
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今天凌晨,阿里巴巴发布了最新视觉多模态模型——Qwen2.5-VL。
与之前版本相比,在图像、文本、视频的理解、识别能力更强之外,Qwen2.5-VL最大特色就是可以直接作为一个视觉 Agent来自动化操作电脑、手机。例如,根据你的行程日期,自动帮你预订飞机票。
此外,Qwen2.5-VL还能理解超过1小时的长视频,并且能定位特定时间点发生的事件。例如,在安防领域,能快速定位到有人闯入、火灾发生等关键事件的视频片段,可极大节省审阅视频的时间。
开源地址:https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
Github:https://github.com/QwenLM/Qwen2.5-VL
在线体验:https://chat.qwenlm.ai/
对于中国又开源了新模型,网友感慨道,老铁们,歇一歇吧!让我们喘口气。我不知道中国人是不是一直赢都不觉得腻。

谢谢,这太棒了,中国的大模型。

绝佳的开源,恭喜!祝您中国节假日快乐!干杯!
我来自埃及。你们辛勤专注的工作,让我觉得生活更加美好,也让我看到世界的美好,为此我向你们致敬。值此中国春节之际,我想感谢通义千问团队。
说实话,Qwen被低估了。(伙计,通义千问一直是中国最强开源模型之一啊~)

视觉AI Agent
在OpenAI发布Operator后,凭借其庞大的用户基础和影响力,全球再次掀起了AI Agent热潮,并且一致认为2025将是智能体大年。
所以,阿里在新版本Qwen2.5-VL时把AI Agent作为主打功能之一,并支持视觉识别的这一点对于手机、电脑端操作很重要。
Qwen2.5-VL在大模型的理解、推理能力加持下,在准确率、执行效率方面有了很大提升。
例如,在订票应用程序中帮我预订一张单程机票。出发地是重庆江北机场,目的地是北京首都机场,日期是 1 月 28 日。
帮我查找一下英国曼彻斯特地区本月的天气预报。
除了常规应用之外,Qwen2.5-VL还能自动操作PS,例如,自动增强照片的色彩度。
强大的多模态视觉功能
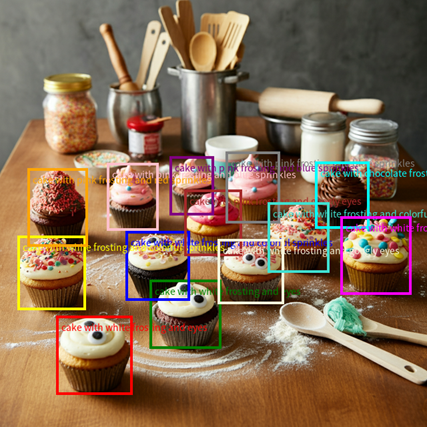
Qwen2.5-VL增强了其通用图像识别能力,大幅扩大了可识别的图像类别量级。不仅包括植物、动物、著名山川的地标,还包括影视作品中的IP以及各种各样的商品。

精准的视觉定位,Qwen2.5-VL 采用矩形框和点的多样化方式对通用物体定位,可以实现层级化定位和规范的 JSON 格式输出。这也为复杂场景中的视觉 Agent 进行理解和推理任务提供了强大基础。
超长的视频理解能力,Qwen2.5-VL 升级了视频理解能力,通过动态帧率(FPS)训练和绝对时间编码技术,能理解超长视频,定位秒级事件,还能在长视频中搜索具体事件、总结不同时段要点,帮用户快速提取关键信息。
模型简单介绍
与 Qwen2-VL相比,Qwen2.5-VL 增强了模型对时间和空间尺度的感知能力,并进一步简化了网络结构以提高模型效率。
在空间维度上,Qwen2.5-VL 不仅能够动态地将不同尺寸的图像转换为不同长度的 token,还直接使用图像的实际尺寸来表示检测框和点等坐标,而不进行传统的坐标归一化。使得模型能够直接学习图像的尺度。
在时间维度上,引入了动态 FPS (每秒帧数)训练和绝对时间编码,将 mRoPE id 直接与时间流速对齐。
视觉编码器在多模态大模型中扮演着至关重要的角色。我们从头开始训练了一个原生动态分辨率的 ViT,包括 CLIP、视觉-语言模型对齐和端到端训练等阶段。
为了解决多模态大模型在训练和测试阶段 ViT 负载不均衡的问题,我们引入了窗口注意力机制,有效减少了 ViT 端的计算负担。
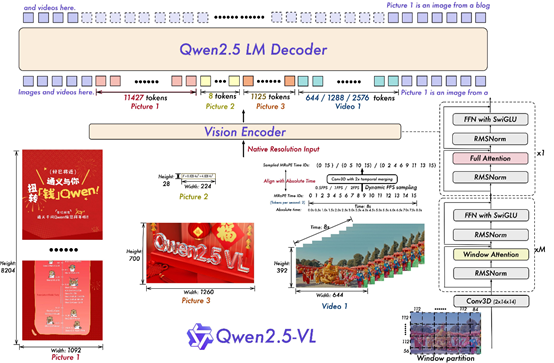
在ViT 设置中,只有四层是全注意力层,其余层使用窗口注意力。最大窗口大小为 8×8,小于 8×8 的区域不需要填充,而是保持原始尺度,确保模型保持原生分辨率。
此外,为了简化整体网络结构,使 ViT 架构与 LLMs 更加一致,采用了 RMSNorm 和 SwiGLU 结构。
(文:AIGC开放社区)