作者|子川
来源|AI先锋官
深夜王炸,就在刚刚Anthropic发布了最新模型Claude 3.7和全新智能体Claude Code,编程能力大幅度提升!
与以往模型不同,Claude 3.7 Sonnet是市面上“首个混合推理模型”。
简单来说,Claude 3.7 将“通用模型”和“推理模型”融合在一起,在模型输出时,可以自由选择Claude 3.7调用哪种模型进行回答。
同时Claude 3.7在扩展思考模式下将和Deepseek一样,将展示原始的思考过程,不做任何隐瞒。
其次,在API调用Claude 3.7 Sonnet时,可以设置 “思考预算 (budget for thinking)” :限制Claude的思考不超过N个token,其中N的值可高达其输出上限128K个token。
这样,用户能根据需要在速度、成本和答案质量之间自由调优,以达到更满意的效果。
在扩展思考模式下,Claude 3.7还会先“自我反思”,再给出答案,这使得它在数学、物理、指令跟随和编码等领域的表现大幅提升。
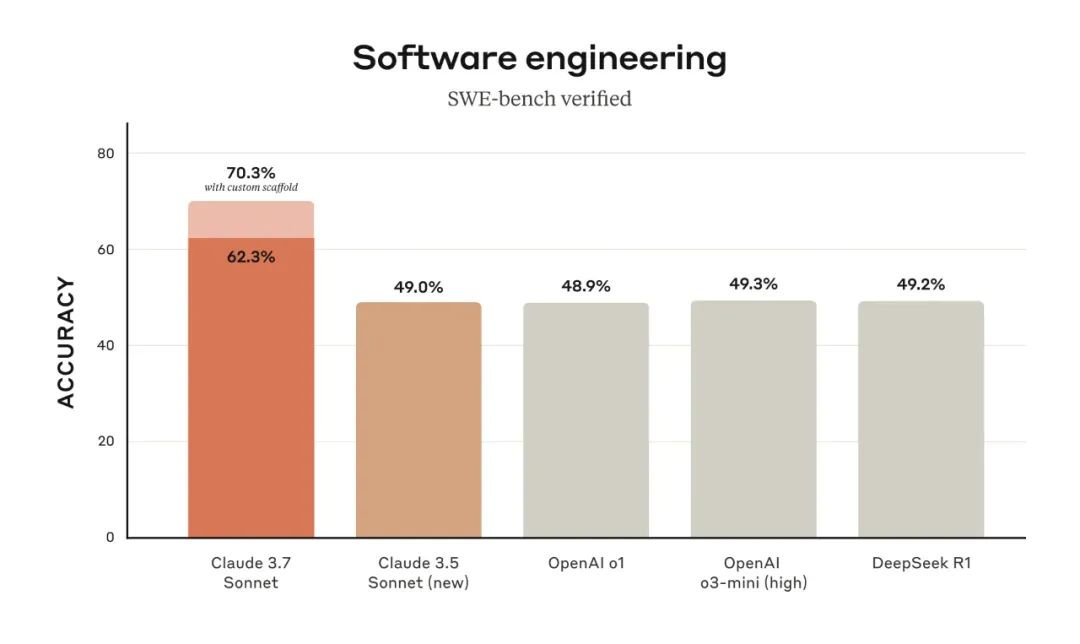
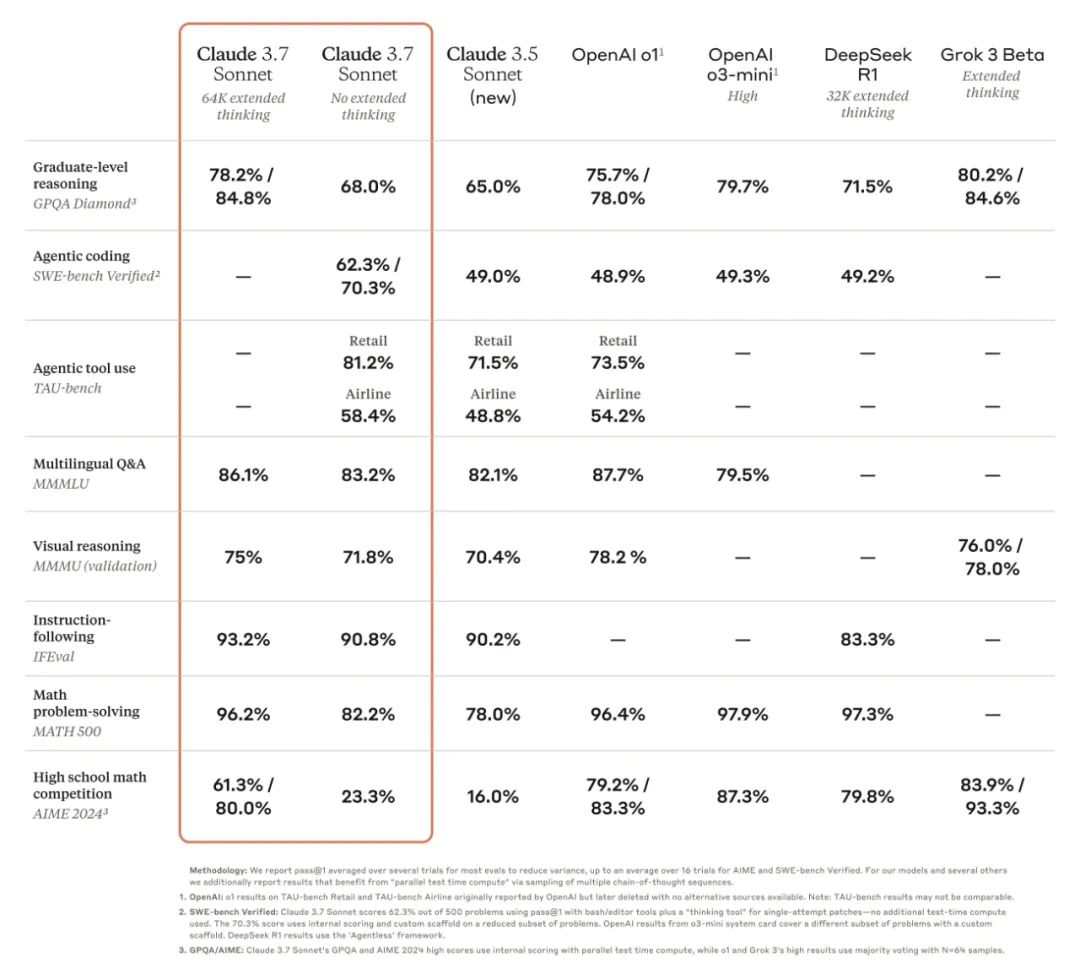
在SWE-bench Verified (软件工程基准测试)中, Claude 3.7 Sonnet 以 70.3% (使用定制 scaffold) 和 62.3% (标准 scaffold) 的分数超越了o1、o3-mini和Deepseek等一众多顶尖模型。
注:SWE-bench Verified 是 OpenAI 推出的一个经过人工验证的基准测试工具,旨在更可靠地评估 AI 模型解决现实世界软件问题的能力。
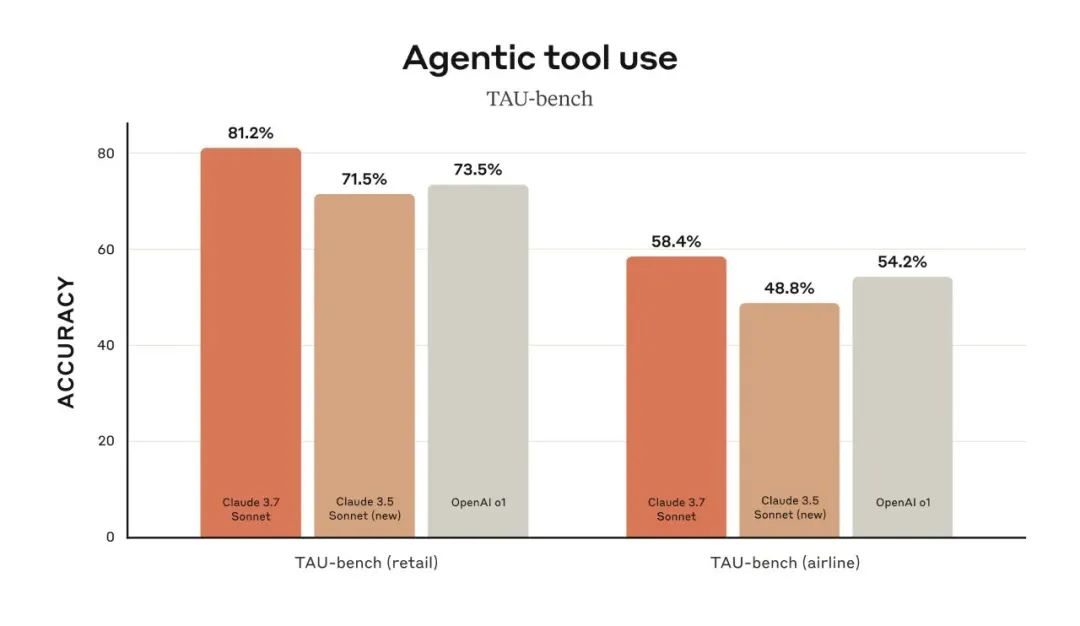
同时在TAU-bench (智能体工具使用基准测试)中,在 零售 (retail) 和 航空 (airline) 两个场景中,Claude 3.7分别取得了 81.2% 和 58.4% 的领先成绩。
在通用benchmark测试中,Claude 3.7 Sonnet 在指令遵循、推理、多模态能力和代理编码方面表现出色。
不过在 数学和科学方面,扩展思考模式并没有超越DeepSeek R1、o3-mini等模型。
除了发布Claude 3.7之外,Anthropic还推出了它们首个代理编码工具 Claude Code 。
Claude Code 是一款集成在终端中的代理编码工具,能够理解并操作代码库。
只需在命令行输入指令,就能让 AI 智能体完成代码搜索、文件编辑、测试编写和运行、代码提交和推送等一系列复杂的编程任务。
能一次性完成通常需要45分钟的工作量。
主要功能包括:
不过Claude Code 目前处于研究预览的 beta 阶段。
Anthropic表示正在收集开发人员关于 AI 协作偏好、哪些工作流程最受益于 AI 协助以及如何提升整体使用体验,这个早期版本将根据用户反馈不断改进。
(文:AI先锋官)