
-
语言模型大小:较大的模型(如45B参数模型)在TruthfulQA上表现更好,但在MMLU上提升有限。
-
提示设计:有益的提示(如HelpV2和HelpV3)显著优于对抗性提示,表明提示设计对性能有重要影响。
-
文档块大小:文档块大小对性能影响较小,较大的块(如192个token)略好。
-
知识库大小:知识库大小对性能影响不显著,表明知识库的质量和相关性比大小更重要。
-
检索步长:较大的检索步长(如每5步更新一次)有助于保持上下文连贯性。
-
查询扩展:查询扩展对性能提升有限,但在TruthfulQA上略有改善。
-
对比式上下文学习:使用对比示例(正确与错误答案)显著提升了模型的准确性和相关性。
-
多语言知识库:多语言知识库降低了性能,可能是由于模型难以有效整合多语言信息。
-
聚焦模式:仅提取最相关的句子可以显著提升性能,尤其是在MMLU数据集上。
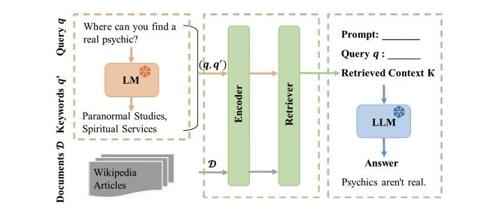
实验设计架构,提出了9个研究问题,并设计了相应的RAG系统变体进行实验,代码已开源。RAG系统包含三个主要模块:查询扩展模块、检索模块和文本生成模块。
-
查询扩展模块:使用Flan-T5模型扩展用户查询,生成相关关键词。 -
检索模块:使用FAISS进行高效相似性搜索,从知识库中检索相关文档。 -
文本生成模块:基于检索到的上下文和用户查询生成响应。
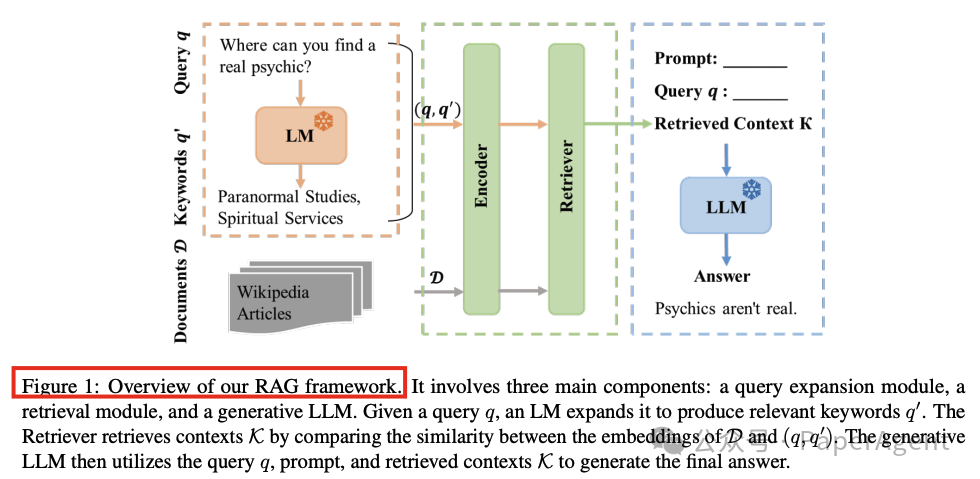
RAG变体性能比较,基于TruthfulQA和MMLU数据集进行评估。设置包括:语言模型大小(LLM Size)、提示设计(Prompt Design)、文档大小(Doc Size)、知识库大小(KW. Size)、检索步长(Retrieval Stride)、查询扩展(Query Expansion)、对比式上下文学习知识库(Contrastive ICL)、多语言知识库(Multilingual)和聚焦模式(Focus Mode)。R1、R2、RL和ECS分别表示ROUGE-1 F1、ROUGE-2 F1、ROUGE-L F1和嵌入余弦相似度分数。加粗的分数表示与基线(即Instruct7B RAG)相比具有统计显著性。
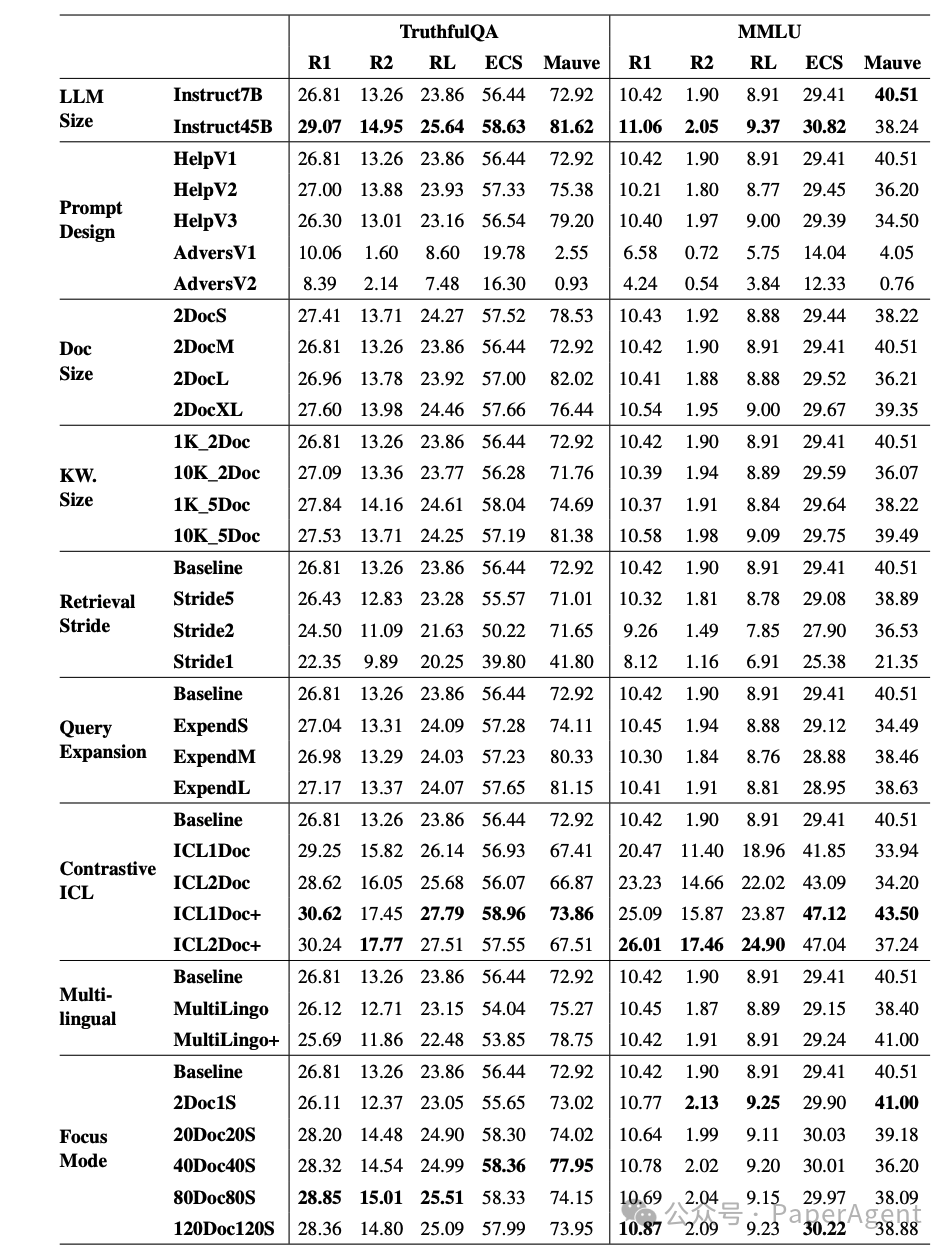
在TruthfulQA和MMLU数据集上生成的结果示例,其中“w/o_RAG”表示没有RAG系统的基础LLM。变体HelpV2(HelpV3)、2DocXL、1K_5Doc、ExpendL、ICL1D+以及80Doc80S(120Doc120S)分别代表提示设计、文档大小、知识库大小、查询扩展、对比式上下文学习和聚焦模式部分的最佳配置。
https://arxiv.org/pdf/2501.07391Enhancing Retrieval-Augmented Generation: A Study of Best Practiceshttps://github.com/ali-bahrainian/RAG_best_practices
(文:PaperAgent)