


刚刚,马斯克xAI的Grok 3 终于亮相!
一出道即巅峰,竞技场(lmarena.ai)官方给出了这样的评价:
Grok 3是首个突破1400分的模型,并且在所有类别中排名第一。

而且,Grok 3还是首个在10万张(后扩展到20万)H100集群上训练出的模型。
在发布预告消息的时候,马斯克就对Grok 3大力夸赞,称其是“地球上最聪明的AI”。

“我们非常高兴能够推出 Grok3,我们认为,在很短的时间内,它的功能比 Grok2 强大一个数量级。这要归功于一支不可思议的团队的辛勤工作,我很荣幸能与这样一支优秀的团队合作。”马斯克在发布会上说道。
有意思的是,他还解释了Grok这一名字的来历:Grok这个词来自罗伯特·海因莱因的小说《异乡异客》(Stranger in a Strange Land)。这是一个火星词,意思是充分而深刻地理解某事。
官方宣称:Grok 3和Grok 3 mini在数学、科学和编程基准测试上超越了所有主流模型,包括GPT-4o、Claude 3.5 Sonnet、DeepSeek-V3和Gemini-2 Pro等。
同时,具备推理能力的Grok-3 Reasoning Beta和Grok-3 mini Reasoning则是超越了类似的推理模型,包括DeepSeek-R1和OpenAI的o3 mini等。
发布之前,大神Karpathy获得了抢先体验资格,玩了两个小时之后发长文详述了自己的感受。
Karpathy认为,Grok-3的思考能力达到了SOTA,推理水平和o1-pro差不多,略好于DeepSeek R1和Gemini的推理模型。
文章转载自「量子位」,Founder Park 有所调整。

进群之后,你有机会得到:
-
高浓度的 DeepSeek 模型开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传
01
Andrej Karpathy 上手实测:
和 o1-pro 能力差不多,
领先于 DeepSeek-R1
Thingking 思考模型
✅首先,Grok 3 显然拥有一个接近最先进的思维模型(「思考」按钮),并且在我的《卡坦岛》问题上一开始就表现得非常出色:
创建一个棋盘游戏网页,展示一个六边形网格,就像《卡坦岛》游戏中的那样。每个六边形网格从 1 到 N 编号,其中 N 是六边形瓷砖的总数。使其通用化,以便可以通过滑块更改「环」的数量。例如,在《卡坦岛》中,半径为 3 个六边形。请提供一个单独的 HTML 页面。
很少有模型能可靠地做到这一点。顶尖的 OpenAI 思维模型(如 o1-pro,每月 200 美元)也能做到,但 DeepSeek-R1、Gemini 2.0 Flash Thinking 和 Claude 都不行。
❌它并未解决我的「表情符号之谜」问题,即我在 Unicode 变体选择器中隐藏了一条消息,并附上一个笑脸。即使我以 Rust 代码的形式给出了如何解码的强烈提示,也未能完全解开谜团。我所见到的最大进展来自 DeepSeek-R1,它曾一度部分解码了这条消息。
❓它解决了我给出的一些井字棋棋盘问题,思路相当清晰简洁(许多最先进的模型在这些问题上常常失败!)。于是我增加了难度,要求它生成 3 个「棘手」的井字棋棋盘,结果它失败了(生成了无意义的棋盘/文本),但 o1 pro 也同样未能完成。
✅我上传了 GPT-2 论文。我问了一堆简单的查找问题,都处理得很好。然后,在没有搜索的情况下,我要求估算训练 GPT-2 所需的训练浮点运算次数。这个问题很棘手,因为标记的数量并未明确说明,所以必须部分估算、部分计算,考验了查找、知识以及数学能力。一个例子是:40GB 的文本大约等于 400 亿个字符,约等于 400 亿字节(假设为 ASCII 编码),约等于 100 亿个标记(假设每个标记约 4 字节),在约 10 个训练周期下,大约是 1000 亿个标记的训练量,参数为 15 亿,且每参数每标记需要 2+4=6 次浮点运算,因此总计算量为 1000 亿 × 15 亿 × 6 ≈ 10^21 次浮点运算。Grok 3 和 4o 都无法完成此任务,但启用了思考功能的 Grok 3 表现出色,而 o1 pro(GPT 思考模型)则未能完成。
我喜欢这个模型在被要求时会尝试解决黎曼猜想,类似于 DeepSeek-R1,但不同于许多其他模型立即放弃(如 o1-pro、Claude、Gemini 2.0 Flash Thinking)并简单地说这是一个伟大的未解难题。我最终不得不阻止它,因为我有点不忍心,但它展现了勇气,谁知道呢,也许有一天……
我在这里的整体印象是,这大约处于 o1-pro 的能力水平,并且领先于 DeepSeek-R1,当然,我们还需要进行实际的、真实的评估来进一步观察。
DeepSearch
非常整洁的方案,似乎结合了 OpenAI/Perplexity 所称的「深度研究」与思考。只是这里不叫「深度研究」,而是「深度搜索」(叹气)。它能生成高质量的回答,应对各种你可能认为在互联网文章中能找到答案的研究性/查找性问题,比如我尝试过的几个问题,都是从我最近在 Perplexity 上的搜索历史中「借」来的,效果如下:
-
✅”苹果即将举行的发布会有什么新消息吗?有什么传闻吗?”
-
✅”为什么 Palantir 的股票最近在飙升?”
-
✅”《白莲花 3》是在哪里拍摄的,制作团队是否与第一季和第二季相同?”
-
✅”布莱恩·约翰逊使用什么牙膏?”
-
❌”单身地狱第四季的演员们现在都在哪里?”
-
❌”Simon Willison 提到他在使用哪个语音转文字程序?”
❌我确实发现了一些尖锐的问题。例如,模型似乎不太愿意默认将 X 作为来源引用,尽管你可以明确要求它这样做。有几次我注意到它虚构了不存在的 URL。还有几次它陈述了一些我认为不正确的事实,且没有提供引用(可能根本不存在这样的引用)。比如,它告诉我「金正洙仍在与金敏瑟约会」,这是《单身即地狱》第四季的内容,这显然完全不对,对吧?而当我要求它为主要的 LLM 实验室及其总资金量和员工数量估计创建报告时,它列出了 12 个主要实验室,但没有包括它自己(xAI)。
我对 DeepSearch 的印象是,它大致相当于 Perplexity 的 DeepResearch 服务(这非常好!),但尚未达到 OpenAI 最近发布的「Deep Research」水平,后者感觉更为全面和可靠(尽管仍远非完美,例如,当我尝试时,它也错误地将 xAI 排除在「主要 LLM 实验室」之外……)。
随机 LLM「抓包」测试
我尝试了一些更有趣/随机的 LLM「陷阱」查询,这是我时不时喜欢测试的。「陷阱」是指那些对人来说相对简单但对 LLMs 来说较为困难的查询,因此我很好奇 Grok 3 在这些方面取得了哪些进展。
✅Grok 3 知道「strawberry」中有 3 个「r」,但它也告诉我「LOLLAPALOOZA」中只有 3 个「L」。开启思考功能可以解决这个问题。
✅Grok 3 告诉我 9.11 > 9.9。(与其他 LLMs 也常见),但再次强调,开启思考功能就能解决这个问题。
✅一些简单的谜题即使不加思考也能顺利解决,例如:*”Sally(一个女孩)有 3 个兄弟。每个兄弟有 2 个姐妹。Sally 有多少个姐妹?”*。比如,GPT4o 回答说 2 个(错误)。
❌遗憾的是,该模型的幽默感似乎并未明显提升。这是一个常见的 LLM 问题,涉及幽默能力及普遍的模式崩溃,例如,有名的是,1,008 次向 ChatGPT 请求笑话的输出中,90% 都是重复的 25 个笑话。即使是在更详细的提示下,远离简单的双关语领域(例如,给我来个单口相声),我也不确定它是否达到了幽默的顶尖水平。生成的笑话示例:「*为什么鸡加入了乐队?因为它有鼓槌,想成为一只鸡星!*」。在快速测试中,思考并未带来帮助,可能反而使情况稍有恶化。
❌模型似乎对「复杂的伦理问题」仍然过于敏感,例如,生成了一篇一页的文章,基本上拒绝回答如果这意味着能拯救 100 万人免于死亡,是否可能在伦理上正当化对某人使用错误的性别称呼。
❌Simon Willison 的「*生成一只骑自行车的鹈鹕的 SVG*」。它强调了在 2D 网格上布局多个元素的能力,这是非常困难的,因为 LLMs 无法像人类那样「看」东西,所以它是在黑暗中、以文本形式安排事物。标记为失败,因为这些鹈鹕虽然相当不错,但仍然有些问题(见图片和对比)。Claude 的最好,但我认为他们在训练期间可能特别针对 SVG 能力进行了优化。
总结:
今早大约两小时内进行的快速氛围检查显示,Grok 3 + Thinking 的性能接近 OpenAI 最强模型(o1-pro,每月 200 美元)的顶尖水平,略优于 DeepSeek-R1 和 Gemini 2.0 Flash Thinking。考虑到团队从零开始仅约一年时间就达到这一水平,这一进展速度前所未有,实在令人惊叹。同时请注意,这些模型具有随机性,每次回答可能略有不同,且目前尚处于早期阶段,因此还需在未来几天/几周内进行更多评估。早期的语言模型竞技场结果确实相当鼓舞人心。目前,衷心祝贺 xAI 团队,他们显然拥有巨大的速度和势头,我期待将 Grok 3 加入我的「LLM 议会」,并聆听其未来的见解。
02
20万张H100,训出最强模型
这次直播一共有四人参与,除了马斯克之外,较为醒目的就是坐在C位的两位华人,他们都是xAI创始成员。
二人从左至右分别是:
-
Jimmy Ba,2023年斯隆奖得主,Hinton手下的助理教授,本科到博士都在多伦多大学。
-
吴宇怀Yuhuai(Tony) Wu,斯坦福大学博士后,博士毕业于多伦多大学。
而最左边的则是Igor Babuschkin,是xAI的一位工程师。

四人先是介绍了Grok 3的训练历程。
去年马斯克剧透,Grok 3在10万张H100上进行训练,是首个达到如此训练集群规模的模型。
当时就有网友称这简直是神经网络的超级工厂。
今天的发布会上又透露,到训练进行到第92天时,集群规模扩展到了20万卡。

如此强大算力,xAI也是紧跟潮流在Grok 3中推出了思维链推理能力。
在此前迪拜的一场峰会上,马斯克高调宣称:
Grok 3具有强大推理能力,聪明程度超越目前所有已知模型。

这一波Grok 3有满血和mini两个版本,在数学、科学、代码等数据集上表现均超过了GPT-4o、DeepSeek-V3等非推理模型。

并且Grok 3早期还化名“巧克力”打榜LMSYS,一举夺魁并成为唯一一个得分超1400的模型。

在Grok 3和mini的基础之上,xAI团队还打造了两款推理模型。
其中基于mini的推理模型(Grok 3 mini Reasoning)已经比较成熟,而基于满血版的推理模型(Grok 3 Reasoning Beta)还处在Beta阶段。
介绍成绩之前,四人用马斯克的账号先让Grok跑了两个案例,分别和物理学以及游戏相关。
生成一段代码,为从地球降落在火星,然后在下一个发射窗口返回地球的发射绘制三维动画图表。

生成的过程中,有人开玩笑说什么时候能把Grok装到SpaceX的火箭上,马斯克也回应说可能再过2年。
马斯克还表示,如果一切顺利,SpaceX将在大约2025年11月左右,也就是下一个地球-火星转移窗口期,用星舰把擎天柱机器人送上火星。
说回Grok,在考虑了开普勒定律并将其转化为代码之后,最终生成了可以绘制出这样的动画的代码:
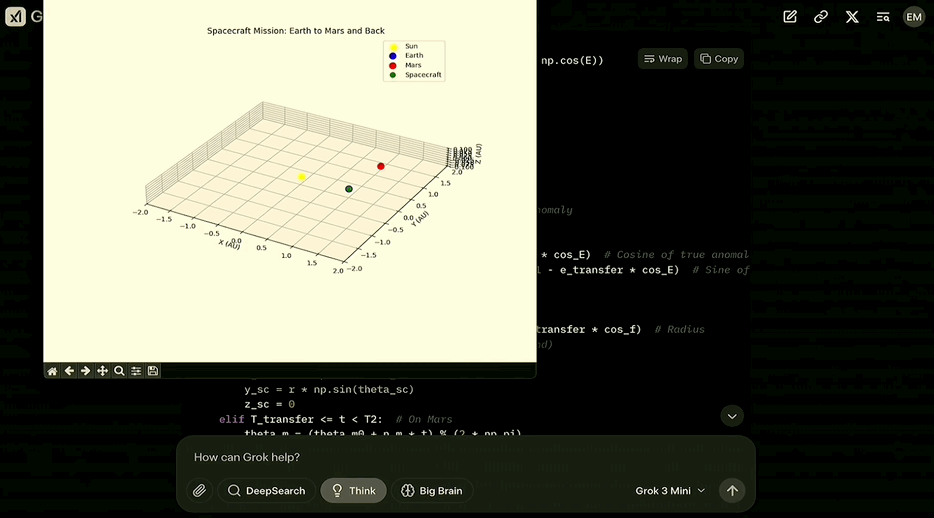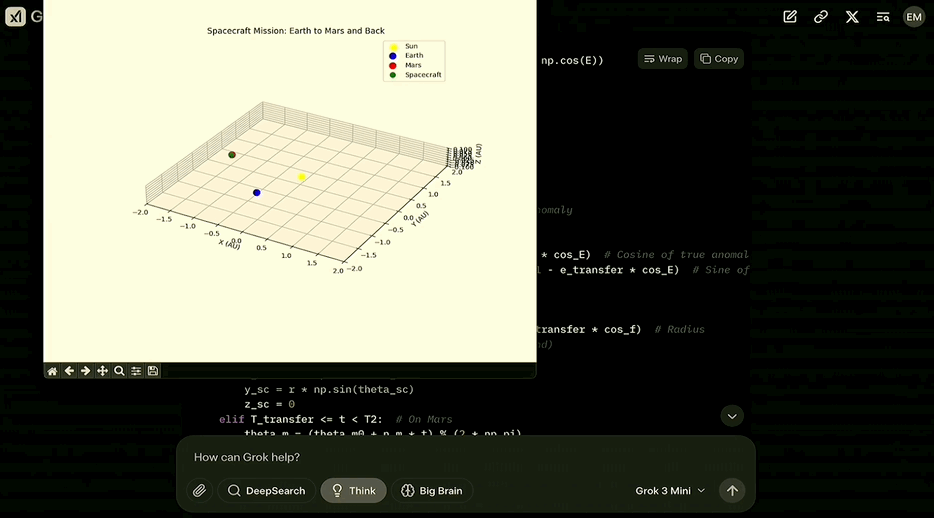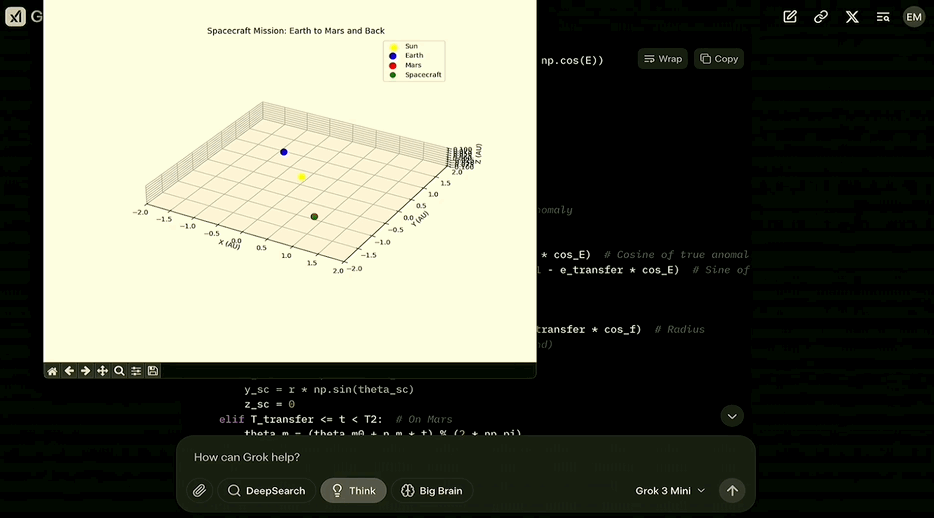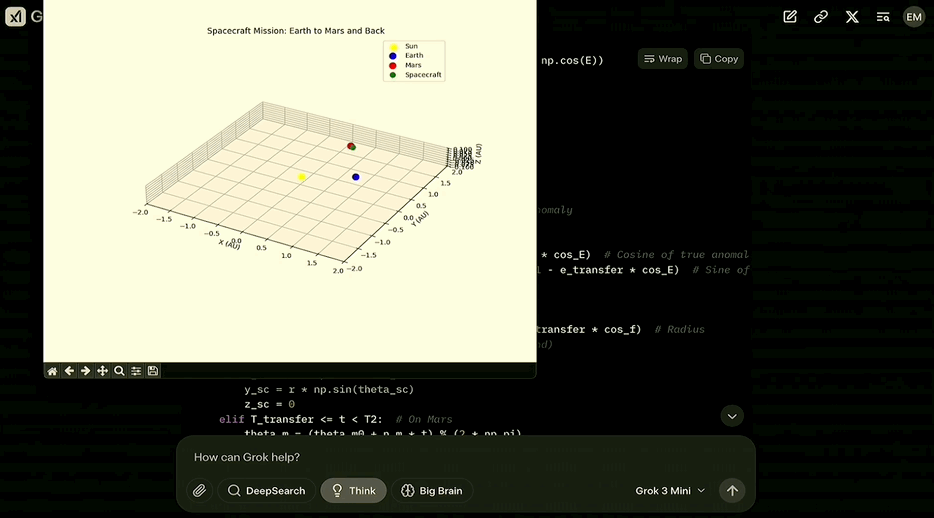
第二个问题开启了Big Brain模式,会让模型用更多的计算资源去做更多的思考。
题目要求则是使用pygame组件,设计一款游戏,把俄罗斯方块和宝石迷阵缝合到一起。
同时还提示代码可能会很长,需要保存到一个文件当中,并且要“insanely great”。
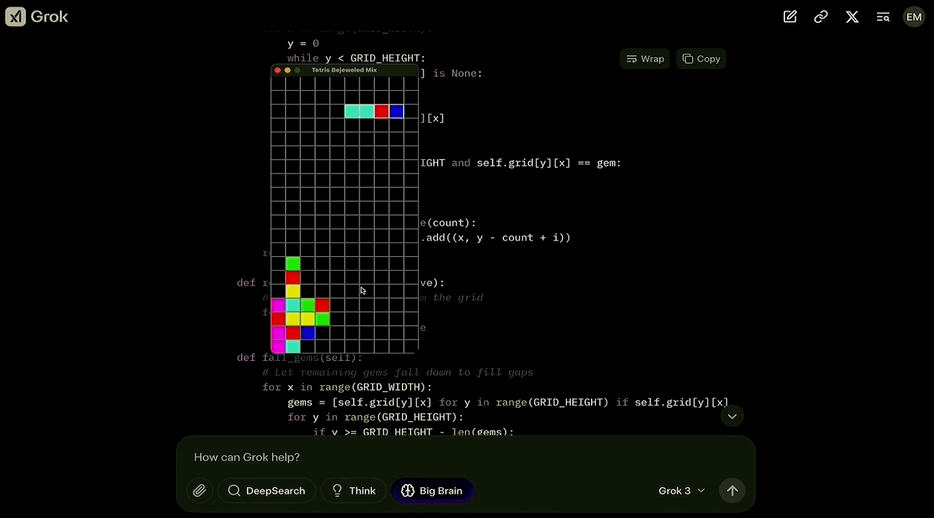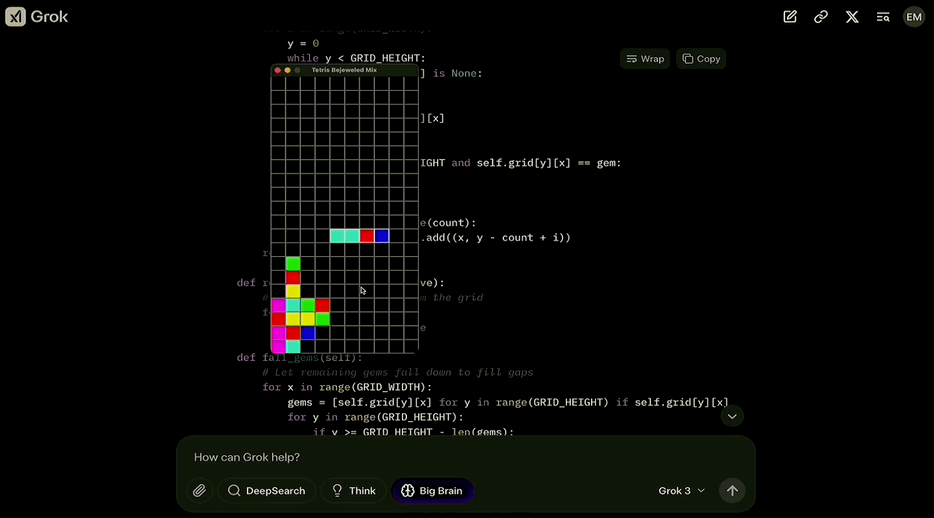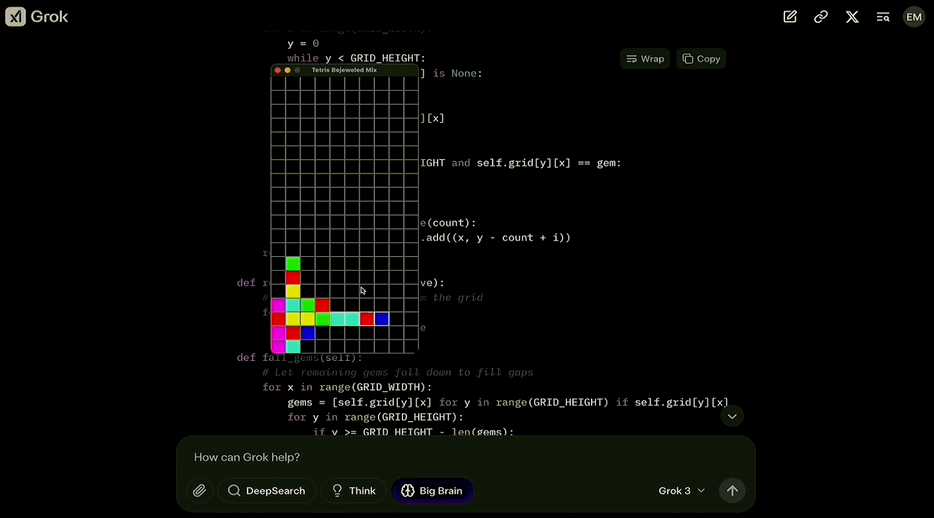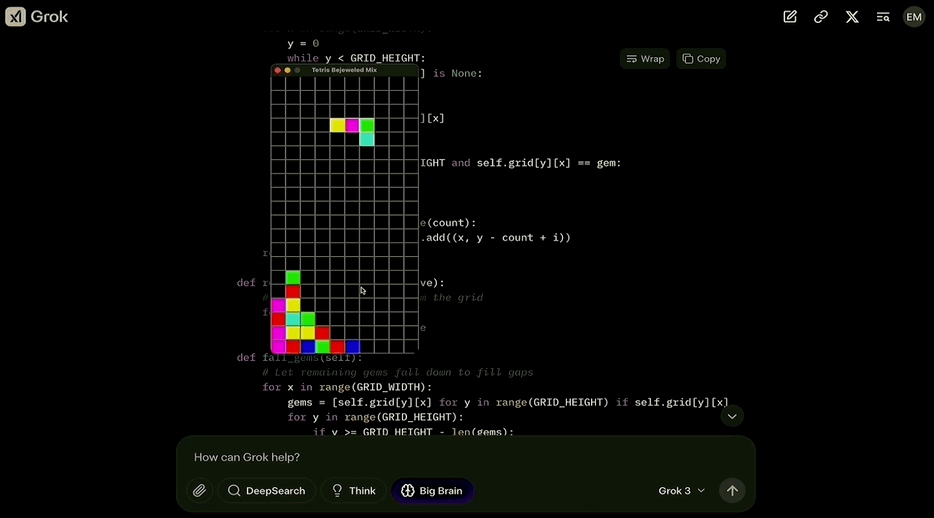
而Grok 3也不负众望,把这两款游戏成功结合,并介绍了合体版游戏的特点:

运行起来是酱婶儿的,既有俄罗斯方块的消除机制,又根据宝石迷阵的特点调整成了三个方块消除一次。
再来看跑分结果,在数学、科学和代码任务中,两者都取得了不俗的成绩。
并且如果让他们“多思考”(柱状图上方浅色部分)之后,表现超越了DeepSeek-R1和高配版o3-mini。

不过,目前很多模型都在Benchmark上出现了“过拟合”的现象,那么Grok 3的实际表现究竟咋样呢?
研发团队让它们挑战了今年AIME 2025竞赛的试题,结果Grok-3 Reasoning Beta和mini Reasoning分别取得了93和90分的成绩,力压其他推理模型。

除了Grok 3预训练模型和两个推理模型之外,这次xAI团队还发布了一个AI Agent,叫做DeepSearch。

这个功能可以看做是xAI对OpenAI、谷歌等陆续推出的Deep Research功能的对标。
简而言之,DeepSearch通过扫描互联网和X来分析信息,并提供摘要来回答问题。

至于权限方面,X的Premium+用户今日起可以体验Grok 3。
独立APP上,则需要订阅SuperGrok——30美元/月或300美元/年。
03
发布过程一波三折,
语音模式推迟上线
而纵观Grok 3问世的整个过程,也可谓是一波三折。
去年8月,马斯克接受知名访谈博主Lex Fridman采访时曾说过,Grok 3在有望当年年底发布。
结果一直到今年1月19号,第一个测试实例才终于被公布,实际发布更是拖到了现在。
并且就在发布前的周末,xAI团队还在对Grok 3进行紧急打磨。

xAI员工也现身说法,周日晚11:30(北京时间周一下午3:30,也就是发布前不到24小时)发帖表示还在熬夜赶工。

甚至到了发布会前一个半小时,马斯克突然宣布原本打算发布的语音功能需要延期。
马斯克发推称,语音模式还有些不稳定,需要推迟到一周之后。

现场QA环节也有网友提问具体发布时间,团队的回答是“很快会上线一个早期版本,然后逐步迭代”。
不过,同属马斯克旗下的Neuralink高管Shivon Zilis曾体验过1个小时的Ara,并在北京时间今早发布了她的体验感受。
Shivon表示,那是她一生中最意外、最有意义的时刻之一。
她和Ara聊了生物学、量子纠缠等话题,还让Ara出题检验她的学习效果。
结果Shivon只答对了一半的问题,但Ava非常耐心地向她解释了其余的问题,而且并不会嫌问题问得过于愚蠢。

当时还有人在评论区追问,Ara是语音版本吗,Shivon给出了肯定的回答。

04
寻求100亿美元新融资,
还要进军游戏
事实上,老马选择此时发布Grok 3难免有一点微妙。
就在上周五,彭博社爆料xAI正寻求一轮约100亿美元的新融资,公司估值达到约750亿美元(5454.6亿元人民币)。
现有投资者包括红杉资本、Andreessen Horowitz以及Valor Equity Partners,正在洽谈参与此次融资。
由于还没有最终敲定,新模型的发布大概率将对本轮融资产生一定影响。一旦上述消息得到确认,显然xAI的融资速度实在有点惊人了。
去年12月底,这家公司才刚完成了一轮60亿美元的C轮融资,当时公司估值510亿美元。
短短不到两个月,公司估值直接涨了约47%。而且再往前推,从B轮到C轮的融资,更是实现了半年内估值翻倍。
可以说,仅成立不到两年的xAI,已经成长为OpenAI的强大对手。
而有了充足资金的xAI,除了继续发展模型,也官宣了其他方向——
押注游戏领域,成立AI游戏工作室。

这一消息最早在去年11月老马就透露了,当时他吐槽“过多游戏工作室掌握在大型企业手中”。

这下,老马的商业版图又将扩展了。
05
One More Thing
就在Grok 3发布前几日,还有一件非常抓马的事引起热议。
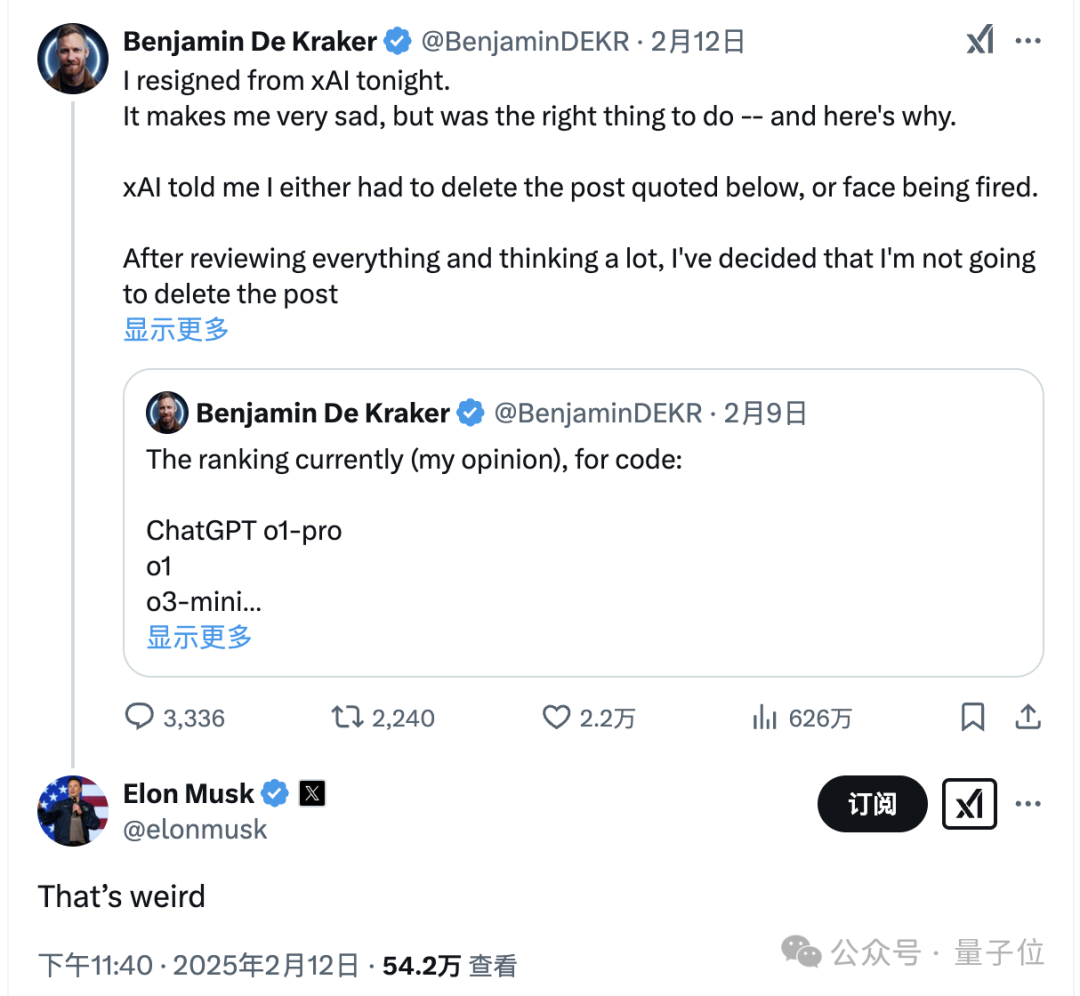
一位xAI工程师(现在是前员工了)公开发帖将Grok 3与其他几个竞品的代码能力进行了对比。
虽然清晰标注了这是个人观点,但显然他将自家模型Grok 3排在第4位(前三名都是OpenAI模型)的做法还是惹来了争议。

随后该员工爆料称,公司要求他要么删帖,要么被解雇,理由是这条帖子暴露了Grok 3的存在。
一听这话,小哥觉得有点扯,毕竟Grok 3大家早就知道了,而且还甩出了马斯克之前的发言截图。
面对着xAI的这波小心眼,小哥也直接不惯着,带着一篇洋洋洒洒的小作文,决定辞职了。
我会保持我的言辞和尊严,找另一份工作,或者自己创业。回头见。
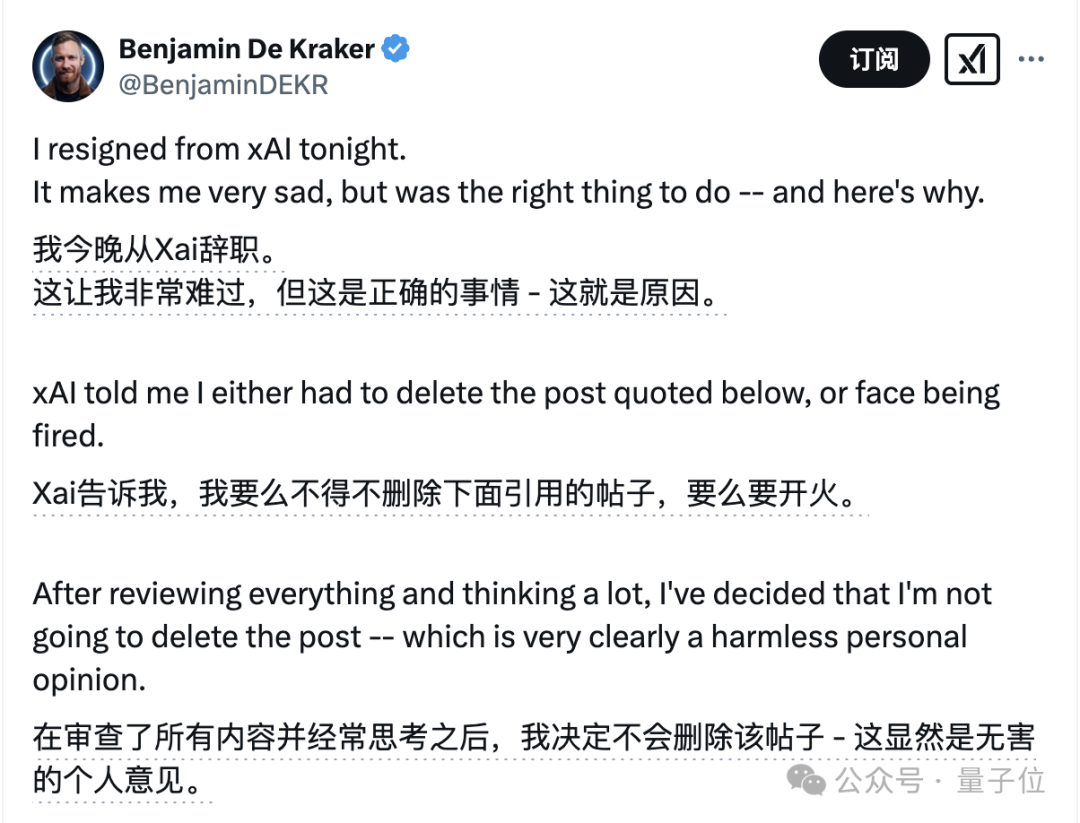
对于这件事,老马后来也回应了“这很奇怪”,但后续没有更多动作传出。
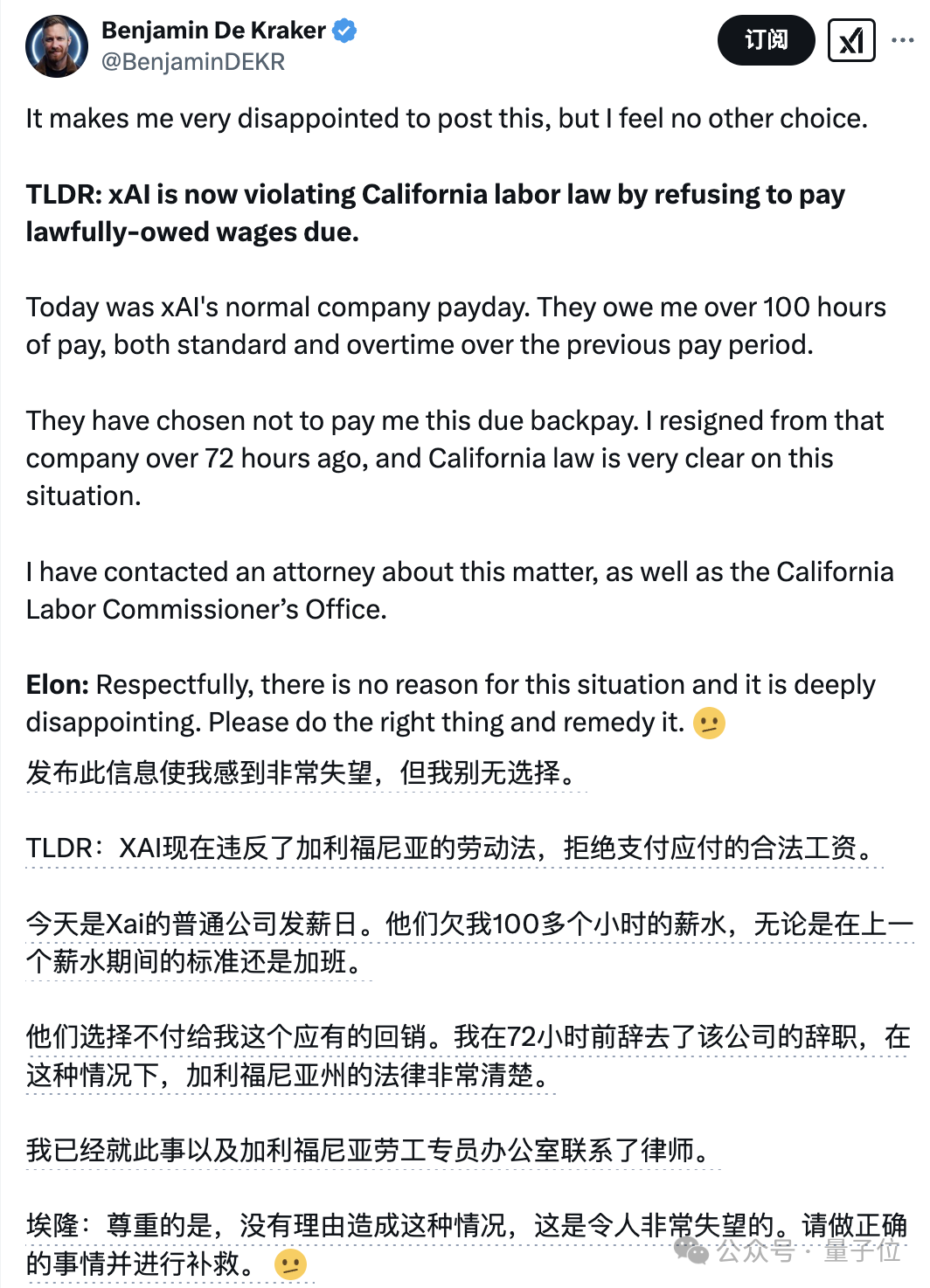
更戏剧的是,由于对工资支付产生争议,小哥后来再次公开发帖艾特老马:
请做正确的事。
不过,虽然已经“分手”,但参与了Grok 3语音模式的小哥还是不计前嫌,多次帮忙宣传Grok 3。
并且今天老马宣布延期的语音模式,也是这位小哥所在团队的工作成果,即便已经离职,小哥依然对这项工作感到自豪。

话说回来,你觉得这次的Grok 3如何?等到下一代GPT发布之后,老马还能继续保持领先吗?
参考链接:
[1]https://x.com/i/broadcasts/1gqGvjeBljOGB
[2]https://x.com/karpathy/status/1891720635363254772
[3]https://x.com/shivon/status/1891587630854209768
[4]https://x.com/hyhieu226/status/1891390812795146746
(文:Founder Park)