蛇年第一天,DeepSeek 带给硅谷科技圈的影响还在持续。
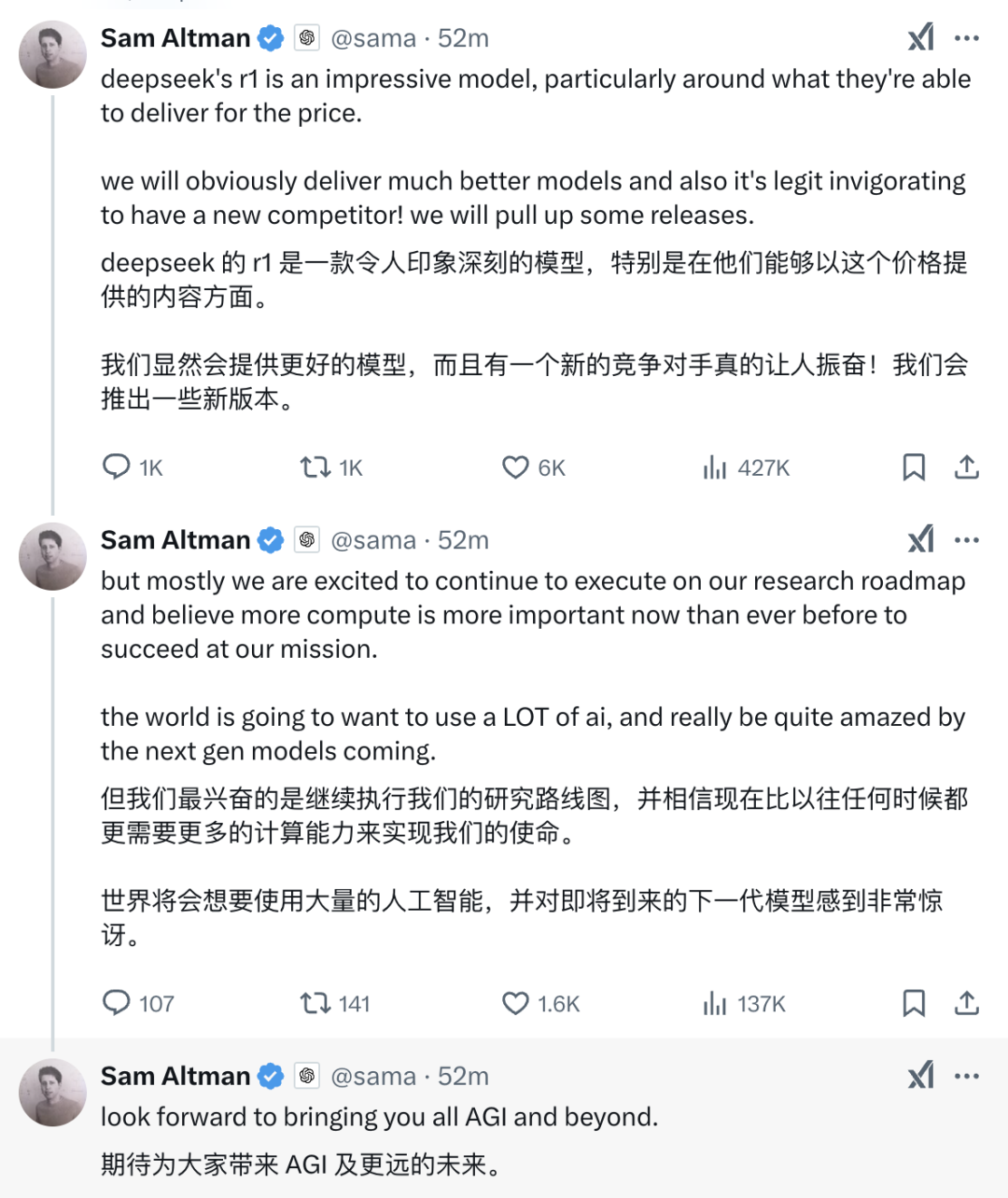
昨天 OpenAI CEO Sam Altman 连发多条推文谈对 DeepSeek 的看法,直言 R1 是一款令人印象深刻的模型,但也表示比以往任何时候都更需要更多的计算能力来实现 AGI 使命。
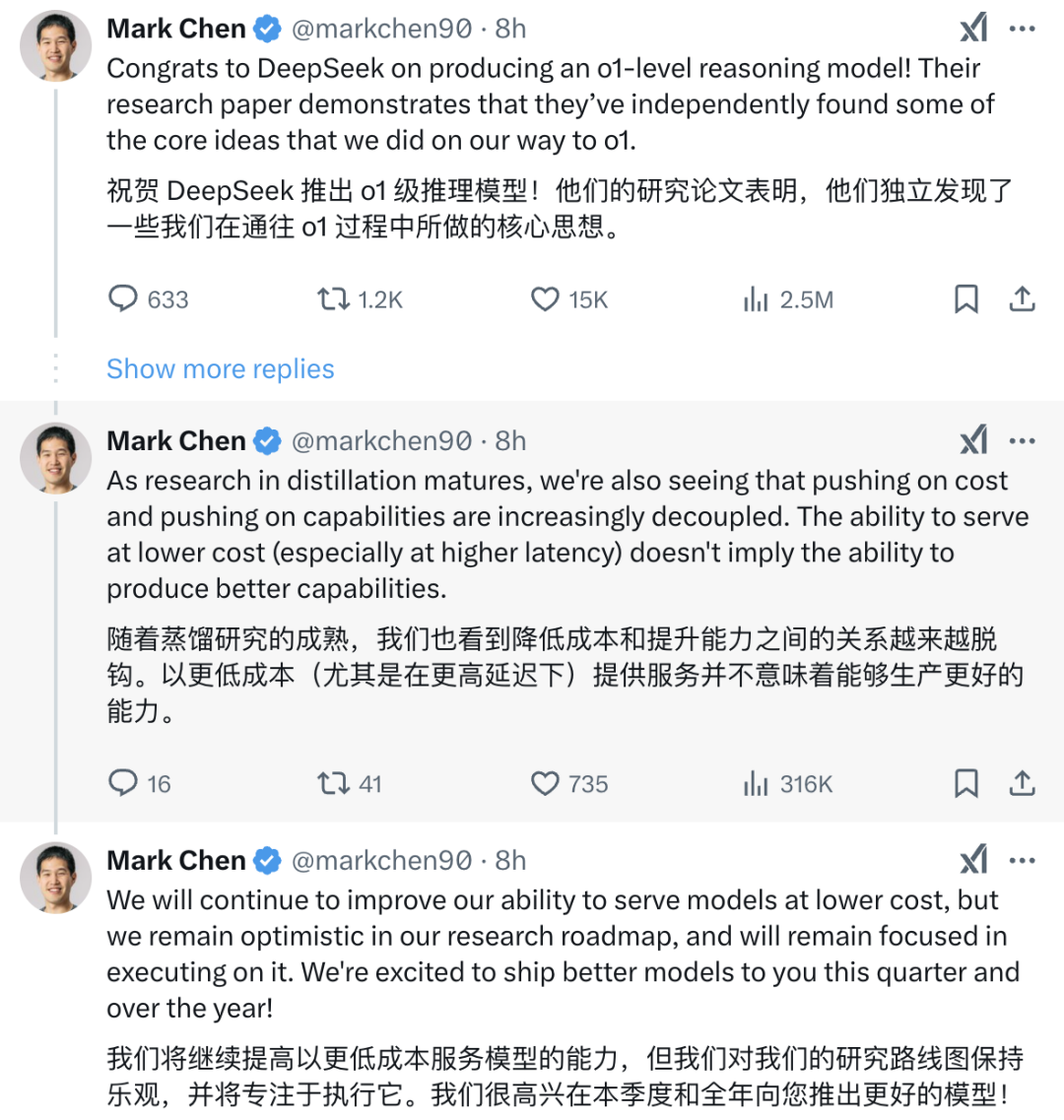
今天 OpenAI 首席研究官 Mark Chen 更是发表了一个更重磅的观察,他认为 DeepSeek 独立发现了 o1 模型的一些核心思路。
OpenAI 高管接连对一款中国大模型进行评价,这在大模型爆发的这两年都比较罕见。我们也让 DeepSeek R1 解读一番 Sam Altman 和 Mark Chen 对自己的看法。(不得不说光看 R1 的分析思路已经是一个不错的研究员)
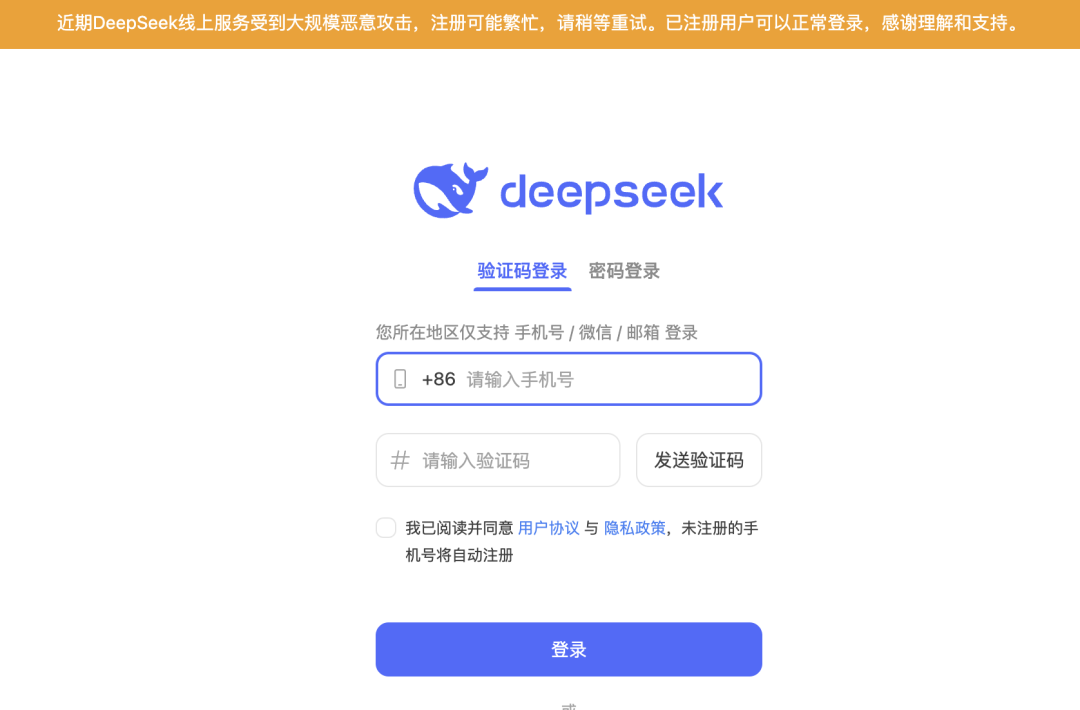
与此同时,一些诡异的故障也开始在 DeepSeek 出现,官网显示其线上服务受到大规模恶意攻击。
奇安信安全专家表示,1 月 27 日和 1 月28日攻击数量激增,并且攻击手段也再次升级,主要是暴力破解攻击,与此前的 DDos 攻击有明显不同,并且攻击 IP 全部来自美国。
如何解读 Sam Altman 对 DeepSeek 的看法
Altman 的态度并非单纯礼貌性恭维,而是基于 OpenAI 的底层战略:
开放性:欢迎竞争以扩大 AI 应用生态,但前提是 OpenAI 仍主导核心技术创新;
防御性:通过 AGI 叙事和算力壁垒,构建竞争对手难以复制的「技术代差」;
主动性:加速模型发布与技术展示,保持市场关注度与开发者黏性。
简言之,他对 DeepSeek R1 的认可是一种「降维打击式」的自信——承认局部创新,但坚信自身定义全局规则的能力。这种态度既是对行业趋势的精准回应,也是 OpenAI 维持领导地位的心理战策略。
1. 性价比突破Altman 特别强调 R1 的「令人印象深刻」之处在于其「价格与性能的平衡」。根据搜索结果,R1 的 API 价格仅为 OpenAI o1 模型的 1/30(每百万 token 2.19 美元 vs. 60 美元),但其推理能力在数学(如 AIME 测试)、代码生成等领域已接近 o1 的水平。这种成本优势源于其创新的训练方法:例如,港科大团队仅用 7B 参数的模型和 8000 个数学示例,便通过强化学习实现了与大型模型相当的推理能力。Altman 的认可暗示,低成本技术路径的可行性已被验证,但 OpenAl 并未将其视为威胁核心竞争力的关键。
2. 技术路径的差异化Altman 并未直接评价 R1 的技术细节,但从其「下一代模型将令人惊叹」的表述可推测,OpenAI 认为自身技术路线(如 AGI 探索)与 R1 的「效率优先」策略存在差异。例如,R1 依赖强化学习与规则奖励机制简化训练流程,而 OpenAI 的 o3 模型已展示出对复杂科学问题的博士级解决能力(准确率 87.7%),更强调能力的泛化与深度。
1. 竞争态度的转变Altman 称「新竞争对手的加入令人振奋」,这与 OpenAI 过往对开源模型的谨慎态度形成对比。这一转变或源于 R1 带来的行业变革:其开源策略(如模型权重开放)已催生 500 多个衍生项目,下载量达数百万次,甚至导致部分 OpenAI 用户转向其平台。Altman 的回应既是对市场压力的承认,也暗示 OpenAI 将通过技术壁垒(如 AGI 布局)而非价格战应对竞争。
2. 对行业生态的连锁影响R1 的发布引发美股 AI 产业链震荡(英伟达股价暴跌 17%),反映出市场对「算力需求可能降低」的担忧。然而,Altman 强调「计算能力比以往任何时候都更重要」,表明 OpenAI 仍将依赖算力密集型技术路线(如更大规模的预训练)。这种矛盾折射出行业的两极分化:开源生态追求效率,闭源巨头押注技术纵深。
1. 强化技术领导地位Altman 明确表示「将推出更好的模型」并「加快发布进度」,这可能是对 R1 的直接回应。例如,OpenAI 在 R1 发布后迅速宣布向免费用户开放 o3-mini 的访问权限,试图通过降低准入门槛维持市场份额。同时,其「继续执行研究路线图」的表述指向 AGI 目标,暗示未来模型将更注重能力的广度(如跨领域推理)而非单纯效率优化。
2. 对算力需求的重新定义Altman 强调「需要更多计算能力完成使命」,这与 R1 展示的「小模型高效训练」形成对比。OpenAI 可能认为,AGI 的实现仍需依赖超大规模算力(如万卡集群),而非算法优化。这种观点得到英伟达的支持——其发言人指出,R1 的推理仍需「大量 GPU 支持」,间接为算力需求辩护。
1. 技术民主化的加速R1 的成功证明,通过算法创新(如强化学习规则奖励机制),中小团队也能以低成本实现高性能模型。港科大、UC 伯克利等开源项目已验证其核心方法,甚至 1.5B 参数的小模型已展现自我验证能力。这种趋势可能削弱巨头垄断,推动 AI 应用层创新爆发。
2. 闭源与开源的长期博弈Altman 对 R1 的认可,实则是对开源生态崛起的策略性回应。OpenAI 选择保持闭源以保护技术优势(如 o3 的 AGI 潜力),而 R1 通过部分开源吸引开发者生态。这种分化或催生两种技术范式:开源社区主导的垂直领域优化 vs. 闭源巨头主导的通用能力突破。
关注 AI 第一新媒体,获取 AI 最新资讯和洞察
Mark Chen的评论既是技术层面的肯定,也是竞争态势的宣示:
认可:DeepSeek通过独立创新在推理模型领域达到国际顶尖水平,并验证了开源与低成本路线的可行性。
竞争:OpenAI仍将押注技术深度(如AGI广度)与生态整合,认为长期竞争力来自「不可复制的核心突破」,而非短期成本优势。
行业趋势:这场对话折射出AI行业的两大方向——开源模型的普惠化与闭源模型的技术纵深,两者或将共同推动AI向更高效、更智能的方向演进。
1. 技术独立性与创新性Mark Chen祝贺DeepSeek开发出与OpenAI o1同级别的推理模型(如R1),并强调其「独立发现」了与o1开发过程中相似的核心技术思路。这暗示DeepSeek在推理模型的底层逻辑(如强化学习、数据蒸馏技术)上与OpenAI存在技术路径的趋同性。例如,DeepSeek R1通过直接应用强化学习(无需监督微调)和高效数据蒸馏,显著降低了训练成本,同时在数学、代码等推理任务中达到或超越o1的表现。
技术对标:DeepSeek R1在AIME数学测试中得分率略高于o1(79.8% vs. 79.2%),且训练成本仅为OpenAI的十分之一,体现了其技术创新与工程优化能力。
2. 蒸馏技术的成熟与局限性Mark Chen提到「成本优化与能力提升逐渐解耦」,即通过蒸馏等技术降低服务成本(如DeepSeek的API价格仅为OpenAI的1/30)并不意味着模型能力的绝对提升。这一观点既承认了DeepSeek在成本控制上的成功,也暗示OpenAI认为其自身的技术路线(如推理的Scaling Law)更可能突破能力上限。例如,OpenAI的o3模型已在复杂科学问题中超越人类专家,而DeepSeek尚未达到这一深度。
1. 开源与闭源的博弈DeepSeek的开源策略(如R1模型完全开放)对OpenAI的闭源商业模式构成挑战。Mark Chen的评论可视为对开源生态崛起的回应。例如,Meta等公司因担心Llama 4落后于DeepSeek而加速研发,而OpenAI则通过强化技术壁垒(如推出o3模型)和生态整合(如与苹果合作)巩固优势。
– 市场影响:DeepSeek的低成本开源模型已吸引大量开发者,甚至导致部分OpenAI客户转向其平台。
2. 推理能力的竞争焦点OpenAI通过o系列模型定义了「推理时代」的技术范式(如思维链分解与强化学习),而DeepSeek的追赶表明行业正从「参数规模竞赛」转向「推理效率优化」。Mark Chen的言论暗示,OpenAI仍将专注于通过更复杂的研究(如AGI的广度泛化)保持领先,而非单纯比拼成本。
1. 长期技术路线的信心Mark Chen强调OpenAI将继续推进研究路线图,并计划推出「更好的模型」。这指向其核心战略:通过技术深度(如o3的AGI潜力)而非成本优势巩固地位。例如,o3在博士级科学考试中准确率达87.7%,远超人类专家,而OpenAI认为此类能力泛化至日常场景才是AGI的关键。
2. 成本优化的务实态度尽管OpenAI承认需降低服务成本(如o3的高计算费用仍是落地障碍),但其更关注「能力提升」与「商业闭环」的结合。例如,通过强化微调功能吸引企业开发者,而非直接参与价格战。
很多用户已经发现,与 DeepSeek 沟通的提示词策略和之前和 ChatGPT 等 AI 已经有所不同,可以更简单直接,欢迎大家在留言区分享使用 DeepSeek 的小技巧。
最后祝大家蛇年大吉,巳巳如意
(文:APPSO)