
【编者按】当大家讨论为什么 DeepSeek 能够形成全球刷屏之势,让所有厂商、平台都集成之时,「开源」成为了最大的关键词之一,图灵奖得主 Yann LeCun 称其是「开源的胜利」。模型开源一直备受关注,从代码、数据到模型的完全开源是人们渴求的方向。那么 DeepSeek 的开源究竟开放了什么?开放到了何种程度?本文作者——资深程序员+资深律师,一起为大家拆解 DeepSeek 的开源之道。
【写在前面】DeepSeek 是目前可以和闭源大模型媲美的开源大模型,DeepSeek 许可证是负责任的人工智能许可证。按照 Linux 基金会的模型开放架构,DeepSeek 的开放层级尚未完全达到第三级。使用或者分发 DeepSeek 大模型应当遵从 DeepSeek 许可证,包括对于使用场景的限制等。美中不足的是 DeepSeek 可能自己也没有完全遵守其应当遵守的开源许可证。

DeepSeek 到底有多牛?
DeepSeek 的演进包括了 V2、V2.5、V3、R1-Zero、R1 等版本。其中,用于评估 V3 模型的基准测试包括 MMLU、MMLU-Redux、MMLU-Pro、C-Eval、CMMLU、IFEval、FRAMES、GPQA Diamond、SimpleQA、C-SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench、Codeforces、中国全国中学生数学奥林匹克竞赛(CMO),以及美国数学邀请赛(AIME)。V3 的测试比对结果显示 V3 是性能最佳的开源模型,并且与前沿闭源模型相比也表现出了竞争力。测试对比结果如下[1]:
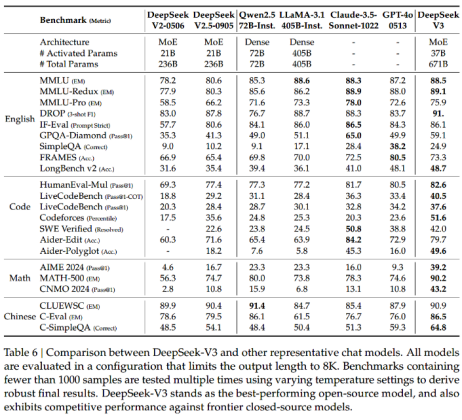
图 1 DeepSeek-V3 模型测试对比结果
R1 里程碑式的贡献在于其主要采用强化学习(Reinforcement Learning,RL)而非监督微调(Supervised Fine-Tuning,SFT)提升了大模型的能力。R1 的测试结果在某些测试项的表现优于 OpenAI 的 o1。R1 的测试比对结果如下[2]:

图 2 DeepSeek-R1 模型测试对比结果
就在看似闭源 OpenAI 遥遥领先之时,DeepSeek 开源大模型的出圈又带来了巨大的不确定性。对于开源我们仍然满怀期待,就像 PC 时代的 Linux,移动终端时代的 Android,人类期待 AI 时代的「待定」(可参见《万字长文!深入大模型版权归属问题》一文)。

DeepSeek 是什么开源许可证?
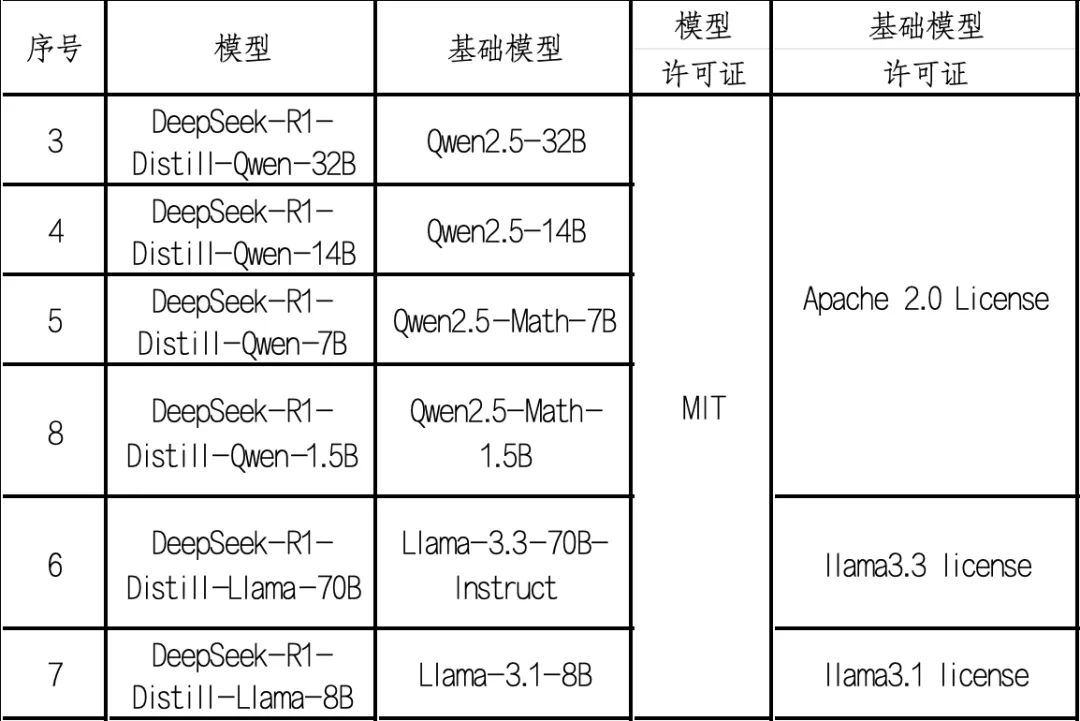
DeepSeek 在 Hugging Face 上一共开放了 68 个模型以及一个数据集[3]。DeepSeek-R1、DeepSeek-R1-Zero 模型的代码和模型权重都采用的是 MIT 许可证。其余的模型采用的是 DeepSeek 许可证,但代码采用的是 MIT 许可证。各模型采用的开放许可证如下:
表 1 DeepSeek 模型许可证

注:序号按照 Hugging Face 上的时间顺序,序号越小时间越在前。
除了以上大模型之外,DeepSeek 还从 Qwen 和 Llama 蒸馏了 6 个模型,蒸馏模型的许可证为 MIT 许可证,Qwen 基础模型许可证为 Apache 2.0,而 Llama 的许可证为 llama 许可证。
表 2 蒸馏模型许可证

DeepSeek 的开源/开放到了什么层级?
根据 LF AI&Data 基金会引入的模型开放框架(Model Openness Framework,MOF),大模型的开放分为以下三个层次[4]:
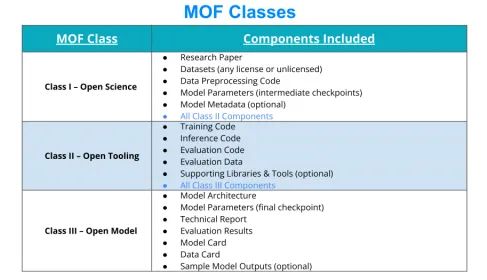
图 3 模型开放框架
以 DeepSeek-R1 和 DeepSeek-V3 为例,笔者理解的 DeepSeek 开放层级如下:
表 3 DeepSeek 模型开放层级
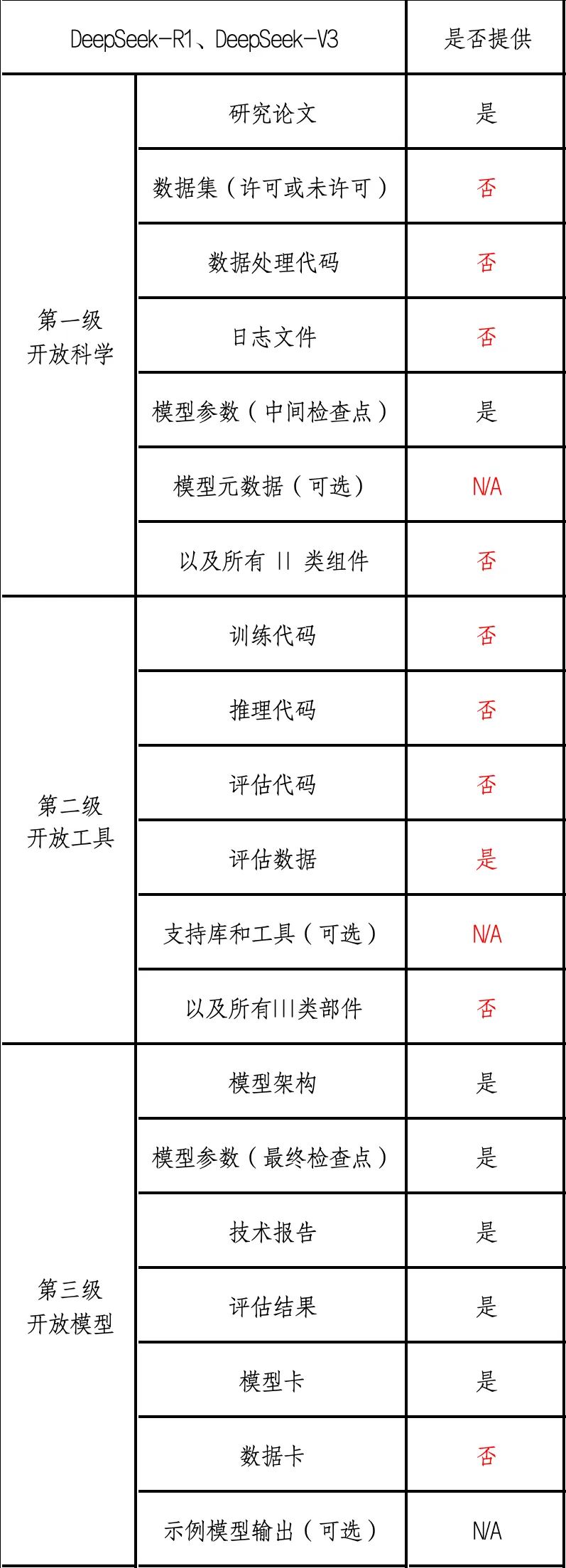
由上表可知,DeepSeek 开放了模型架构、模型卡、模型参数、技术报告、评估结果等,因此,DeepSeek 的开放层次至多属于第三级。DeepSeek 并未开放训练代码、推理代码、评估代码、数据集等更为重要的组件。

使用及分发 DeepSeek 大模型有哪些限制及条件?
除了 R1 系列模型之外的其他 DeepSeek 模型都采用 DeepSeek 许可证。
正如前文所述,DeepSeek 几乎没有开放任何数据。“数据”是指从模型使用的用于训练、预训练或以其他方式评估模型的数据集中提取的信息和/或内容的集合。因此,DeepSeek 许可证中也明确写明数据未根据该许可证获得许可。
DeepSeek 模型许可证的原型是负责任的人工智能许可证(Responsible AI License,RAIL)的模型许可证[5]。当然 RAIL 的原型应该是 Apache 2.0 许可证[6]。
(一)使用限制
RAIL 旨在防止不负责任和有害的应用程序。为此,在 RAIL 许可证中加入了使用限制条款,具体而言,采用 DeepSeek 许可证的模型不得用于以下情形:
-
以任何方式违反任何适用的国家或国际法律或法规或侵犯任何第三方的合法权益;
-
以任何方式用于军事用途;
-
以任何方式剥削、伤害或试图剥削或伤害未成年人;
-
生成或传播可验证的虚假信息和/或内容,以伤害他人为目的;
-
根据适用的监管要求生成或传播不适当内容;
-
未经授权或者不合理使用而生成或传播个人身份信息;
-
诽谤、贬损或以其他方式骚扰他人;
-
对于完全自动化的决策,对个人的合法权利产生不利影响或以其他方式产生或修改具有约束力、可执行的义务;
-
任何基于线上或线下社交行为或已知或预测的个人或性格特征,旨在或具有歧视或伤害个人或团体的效果的使用;
-
利用特定群体基于其年龄、社会、身体或精神特征的任何弱点,以实质性扭曲该群体成员的行为,从而造成或可能造成该人或他人身体或心理伤害;
-
对于任何旨在或具有基于受法律保护的特征或类别歧视个人或群体的效果的使用。
R1 模型采用的 MIT 许可证没有列出任何限制。虽然看起来 DeepSeek 许可证比 MIT 许可证增加了很多限制,但是具有实质意义的限制大概只有“以任何方式用于军事用途”这一条,其他限制,无论是否列出,根据现代国家的法律,基本上都是不符合法律规定的。
除了以上的限制情形,使用者可以使用 DeepSeek 模型创建任何内容、微调、更新、运行、训练、评估和/或重新参数化模型。
(二)知识产权许可
DeepSeek 针对模型、模型衍生品和补充材料授予的许可包括版权许可和专利许可。许可条款如下:
2.授予版权许可。根据本许可的条款和条件,DeepSeek 特此授予您永久、全球、非排他、免费、免版税、不可撤销的版权许可,以复制、准备、公开展示、公开表演、再授权和分发补充材料、模型和模型的衍生品。
3.授予专利许可。根据本许可的条款和条件以及适用情况, DeepSeek 在此授予您永久、全球、非排他、免费、免版税、不可撤销(本段所述情况除外)的专利许可,以制作、委托制作、使用、提供销售、销售、进口和以其他方式传递模型和补充材料,但此类许可仅适用于 DeepSeek 可授权且因其贡献而必然被侵权的专利权利要求。如果您对任何实体提起专利诉讼(包括诉讼中的交叉诉讼或反诉),声称模型和/或补充材料构成直接或共同专利侵权,则根据本许可授予您的模型和/或作品的任何专利许可应在该诉讼主张或提交之日起终止。
授予版权和专利权的条款和最常见的 Apache 2.0 许可证的许可条款几无二致。
(三)分发和再分发的条件
如果想把 DeepSeek 模型为第三方远程访问目的(例如 SaaS)而托管、复制和分发模型或其衍生品的副本(无论是否经过修改),分发者或者再分发者(统称“传播方”)必须满足以下条件:
a. 传播方必须将以上使用限制作为可执行条款纳入任何类型的法律协议(例如许可证)中,以管理模型或模型衍生品的使用和/或分发,并且应当通知第三方接收者,模型或模型衍生品均受使用限制的约束。该条件不适用于补充材料的使用。“补充材料”是指用于定义、运行、加载、基准测试或评估模型的随附源代码和脚本,以及用于准备用于训练或评估的数据(如有),包括任何随附文档、教程、示例等(如有)。
b. 传播方必须向模型或模型衍生品的任何第三方接收者提供 DeepSeek 许可证的副本;
c. 传播方如果又进行了修改,则必须在任何修改过的文件上附加显著的声明,说明更改了这些文件;
d. 传播方必须保留所有版权、专利、商标和归属声明,但不包括与模型、模型衍生品的任何部分无关的声明。
e. 传播方如果进行了修改,传播方可以在修改中添加自己的版权声明,并且为使用、复制或分发其修改部分,或整体上为修改后的模型衍生品,提供额外的或不同的许可条款和条件(前提是符合 a 项的使用限制),前提是传播方对 DeepSeek 模型的使用、复制和分发符合 DeepSeek 许可证中规定的条件。
如果传播方在分发或者再分发时没有满足这些条件,那么传播方就会构成违约(对 DeepSeek 许可证这一合同的违反)或者侵权(侵犯了 DeepSeek 许可证中授予的著作权以及专利权)。根据各国法律普遍面临着停止侵权、赔偿损失的法律责任。

使用及分发蒸馏模型有哪些进一步的限制及条件?
DeepSeek 分别基于 Qwen 以及 Llama 模型得出了蒸馏模型。如果需要使用或分发这些蒸馏模型,除了需要满足蒸馏模型本身的 MIT 许可证的要求外,还需要满足基础模型的许可证要求。Qwen 模型的许可证为 Apache 2.0 许可证,而 Llama 模型为 Llama 许可证。对于传统的 MIT 和 Apache 2.0 许可证的许可条件此处不再赘述。以 Llama 3.3 许可证为例,许可证第 1 条对于使用和分发的限制包括:
i.如果您分发或提供 Llama 材料(或其任何衍生作品)或包含其中任何内容的产品或服务(包括另一个 AI 模型),您应 (A) 随任何此类 Llama 材料提供本协议的副本;以及(B)在相关网站、用户界面、博客文章、关于页面或产品文档上突出显示“使用 Llama 构建” 。如果您使用 Llama 材料或 Llama 材料的任何输出或结果来创建、训练、微调或以其他方式改进已分发或提供的 AI 模型,您还应在任何此类 AI 模型名称的开头包含“Llama”。
ii. 如果您从被许可方处收到 Llama 材料或其任何衍生作品作为集成最终用户产品的一部分,则本许可证第 2 条不适用于您。
iii. 您必须在分发的所有 Llama 材料副本中保留以下归属声明,这些声明应在作为此类副本的一部分而分发的“声明”文本文件中发布:“Llama 3.3 已根据 Llama 3.3 社区许可获得许可,版权所有 © Meta Platforms, Inc.保留所有权利。”
iv. 您对 Llama 材料的使用必须遵守适用法律和法规(包括贸易合规法律和法规),并遵守 Llama 材料的可接受使用政策(可在 https://www.llama.com/llama3_3/use-policy 上找到),该政策特此通过引用纳入本协议。
该许可证的第 2 条为附加商业条款,即对于商业使用施加的限制:
如果在 Llama 3.3 版本发布之日,由被许可方或被许可方的关联方提供的产品或服务的月活跃用户数在前一个日历月超过 7 亿月活跃用户数,则您必须向 Meta 申请许可,Meta 可自行决定是否授予您许可,并且您无权行使本协议项下的任何权利,除非或直到 Meta 明确授予您此类权利。

DeepSeek 自己是否完全遵守了开源许可证?
DeepSeek-V3 和 DeepSeek-R1 的模型代码文件 modeling_deepseek.py[7]文件来自 EleutherAI 的 GPT-NeoX 库以及库中的 GPT-NeoX 和 OPT 实现,且原始形式上进行了修改,以适应与训练该模型的 Meta AI 团队使用的 GPT-NeoX 和 OPT 相比细微的架构差异。在 modeling_deepseek.py 文件中,也有多处类似于“# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->DeepseekV3”的注释。EleutherAI 的 GPT-NeoX 库采用 Apache 2.0 许可证[8]。
因此,如果 DeepSeek 集成了按照 Apache2.0 许可证分发的模型材料,也应当遵守 Apache 2.0 许可证的规定;如果 DeepSeek 集成了按照 Llama 许可证分发的模型材料,也应当遵守 Llama 许可证的规定。
DeepSeek 对 Qwen 大模型以及 Llama 大模型进行蒸馏,显然也应当遵守 Qwen 大模型所采用的 Apache 2.0 许可证以及 Llama 大模型采用的 Llama 许可证。
按照 Llama 许可证(以 Llama 3.1 为例)的规定,对于作为分发者的 DeepSeek,还应当(A)附随 Llama 材料提供 Llama 许可证副本;并且(B)在相关网站、用户界面、博客文章、关于页面、或产品文档上突出显示“使用 Llama 构建”。从 Llama 模型蒸馏毫无疑问使用了 Llama 模型材料,因此还应在任何此类蒸馏模型名称的开头包含“Llama”。此外,还应当在声明文本文件中保留以下署名声明:“Llama 3.1 是根据 Llama 3.1 社区许可证授权,版权所有 © Meta Platforms, Inc.,保留所有权利。”
根据以上的分析,DeepSeek 并未完全遵循开源许可证,主要表现在没有在相应的大模型分发材料中附随分发许可证副本,没有突出显示“使用 Llama 构建”,也没有保留署名声明。

总结
尽管 DeepSeek 自己本身可能也并未完全遵守开源许可证。但是,白璧微瑕,DeepSeek 惊人的表现又让世界对于开源大模型有了更高的期待。这也并不代表着其他人在使用和分发 DeepSeek 大模型时就可以有样学样。恰恰相反,使用者或者分发者更应该本着不让雷锋吃亏的精神,认真遵循开源许可证中规定的使用限制条件和分发条件,构建负责任的人工智能世界。



相关资料链接:
[1] https://arxiv.org/html/2412.19437v1
[2] https://arxiv.org/html/2501.12948v1
[3] https://huggingface.co/deepseek-ai
[4] https://lfaidata.foundation/blog/2024/04/17/introducing-the-model-openness-framework-promoting-completeness-and-openness-for-reproducibility-transparency-and-usability-in-ai/
[5] https://static1.squarespace.com/static/5c2a6d5c45776e85d1482a7e/t/6308bb4bba3a2a045b72a4b0/1661516619868/BigScience+Open+RAIL-M+License.pdf
[6] https://www.apache.org/licenses/LICENSE-2.0.html
[7] https://huggingface.co/deepseek-ai/DeepSeek-R1/blob/main/modeling_deepseek.py
[8] https://github.com/EleutherAI/gpt-neox

大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
(文:AI科技大本营)