

新智元报道
新智元报道
【新智元导读】人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
那么,如果AI也能这样学习呢?

图1 Video-MMMU提出知识获取的3大认知阶段
这正是Video-MMMU试图回答的核心问题:AI能否通过观看视频获取并应用知识?
对于多模态大模型(LMMs)来说,视频不仅是它们感知世界的窗口,更是获取知识的重要途径。南洋理工大学S-Lab团队推出Video-MMMU数据集是首个评测LMMs从多学科专业视频中提取、理解并运用知识能力的创新基准。
通过Video-MMMU,我们不再满足于模型「看懂」视频,而是探索它能否真正「学会」视频中的新知识,并运用这些知识解决实际问题。

数据集:https://huggingface.co/datasets/lmms-lab/VideoMMMU
三大认知阶段:从感知到应用
感知(Perception)——信息获取的起点,模型需要从视频中提取关键信息,这是获取知识的基础。

理解(Comprehension)——从感知到掌握,模型不仅需要「看清」,还要理解知识的深层次含义。


知识增益(∆knowledge):衡量模型的能力提升
Video-MMMU 的另一大亮点在于设计了「知识增益」(∆knowledge)指标。这一创新不仅关注模型的「绝对能力」,更评估其在观看视频前后的在应用阶段的表现提升。

数据集的独特性
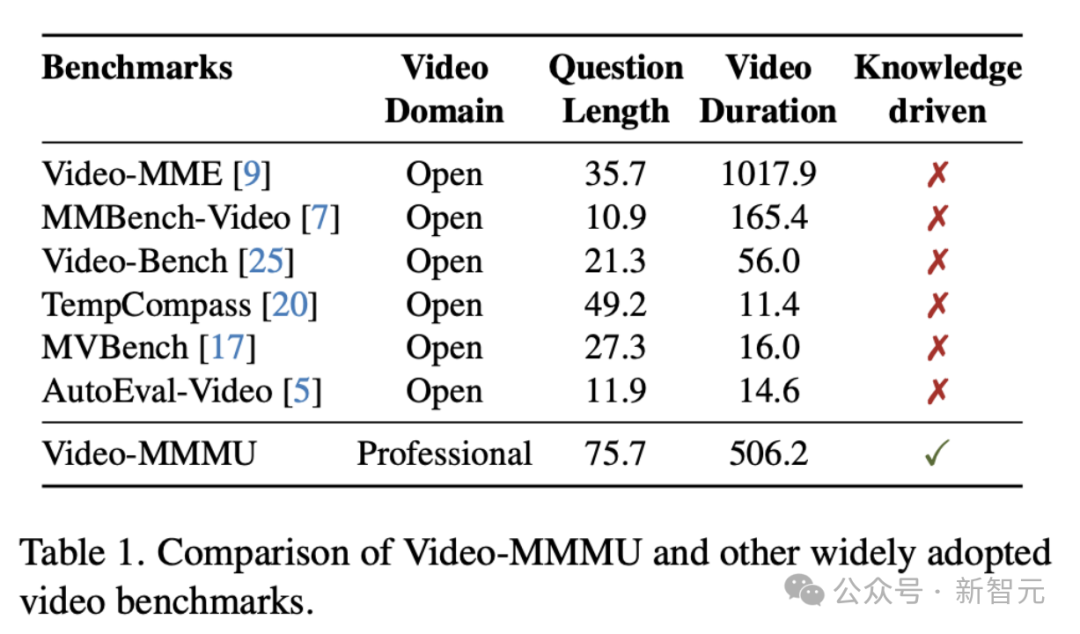
Video-MMMU的独特之处在于首次将视频作为知识传播的核心渠道,从传统的视频场景理解转向视频内容的知识学习。数据集专注于高质量教育视频,平均时长506.2秒,覆盖多个学科领域。其问题平均长度达75.7字,远超其他基准,体现出高度专业性和挑战性。
数据集设计
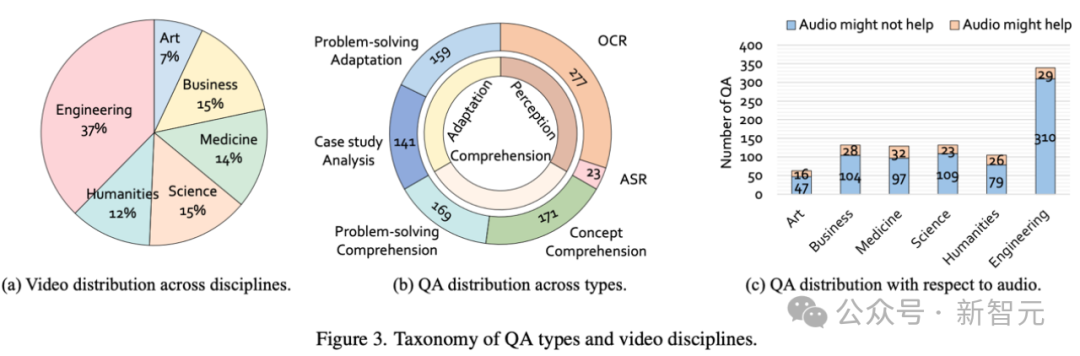
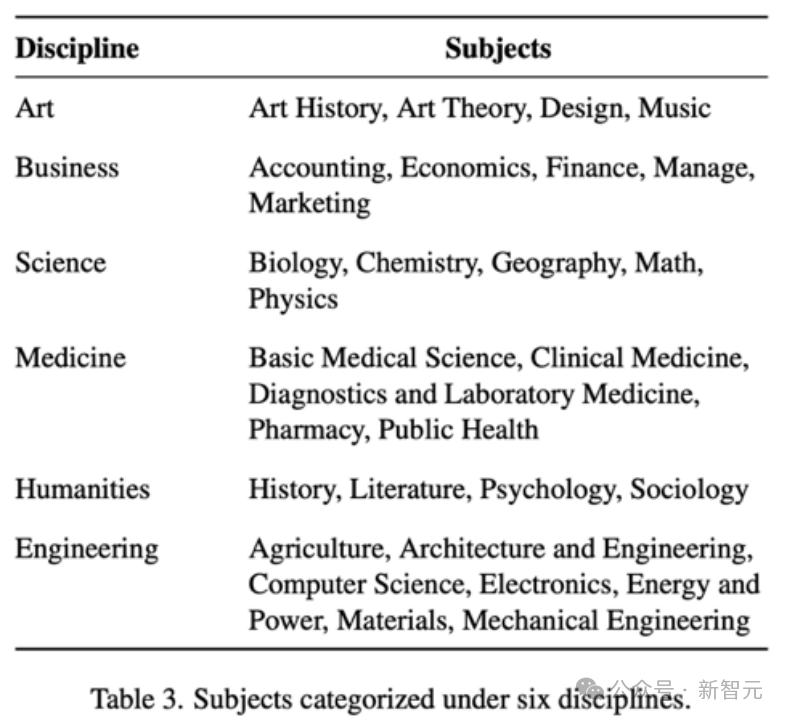
Video-MMMU覆盖6大专业领域(艺术、商业、医学、科学、人文、工程)中的30个学科。数据集包含精心筛选的300个大学水平的教育视频和900个高质量的问答对。
问题设计

感知阶段的问题类型
-
ASR(自动语音识别):要求模型准确转录视频中的口述内容。示例:如上图中Art(左上)的例子。
-
OCR(光学字符识别):从公式、图表或手写笔记中提取关键细节。示例:如上图中Business(左下)的例子。
理解阶段的问题类型
-
概念理解(Concept Comprehension):通过不定项选择题评估模型对视频中概念的理解。示例:如上图中Humanities(中上)的例子。
-
解题方法理解(Problem-solving Strategy Comprehension):在视频中演示的解决问题基础上,通过改变输入值测试模型是否掌握了解题方法。示例:如上图中Science(中下)的例子。
运用阶段的问题类型
-
案例分析(Case Study Analysis):将视频中讲解的知识应用于新的实际情境。示例:如上图Medicine(右上)的例子。
-
解题方法运用(Problem-solving Strategy Adaptation):将视频中演示的解决方法应用于实际的问题。示例:如上图中Engineering(右下)的例子。
实验结果分析
各认知阶段的表现
-
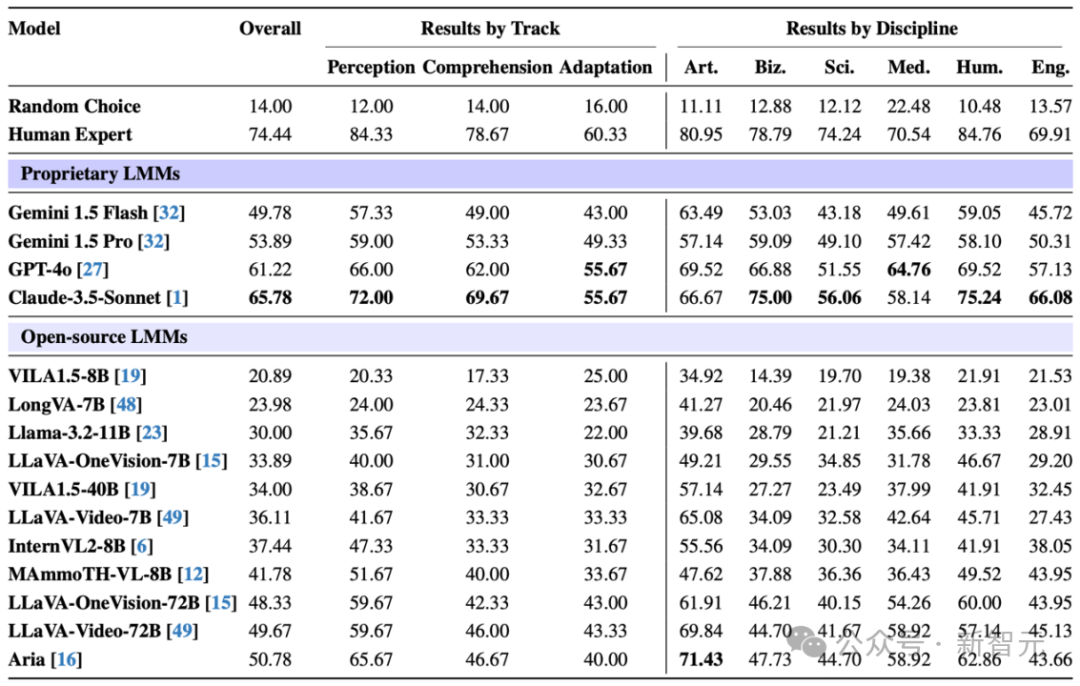
人类 vs. AI:人类专家在所有阶段的表现都优于模型,尽管Claude-3.5-Sonnet在模型中得分最高,但仍明显落后于人类。
-
难度逐级递增:无论是人类还是AI,从感知到理解再到运用,准确率逐步下降,说明越深层次的认知任务对能力要求越高。
-
知识运用的挑战:运用阶段(Adaptation Track) 是知识获取的最大瓶颈,模型得分普遍低于50%。这表明,尽管模型在可能表面理解了视频知识,但在实际应用时仍存在明显短板,难以灵活迁移和运用所学内容。
音频文本的影响
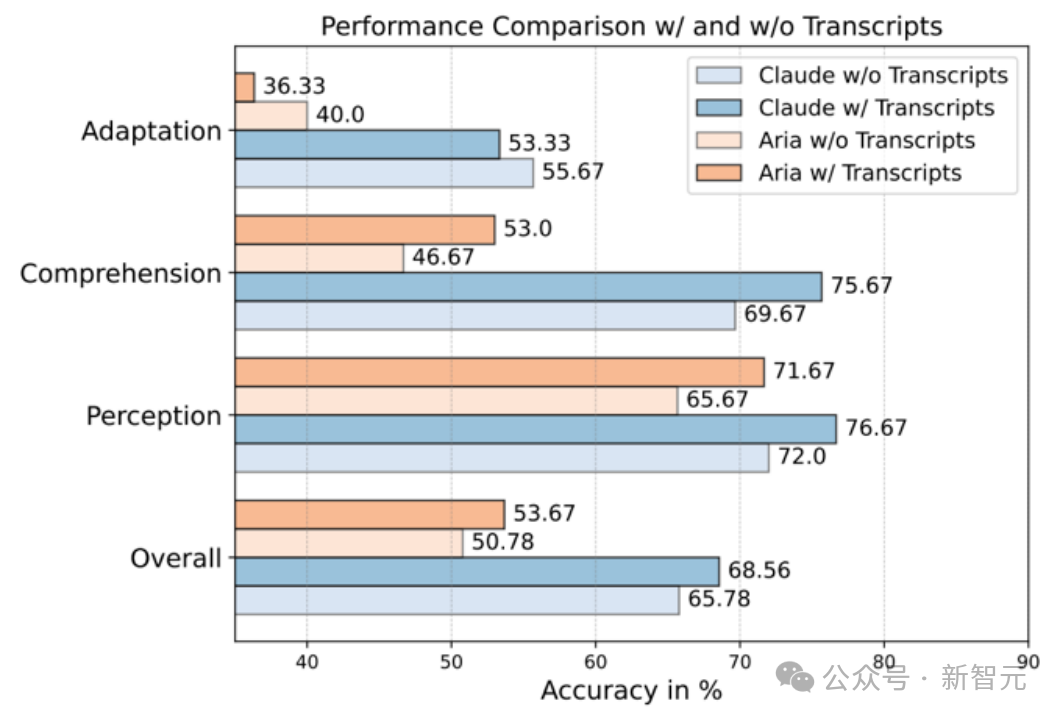
-
感知与理解阶段:音频文本有助于模型更精准地理解视频内容,提高表现。
-
运用阶段的挑战:模型表现反而下降,可能因为音频中存在冗余信息,干扰了模型对关键知识的提取和迁移能力。这说明,尽管音频文本能帮助AI“听懂”视频,但真正的知识应用依然是重大挑战。
知识增益的定量分析
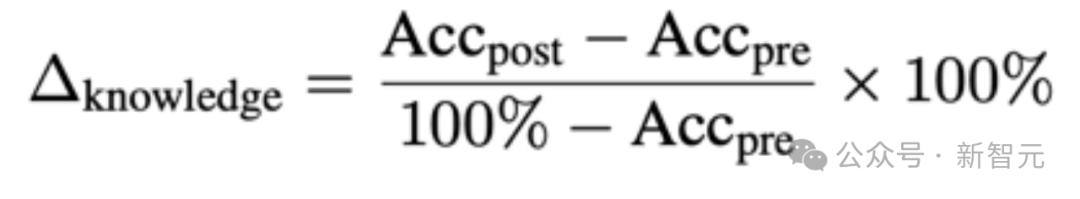
人类 vs. AI:学习能力差距
人类在观看视频后,知识增益达33.1%,而表现最好的模型(GPT-4o)仅为15.6%,多数模型低于10%。更令人意外的是,一些模型在观看视频后反而表现下降,表明它们在知识学习和应用方面仍远不及人类。

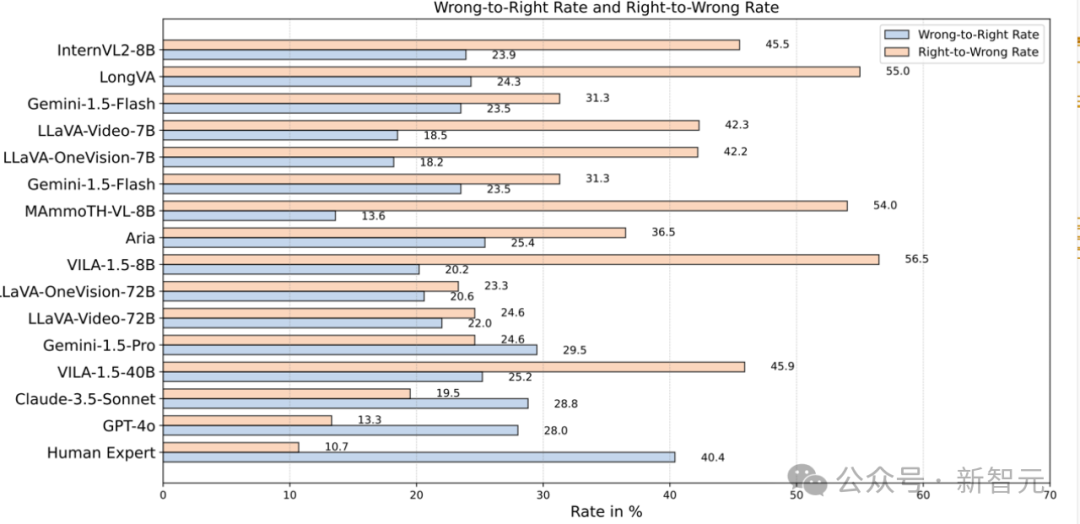
模型的知识获取两面性
-
错误转正确率(Wrong-to-Right Rate):模型能否通过视频学习,把原本错误的答案修正?定义为:
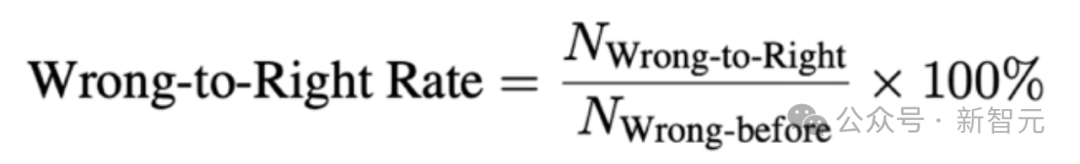
-
正确转错误率(Right-to-Wrong Rate):模型是否看视频之后,把原本做对的题做错了?
人类的认知优势
-
错误转正确率:40.4% → 说明人类能更有效地学习新知识。
-
正确转错误率:10.7% → 这表明,人类能够自然整合新旧知识,而模型在处理视频信息时,往往会修改原本正确的答案,这成为其学习能力的核心短板之一。
结论:模型的瓶颈
实验结果揭示了当前多模态大模型(LMMs)在视频学习中的两大挑战:
-
学习能力有限:难以高效获取并应用新知识。
-
模型回答的不稳定性:原本会做的题,看完视频后反而不会了。
错误分析
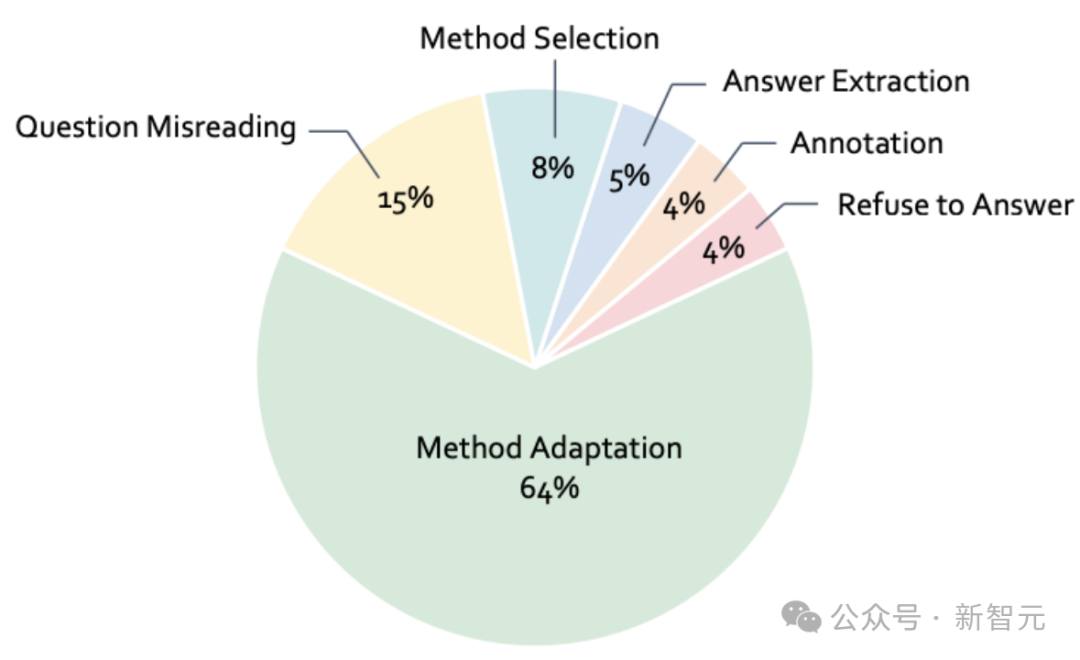
-
方法选择错误(8%):模型选择了错误的解题方法,也就是说,它未能理解视频中讲解的正确策略。简单来说,模型看了视频,但没有选对路。
-
方法运用错误(64%):这是最常见的错误。模型记住了视频中的方法,但在新情境下无法灵活应用。比如,它理解了视频中的解题方法,但无法正确运用到另一个场景中。
-
问题误读错误(15%):模型没读懂题目,比如错看了数值或条件。这些错误和知识获取无关,更像是「粗心大意」。

总结
Video-MMMU首次系统性评测了LMMs从视频中学习、理解和应用知识的能力,揭示了当前多模态大模型在学习效率和知识迁移上的显著不足。提升模型从视频中获取知识的能力,将是迈向AGI的重要一步。
(文:新智元)