
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
好消息如约而至,DeepSeek开源周第二弹来了!
DeepEP, 第一个用于MoE模型训练和推理的开源EP通信库(expert parallelism,专家并行)。
它提供高吞吐量和低延迟的all-to-all GPU内核,也称为MoE dispatch和combine。
该库还支持低精度运算,包括FP8。
同时按惯例,开源协议用的是最为宽松的MIT。

今天的DeepSeek选择了先在GitHub上线,然后再在官推发上新通知。
不出所料,底下一片叫好:
DeepSeek开源列车永不停止。

DeepEP性能如何?
DeepSeek官推对DeepEP进行了要素提炼:
-
高效和优化的all-to-all通信
-
NVLink和RDMA的节点内和节点间支持
-
用于训练和推理预填充的高吞吐量内核
-
用于推理解码的低延迟内核
-
原生FP8调度支持
-
灵活的GPU资源控制,用于计算通信重叠
我们先来看看性能方面的两个重点。
(注:DeepEP中的实现可能与DeepSeek-V3论文有一些细微的差异)
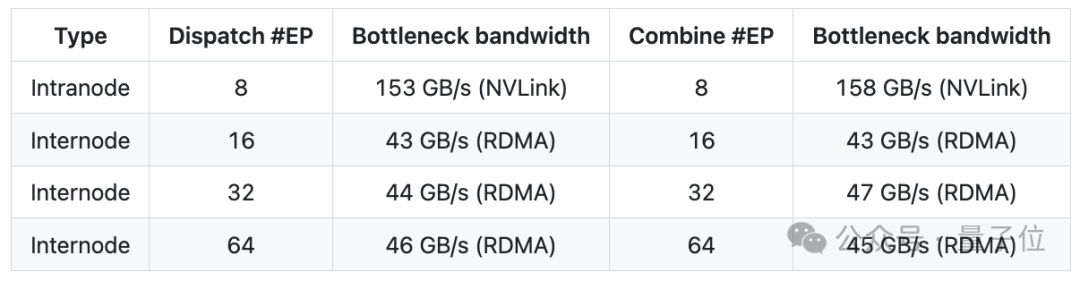
具有NVLink和RDMA转发的普通内核
为了与DeepSeek-V3论文中提出的组限制门控算法保持一致,DeepEP提供了一组针对非对称域带宽转发进行了优化的内核,例如将数据从NVLink域转发到RDMA域。
这些内核提供高吞吐量,使其适用于训练和推理预填充任务。
此外,它们还支持SM(Streaming Multiprocessors)号码控制。
DeepEP团队在在H800(~160 GB/s NVLink最大带宽)上测试普通内核,每个内核都连接到CX7 InfiniBand 400 Gb/s RDMA网卡(~50 GB/s 最大带宽)。
且遵循DeepSeek-V3/R1预训练设置(每批4096个tokens,隐藏7168个,前4组,前8个专家,FP8调度和BF16组合)。
具有纯RDMA的低延迟内核
针对延迟敏感型推理解码场景,DeepEP包括一组具有纯RDMA的低延迟内核,以最大限度地减少延迟。
该库还引入了一种基于hook的通信计算重叠方法,不占用任何SM资源。
DeepEP团队在H800上测试低延迟内核,每个内核都连接到CX7 InfiniBand 400 Gb/s RDMA 网卡(~50 GB/s 最大带宽)。
且遵循典型的DeepSeek-V3/R1生产设置(每批128个tokens,7168个隐藏,前8个专家,FP8调度和BF16组合)。

暂不支持消费级显卡,建议使用最佳自动优化配置
在GitHub上,DeepSeek团队明确写出了关于DeepEP的使用方式,涵盖各种适配环境、配置要求等。
首先是DeepEP需要的软硬件环境版本:
-
Hopper GPUs(以后可能支持更多架构或设备)
-
Python 3.8及更高版本
-
CUDA 12.3及更高版本
-
PyTorch 2.1及更高版本
-
用于节点内通信的NVLink
-
用于节点内通信的RDMA网络
其次,使用DeepEP需要下载并安装团队修改后的NVSHMEM依赖项(有关说明,请参阅DeepSeek团队的NVSHMEM安装指南)。
然后,将 deep_ep 导入到Python项目中,就开始“尽情享受吧”!
至于网络配置方面,DeepEP已通过InfiniBand网络的全面测试。
但理论上,它也与基于融合以太网的RDMA(RoCE)兼容。
其中,InfiniBand通过虚拟通道(Virtual Lanes, VL)支持流量隔离。
为了防止不同类型流量之间的干扰,DeepEP图男队建议将工作负载隔离到不同的虚拟通道中,如下所示:
-
使用普通内核的工作负载
-
使用低延迟内核的工作负载
-
其它工作负载
对于DeepEP,开发者可以通过设置 NVSHMEM_IB_SL 环境变量来控制虚拟通道分配。
值得注意的是,自适应路由是InfiniBand交换机提供的一项高级路由功能,可以在多个路径之间均匀分配流量。
目前,低延迟内核支持Adaptive Routing,而普通内核不支持(可能很快就会添加支持)。
为普通的节点间内核启用自适应路由,可能会导致死锁或数据损坏问题。
对于低延迟内核,启用Adaptive routing可以完全消除路由冲突导致的网络拥塞,但也会带来额外的延迟。
DeepEP团队建议使用以下配置以获得最佳性能:
-
在网络负载较重的环境中启用自适应路由
-
在网络负载较轻的环境中使用静态路由
BTW,DeepEP已禁用拥塞控制(Congestion control),因为团队在生产环境中没有观察到明显的拥塞。
最后一点来自DeepEP团队的叮嘱——
为了获得极致性能,团队发现并使用了一条out-of-doc PTX指令ld.global.nc.L1::no_allocate.L2::256B 。
此指令将导致未定义的行为:使用非相干只读PTX修饰符 .nc 访问易失性GPU内存。
但是,正确性已经过测试,以保证 。L1::no_allocate 在 Hopper 架构上,性能会好得多。
如果您发现内核在某些其他平台上无法运行,您可以添加到DISABLE_AGGRESSIVE_PTX_INSTRS=1 setup.py并禁用此功能,或提交问题。
为了在集群上获得更好的性能,DeepSeek建议运行所有测试并使用最佳的自动优化配置。
因为默认配置在DeepSeek的内部集群上进行了优化~
One More Thing
DeepSeek为了本次开源周专门在GitHub上新开了一个库:
https://github.com/deepseek-ai/open-infra-index
根据这两天的发布,猜测本次开源周发布内容maybe均与AI Infra有关。
不过一个不那么好的消息,DeepSeek的开源周更新时间,好像不太稳定。
昨天是上午9:34,今天是10:24,明天……

于是乎,为了追踪DeepSeek碌碌向前的车轮,量子位诚邀大家一起第一时间上车(doge)。
扫码备注「DeepSeek-职业/姓名」加入群聊,一起追踪DeepSeek开源周!

DeepEP GitHub:
https://github.com/deepseek-ai/DeepEP
—
(文:量子位)