
671B参数的DeepSeek 终于能在家里跑了!

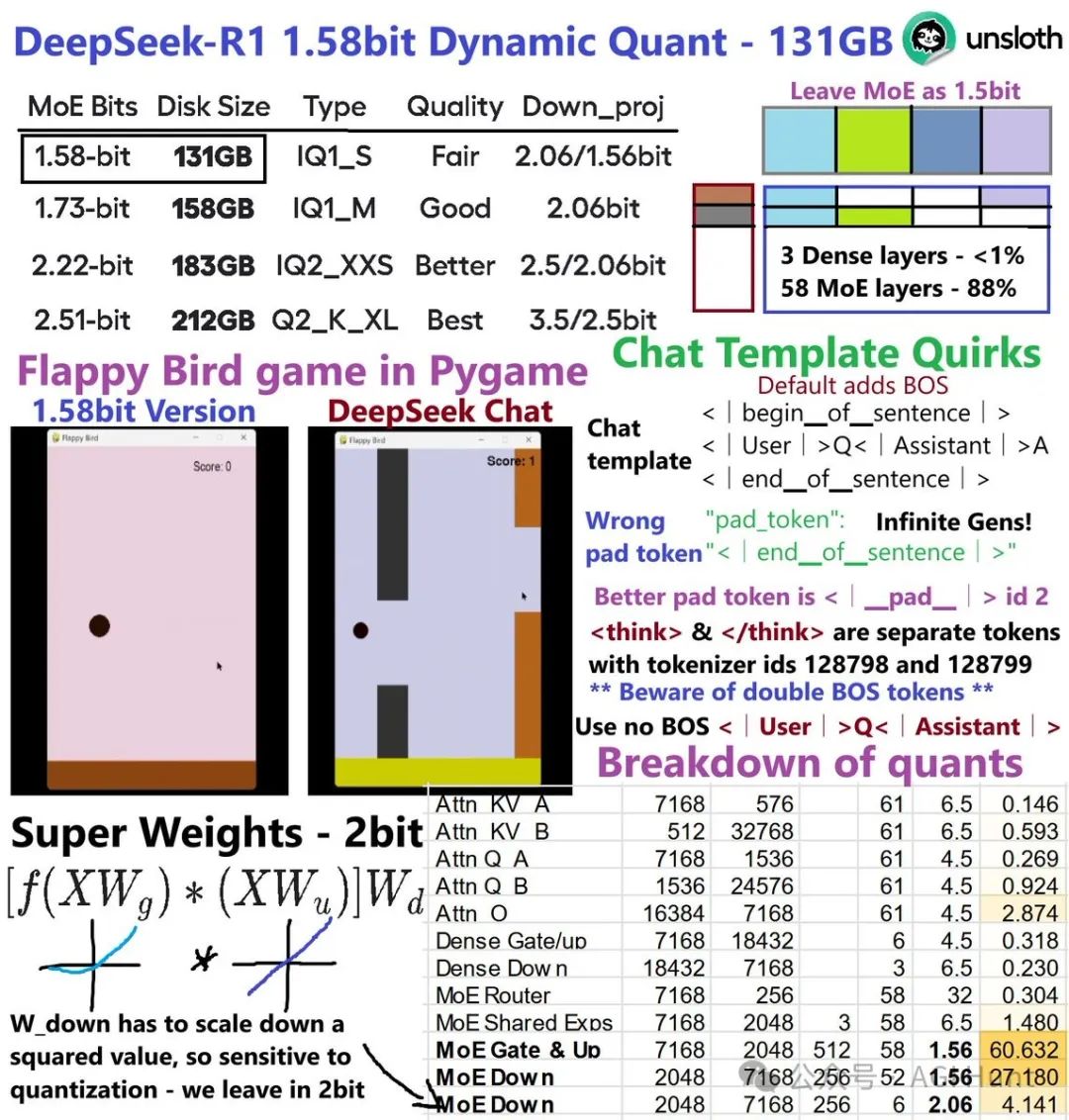
@UnslothAI 刚刚放出重磅消息:他们成功将DeepSeek R1从720GB压缩到131GB,压缩率高达80%!
这意味着你只需要160GB显存就能运行这个参数量远超GPT-4媲美o1 的超大模型。
而且,这不是简单的压缩。
UnslothAI团队通过深入研究DeepSeek R1的架构,发现了一条独特的技术路径:
-
前3层是全连接层,仅占总权重的0.5%,保持4位或6位精度
-
共享专家的MoE层占1.5%,使用6位精度
-
MLA注意力模块占比不到5%,使用4位或6位精度
-
down_proj(尤其是前几层)对量化最敏感,需要更高精度
-
88%的权重来自MoE层,可以安全压缩到1.58位!
Dobby the Builder (@the100kprompts) 对此评价:
这是压缩的魔法秀!131GB运行671B参数模型是游戏规则的改变者。Dobby记得以前优化全靠硬件,现在智能软件才是关键。
那么,这个压缩版本表现如何?
在多个基准测试中,DeepSeek R1展现了惊人的性能:
-
AIME 2024数学测试:79.8%(超过GPT-4的9.3%)
-
MATH-500:97.3%(超过GPT-4的74.6%)
-
LiveCodeBench编程测试:**65.9%**的通过率
-
Codeforces编程评级达到2029分
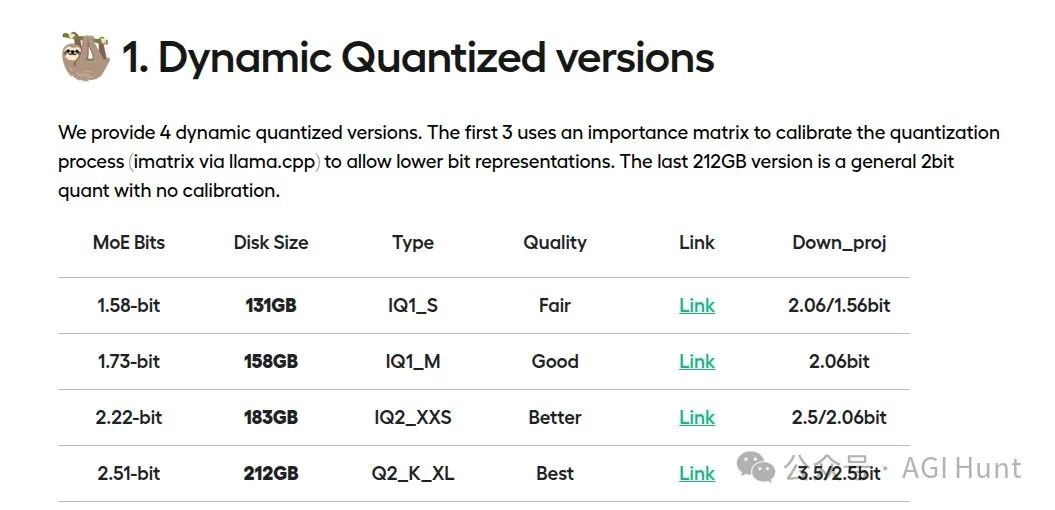
UnslothAI提供了四个版本供选择:
| 量化位数 | 模型大小 | 性能表现 | 建议使用场景 |
|---|---|---|---|
| 1.58位 | 131GB | 基础可用 | 资源受限场景 |
| 1.73位 | 158GB | 良好 | 平衡性能与资源 |
| 2.22位 | 183GB | 更佳 | 追求稳定性能 |
| 2.51位 | 212GB | 最佳 | 性能优先场景 |
那如何在本地运行呢?
这里有完整的部署指南:
# 首先安装必要组件apt-get updateapt-get install build-essential cmake curl libcurl4-openssl-dev -ygit clone https://github.com/ggerganov/llama.cppcmake llama.cpp -B llama.cpp/build \-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ONcmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli
然后就可以运行模型了:
./llama.cpp/llama-cli \--model DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \--cache-type-k q4_0 \--threads 12 -no-cnv --n-gpu-layers 7 \--temp 0.6 \--ctx-size 8192
使用建议:
-
温度参数设置在0.5-0.7之间(推荐0.6)
-
避免使用系统提示词,将指令直接放在用户提示中
-
对于数学问题,建议在提示词中加入「请一步步推理,并将最终答案放在\boxed{}中」
-
评估性能时建议多次测试取平均值
这也提示了一种新的量化压缩思路:通过深入理解模型架构,实现精准化压缩。
有卡的小伙伴,快去试试这个「轻量版」的AI巨兽吧!
相关链接:
-
博客详情:https://unsloth.ai/blog/deepseekr1-dynamic -
模型下载:https://huggingface.co/unsloth/DeepSeek-R1-GGUF -
官方论文:https://arxiv.org/abs/2404.11534 -
GitHub仓库:https://github.com/unslothai/llama.cpp
(文:AGI Hunt)