
Datawhale分享
作者:Mike Knoop,编译:机器之心
Datawhale分享
作者:Mike Knoop,编译:机器之心
R1-Zero 等模型正在打破人类数据瓶颈,开启 AI 自我进化新范式?

-
通过投入更多计算资源,AI 系统的准确性和可靠性可以显著提升,这将增强用户对 AI 的信任,推动商业化应用。
-
推理过程正在生成大量高质量的训练数据,且这些数据由用户付费产生,这种「推理即训练」的新范式可能彻底改变 AI 数据经济的运作方式,形成自我强化的循环。
-
为问题域生成思维链(CoT)。
-
使用人类专家(「监督微调」或 SFT)和自动化机器(强化学习(RL))的组合来标注中间 CoT 步骤。
-
使用(2)得到的数据训练基础模型。
-
在测试时,从过程模型中进行迭代推理。
-
在 CoT 过程模型训练中添加人类标签(即 SFT);
-
使用 CoT 搜索而不是线性推理(并行逐步 CoT 推理);
-
整体 CoT 采样(并行轨迹推理)。
-
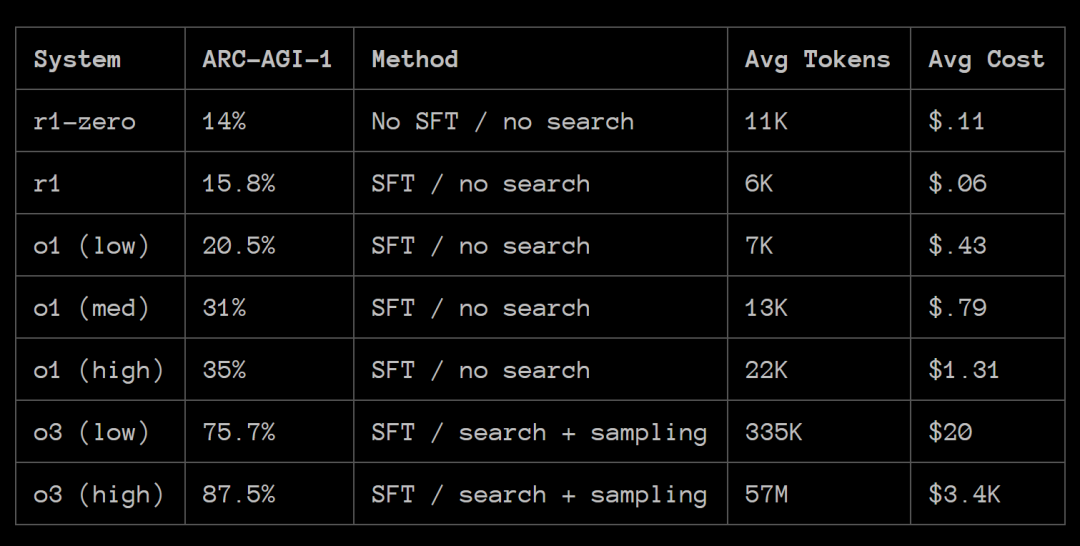
在那些能够清晰判断对错的领域中 ,SFT(如人类专家标注)对于准确和易读的 CoT 推理并非必需。
-
R1-Zero 训练过程能够通过 RL 优化在 token 空间中创建自己的内部领域特定语言(DSL)。
-
SFT 是提高 CoT 推理领域泛化性的必要条件。
-
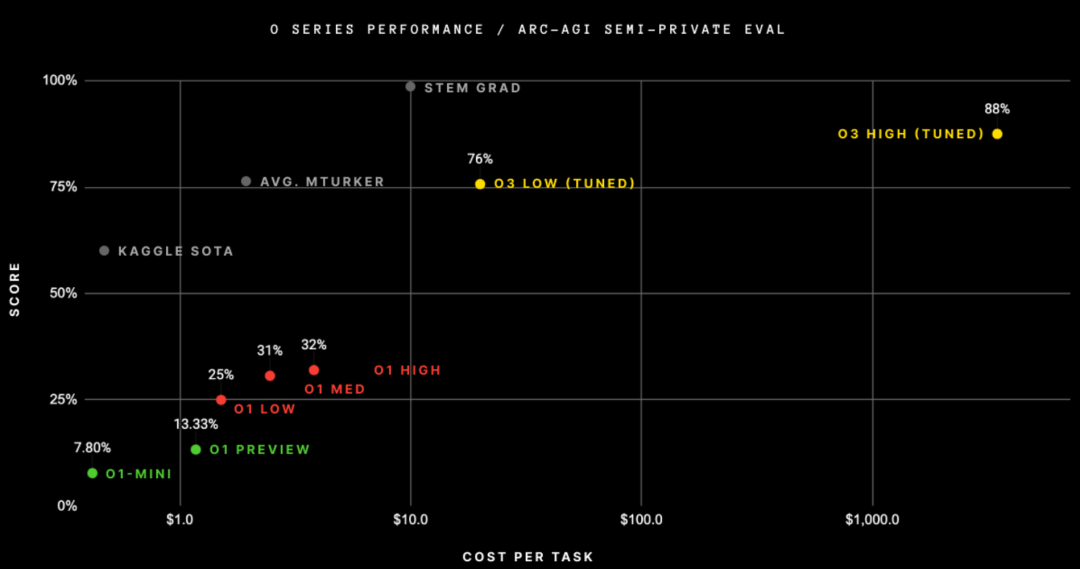
现在可以花更多钱来获得更高的准确性和可靠性;
-
训练成本正在转向推理成本。
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)