、机器资源、人员管理、客户管理等各种各样的数据,处理这些数据不仅仅是格式清洗任务、内容上的聚合任务,更大的难点在于数据的业务含义的链接,如需求文档与产品功能的链接,产品功能与上线记录的链接,产品功能与用户行为的链接等。在大模型为核心的 AI 时代,这些未被数据仓库覆盖的数据无疑是宝贵资产。
从 Foundation Model 到 AI 应用,从大规模训练到业务领域的 Post Training,从广泛数据到业务领域数据,对数据提出了更高的要求和挑战,让我们一起探索、实践大模型应用数据,迎接 AI 应用的遍地开花吧。
(文:AI前线)