专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
东京大学、清华大学、庆应义塾大学等研究人员联合开发了创新模型——EMAGE。
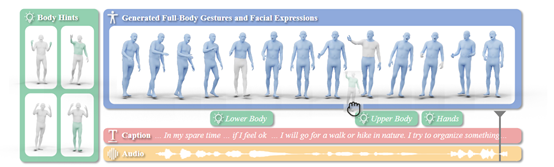
EMAGE可以根据音频自动生成连贯、逼真、一致的全身动作、面部表情和手部动作的共语手势视频。例如,上传一段歌曲或者旁白的音频,就能生成一个带丰富动作的视频。这可以帮助数字人等应用生成更精准的动作手势和表情。
此外,研究人员还发布了目前最大的“共语手势”
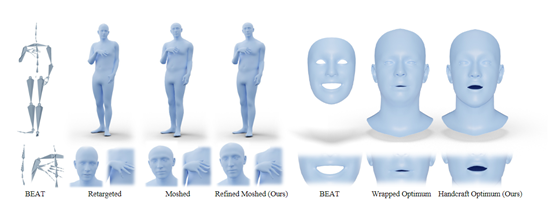
数据集BEAT2。该数据集整合了SMPLX人体模型和FLAME面部模型,将原始的动作、面部捕捉数据转换为高质量的全身三维网格序列,总时长超过60小时。
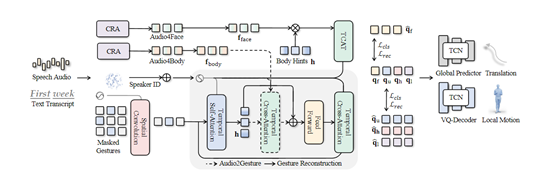
EMAGE主要通过遮罩手势重建特征以增强人体提示编码能力,并与音频特征相结合,生成面部表情、手部动作和身体动作一致的共语手势。
与同类的TalkShow、DisCo、CAMN、HA2G等模型相比,EMAGE的节奏一致性、多样性和面部顶点差异等表现的更出色。测试数据显示,在人工评估中,52.7%的用户认为EMAGE生成的全身共语手势更加连贯、丰富。
输入的音频
为了更好地融合音频的节奏和语义内容信息,EMAGE采用了内容节奏自注意力(Content Rhythm
Self-Attention)技术,可将音频的节拍编码为节奏特征,语音文本的预训练词嵌入编码为内容特征。
然后通过自注意力机制自适应地融合节奏和内容特征,然后生成面部和身体的音频特征。
这种自适应融合设计方法的好处是,对于特定的帧姿势往往更多地与节奏或内容相关,而CRA允许模型在不同时刻关注节奏或内容,从而生成更加语义感知和节奏驱动的姿势。
EMAGE使用了四个独立的VQ-VAE编码器对面部、上半身、手部和下半身运动进行建模,比单个VQ-VAE对整体身体建模更丰富、精准。
例如,面部和下半身与音频的相关性不同,将它们与上半身和手部分开可以更好地捕捉与音频相关的运动,可以更好地重建身体细节。
每个VQ-VAE编码器将输入姿势序列编码为离散的潜在表示,再利用解码器将潜在表示重建为该部位的运动,可以在训练时使用重建损失、速度损失和加速度损失等多个目标函数。
掩蔽音频姿势转换可帮助EMAGE从被掩蔽的姿势中编码身体线索,从部分可见的姿势中捕获身体的不规律运动特征。这也是将身体运动与音频相结合的重要模块,主要由掩蔽姿势重建和音频条件姿势生成两大块组成。
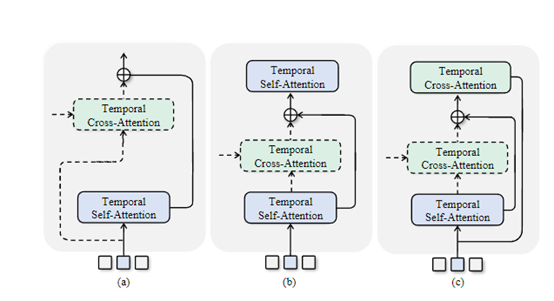
掩蔽姿势重建:首先使用空间卷积编码器总结空间信息,然后采用时间自注意力提取时间特征。最后使用时间交叉注意力解码器重建输入的潜在身体姿势表示。这也是通过最小化重建损失,学习编码身体线索的最有效方式。
音频条件姿势生成:使用了一个可选的时间交叉注意力模块来选择性地融合身体线索和音频特征,然后使用融合的特征通过解码器重建潜在的姿势表示。音频条件姿势生成主要是通过掩蔽姿势重建获取身体线索,然后结合内容节奏自注意力的音频特征,来生成身体姿势丰富的特征。
此外,由于面部与身体动作相关性较弱,EMAGE直接将身体线索与音频特征进行拼接,来生成更精细、精准的面部表情。
(文:AIGC开放社区)