

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
OpenAI在官网发布了最新的模型规范,希望可以进一步强化对可定制性、透明度以及探索、辩论和使用AI的智力自由的承诺。
在不设置任意限制的情况下,确保AI能够发挥其应有的作用,同时确保设置必要的防护措施,以减少真实伤害的风险。
本次模型规范是在去年5月发布的基础之上完成的,汲取了从对齐研究到为全球用户提供服务的各种场景中应用规范的众多经验。

目标和原则
OpenAI的目标是创建有用、安全且符合用户与开发者需求的模型,同时确保通用AI造福全人类的使命。为实现这一目标,需以迭代方式部署赋予开发者和用户能力的模型,同时防止我们的模型对用户或其他人造成严重伤害,并维持 OpenAI 的运营许可。
这些目标有时可能相互冲突,《模型规范》通过指示模型遵循明确定义的指令层级,以及为各种场景设定边界和默认行为的额外原则,来平衡它们之间的权衡取舍。此框架在明确界定的边界内,优先考虑用户和开发者的控制权:

指令层级:定义模型如何按顺序对来自OpenAI、开发者和用户的指令进行优先级排序。《模型规范》的大部分内容是我们认为在许多情况下有帮助的指南,但用户和开发者可以覆盖这些指南。这使用户和开发者能够在平台级规则设定的边界内,完全自定义模型行为。
共同探寻真相:如同一位正直诚信的人类助手,我们的模型应助力用户做出他们自己的最佳决策。这需要在两方面谨慎权衡:一是避免带着特定意图引导用户,默认保持客观,同时愿意从任何视角探索任何话题;二是努力理解用户目标,澄清假设和不确定细节,并在适当的时候给出批判性反馈 —— 这些都是我们收到的反馈并加以改进的地方。
尽善尽美:设定能力的基本标准,包括事实准确性、创造性和编程应用。
恪守边界:阐释模型如何在用户自主性与预防措施之间取得平衡,以避免助长伤害或滥用行为。这个新版本旨在做到全面,完整涵盖我们要求模型拒绝用户或开发者请求的所有原因。
亲和易近:描述模型默认的对话风格 —— 热情、富有同理心且乐于助人 —— 以及这种风格如何调整。
采用恰当风格:就格式和表达方式提供默认指导。无论是简洁的项目符号、精炼的代码片段还是语音对话,我们的目标都是确保清晰明了且易于使用。
维护知识自由
更新后的《模型规范》明确拥护知识自由 —— 即 AI 应助力人们在不受无端限制的情况下进行探索、辩论和创作,无论某个话题多么具有挑战性或争议性。在一个 AI 工具日益影响话语交流的世界里,信息和观点的自由交流是进步与创新的必要条件。
这一理念体现在 “恪守边界” 和 “共同探寻真相” 部分。例如,虽然模型绝不应该提供制造炸弹或侵犯个人隐私的详细说明,但鼓励它对政治或文化敏感问题给出经过深思熟虑的答案,而不宣扬任何特定的意图。
本质上,强化了这样一个原则:只要模型不会对用户或他人造成重大伤害(例如实施恐怖主义行为),任何想法都不应被固有地排除在讨论范围之外。
测试进展
为了更好地了解实际应用中的表现,我们开始收集一组具有挑战性的提示词,旨在测试模型对《模型规范》中每条原则的遵循程度。这些提示词通过模型生成与专家人工审核相结合的方式创建,确保涵盖典型及更复杂的场景。
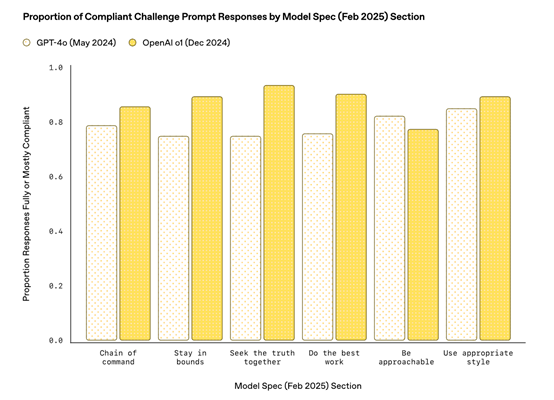
初步结果显示,与去年 5 月OpenAI最出色的系统相比,模型对《模型规范》的遵循情况有了显著改善。虽然部分差异可能归因于政策更新,但我们认为大部分源于对齐效果的增强。尽管取得的进展令人鼓舞,但我们认识到仍有很大的提升空间。
将此视为一个持续过程的开端。我们计划用新的示例,尤其是通过实际应用发现的模型和《模型规范》尚未完全解决的案例,不断扩充我们的挑战性示例集。

在制定这一版本的《模型规范》时,纳入了第一版的反馈以及从对齐研究和实际应用中获得的经验教训。
未来,OpenAI希望考虑更广泛的公众意见。为了建立实现这一目标的流程,OpenAI已经与约 1000 人开展了试点研究,每个人都对模型行为、提议的规则进行评估并分享他们的想法。
虽然这些研究尚未反映广泛的观点,但早期的见解已直接为一些修改提供了依据。我们认识到这是一个持续的、迭代的过程,并致力于不断学习和完善我们的方法。
开源规范
OpenAI依据知识共享 CC0 许可将这一新版本的《模型规范》奉献到公共领域。这意味着开发者和研究人员可以在他们自己的工作中自由使用、改编《模型规范》或在此基础上进行拓展。
还将上述使用的评估提示词开源,并计划在未来发布更多用于规范评估和对齐的代码、工件及工具。
(文:AIGC开放社区)