🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
圣诞节在二月,Claude扔了个王炸!
看来爆料者的信息还挺准的:
明天:Claude 4没等到,Claude 3.7 要来了?
不是嘛,哈哈哈。
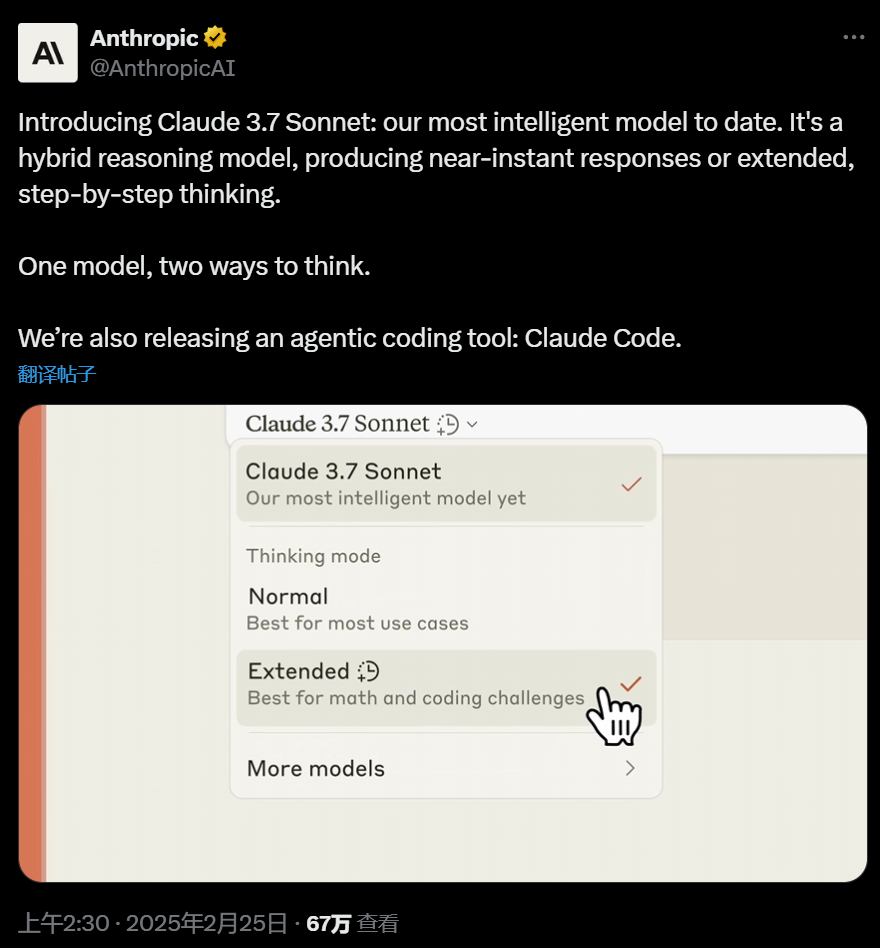
Anthropic 官方有个毛病,他们通常不会做任何的预发布,大半夜他给你扔出来了个王炸:
这次的新模型叫:Claude 3.7 Sonnet,它带来了一种新的思维方式。它不再把快速回答和深度思考割裂开来,而是像人类大脑一样,在同一个模型中实现两种能力。
Claude 3.7 Sonnet既能快速回答问题,也能在需要时进行深度思考,给用户带来更流畅的体验。
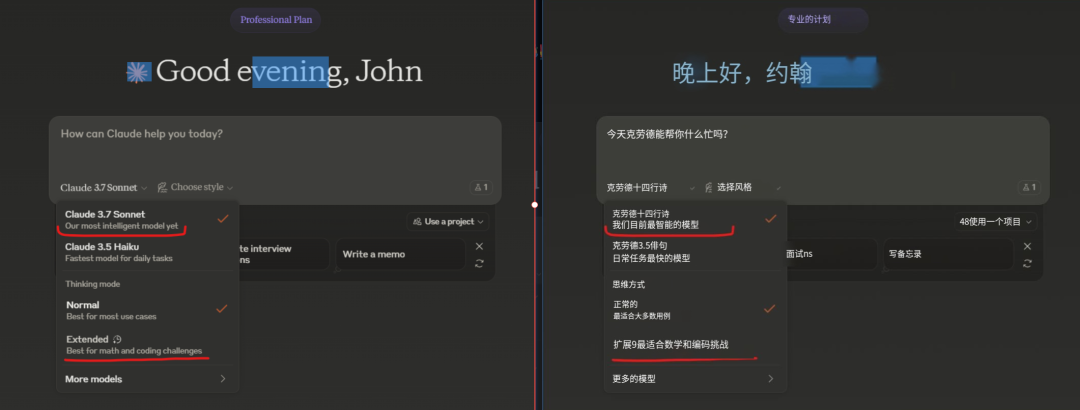
这种统一的设计让用户在使用时感受到更自然的互动,两种模式下的提示词方式基本相同,仿佛在与一个真正的助手对话。
你可以选择标准模式,快速得到答案;也可以切换到扩展思考模式,让Claude在回答前自我反思,这样在数学、物理、编码等任务上表现会更好。在扩展思考模式下,Claude会花更多时间分析问题,从而提供更准确和深入的回答,特别是在复杂的学科领域。
如果你通过API使用Claude,还可以控制思考的预算,决定Claude可以思考多少个token,最高128K。这意味着你可以根据任务重要性,精确设定模型思考的深度。在速度、成本和答案质量之间找到最佳平衡点。与其他模型不同,Claude更注重实际商业应用,而非竞赛题目。
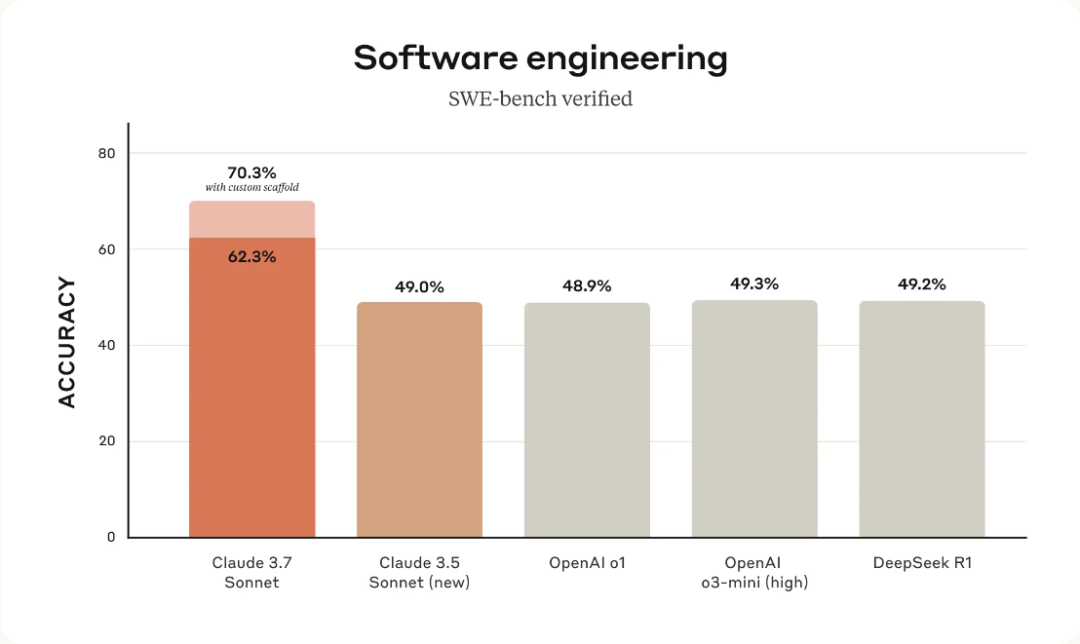
看看这张图,Claude 3.7 Sonnet在编程测试中拿到了70.3%的高分,把其他大模型全部甩在身后。
OpenAI的o1、o3-mini和DeepSeek R1都挤在49%左右打转,Claude直接领先20个百分点。
Sonnet 3.7显然将重点放在编码能力上,其他领域似乎并不是他们的主要关注点(你可以看到 Grok3 在MMMLU、AIME2024上是超过他的)。
虽然在其他知识测试上Claude只是小幅提升,但编程能力这一下子就上了一个台阶。
这表明,Anthropic希望将Sonnet定位为一款强大的编码AI。
Anthropic这是明摆着要把Claude打造成编程专家啊。毕竟它本来就已经很擅长写代码了,现在更是实力大增。
使用 API,128K最大输出(VIBE 编码万岁![]() )
Claude 3.7 Sonnet现在在所有计划中都可以使用,包括免费版、专业版、团队版和企业版。
也能在Anthropic API、Amazon Bedrock和Google Cloud的Vertex AI上使用。不过免费用户不提供扩展思维模式。
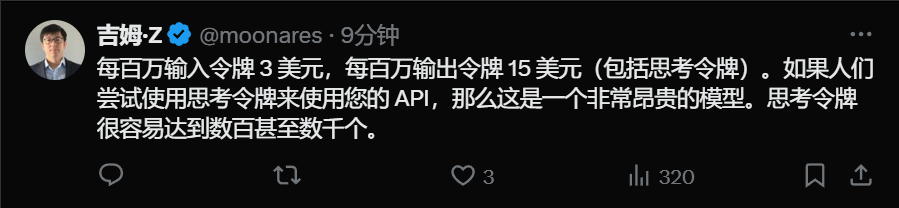
定价方面,与前代模型相同:每百万输入token 3美元,每百万输出token 15美元(包括思考token)。
所以,还有个3.5超大大大杯呢
)
Claude 3.7 Sonnet现在在所有计划中都可以使用,包括免费版、专业版、团队版和企业版。
也能在Anthropic API、Amazon Bedrock和Google Cloud的Vertex AI上使用。不过免费用户不提供扩展思维模式。
定价方面,与前代模型相同:每百万输入token 3美元,每百万输出token 15美元(包括思考token)。
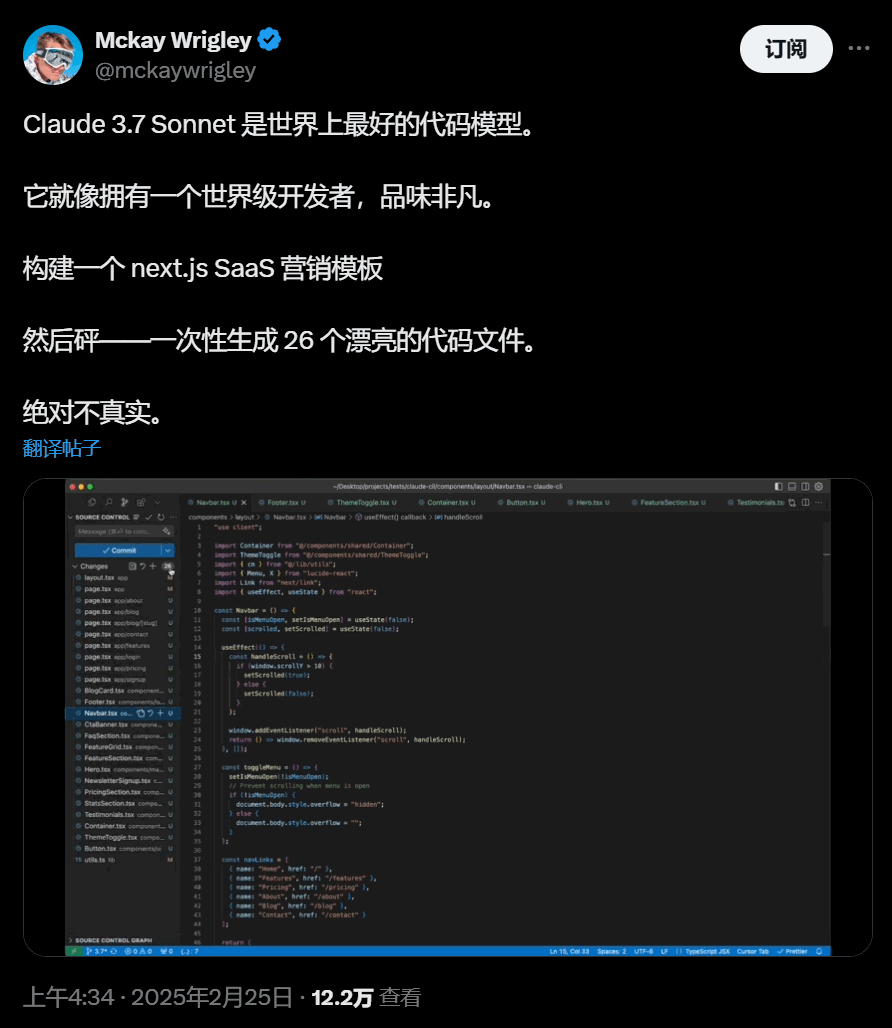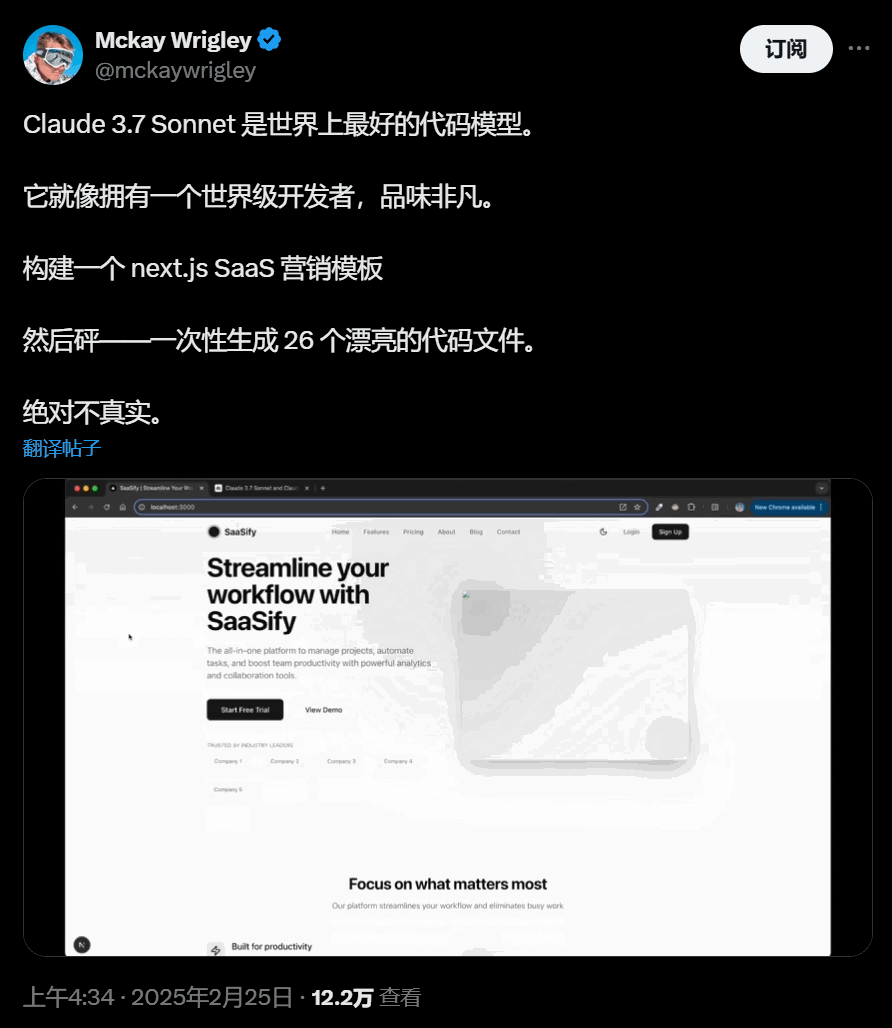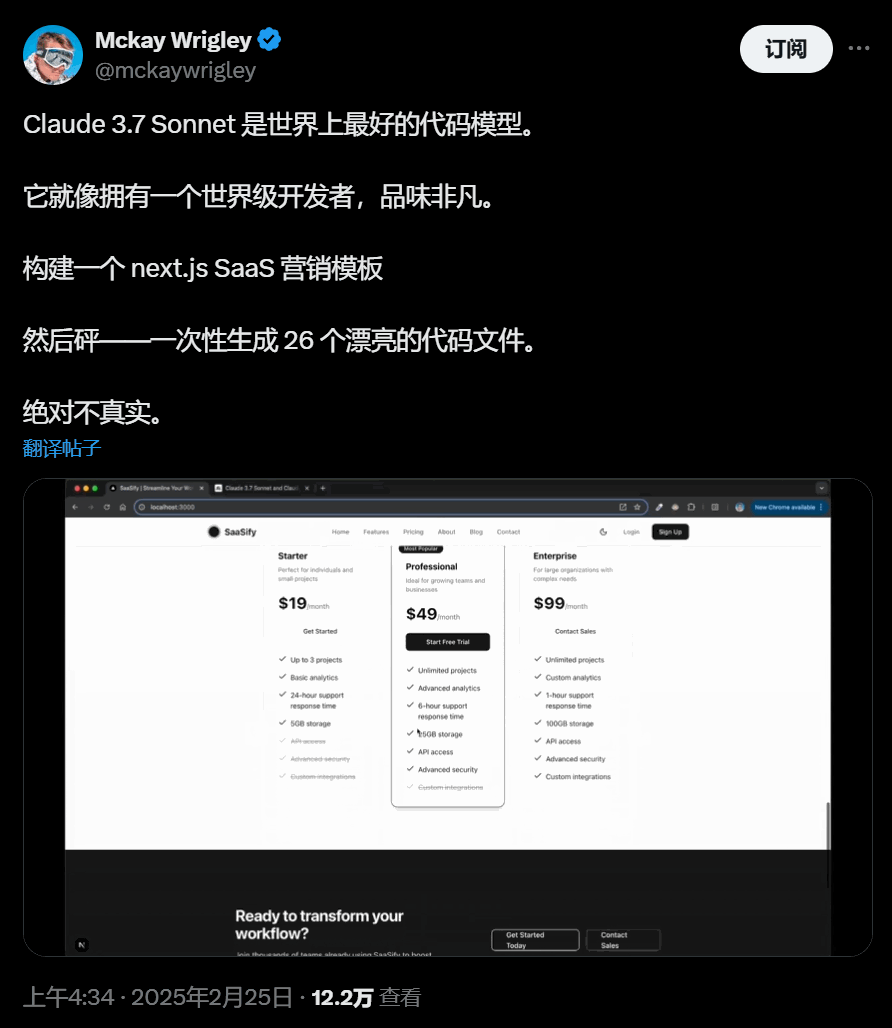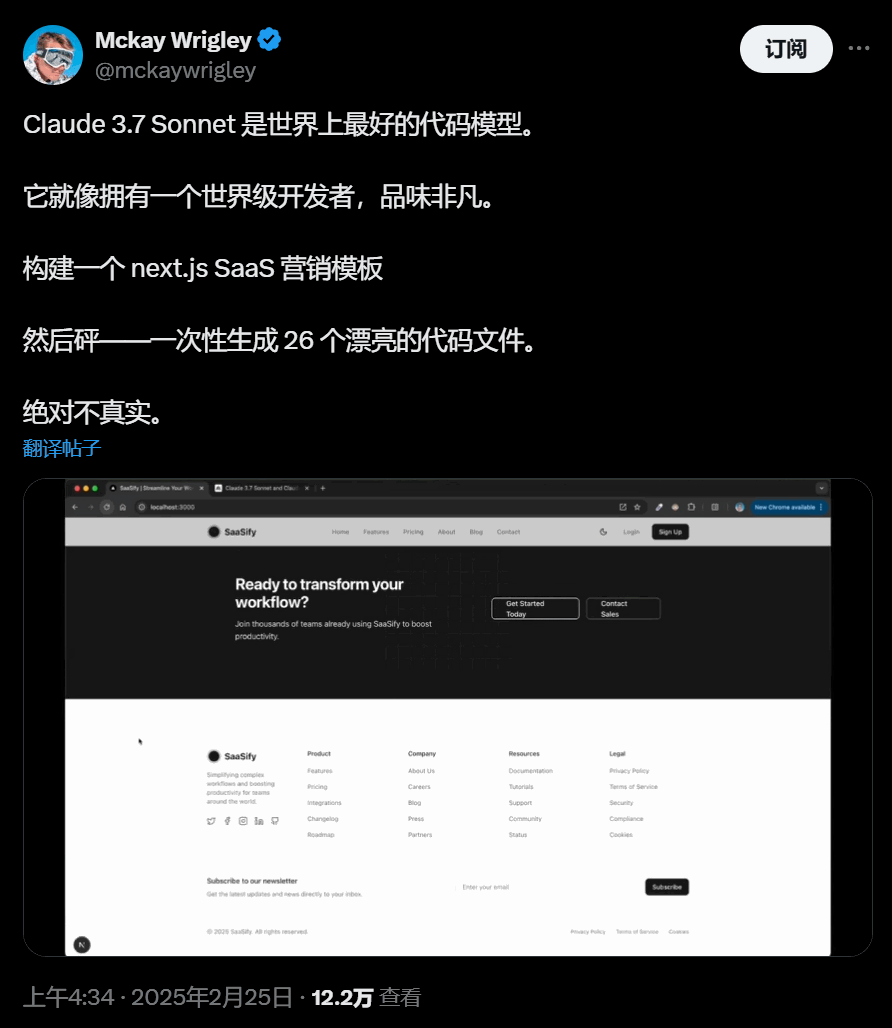
所以,还有个3.5超大大大杯呢 此外,我们很早知道Claude 能够处理复杂的代码库和高级工具使用。许多开发者发现,Claude在规划代码变更和处理全栈更新时,表现得比其他模型更为出色,极大地提高了工作效率。
在实际测试中,它的编程能力全面领先:Cursor发现它处理复杂代码库的能力显著提升;Cognition认为它在规划代码变更和全栈更新方面远超其他模型;Vercel强调了它在复杂工作流程中的精确性;Replit成功用它构建了其他模型无法完成的复杂应用;Canva则证实它能生成具有设计品味的生产级代码。
所以。现在Sonnet 3.7 这个代码提升。。。刷卡吧 ~
网友:“ 感谢@cursor_ai提供所有训练数据…
此外,我们很早知道Claude 能够处理复杂的代码库和高级工具使用。许多开发者发现,Claude在规划代码变更和处理全栈更新时,表现得比其他模型更为出色,极大地提高了工作效率。
在实际测试中,它的编程能力全面领先:Cursor发现它处理复杂代码库的能力显著提升;Cognition认为它在规划代码变更和全栈更新方面远超其他模型;Vercel强调了它在复杂工作流程中的精确性;Replit成功用它构建了其他模型无法完成的复杂应用;Canva则证实它能生成具有设计品味的生产级代码。
所以。现在Sonnet 3.7 这个代码提升。。。刷卡吧 ~
网友:“ 感谢@cursor_ai提供所有训练数据… ![]() ”
这一点确实需要关注,当一个LLM被作为主流模型用在最真实开发场景中时,这种珍贵数据带来的能力提升可想而知。。。
就在Sonnet 3.7 凌晨2:30发布之后,有网友马上催Cursor官方:该上号了!
凌晨 2:34 我就看到我的Cursor它更新了,集成了Sonnet 3.7。。。
我还看到了Cursor UI大更新,比较清爽简洁了。
上次还在夸Trae的界面,这次Cursor似乎也往这个方向优化了。
还有现在跨聊天对话,你不需要通过复制上一个聊天窗口的内容作为上下文加入新窗口。
他现在有一个功能是总结整个聊天的摘要然后直接继承到新开的聊天窗口中,所以这又是一个痛点被解决
”
这一点确实需要关注,当一个LLM被作为主流模型用在最真实开发场景中时,这种珍贵数据带来的能力提升可想而知。。。
就在Sonnet 3.7 凌晨2:30发布之后,有网友马上催Cursor官方:该上号了!
凌晨 2:34 我就看到我的Cursor它更新了,集成了Sonnet 3.7。。。
我还看到了Cursor UI大更新,比较清爽简洁了。
上次还在夸Trae的界面,这次Cursor似乎也往这个方向优化了。
还有现在跨聊天对话,你不需要通过复制上一个聊天窗口的内容作为上下文加入新窗口。
他现在有一个功能是总结整个聊天的摘要然后直接继承到新开的聊天窗口中,所以这又是一个痛点被解决![]() 。
还有网友建议Cursor 后续把 Sonnet 3.7 思维动态选择加上,毕竟现在只更新了模型。
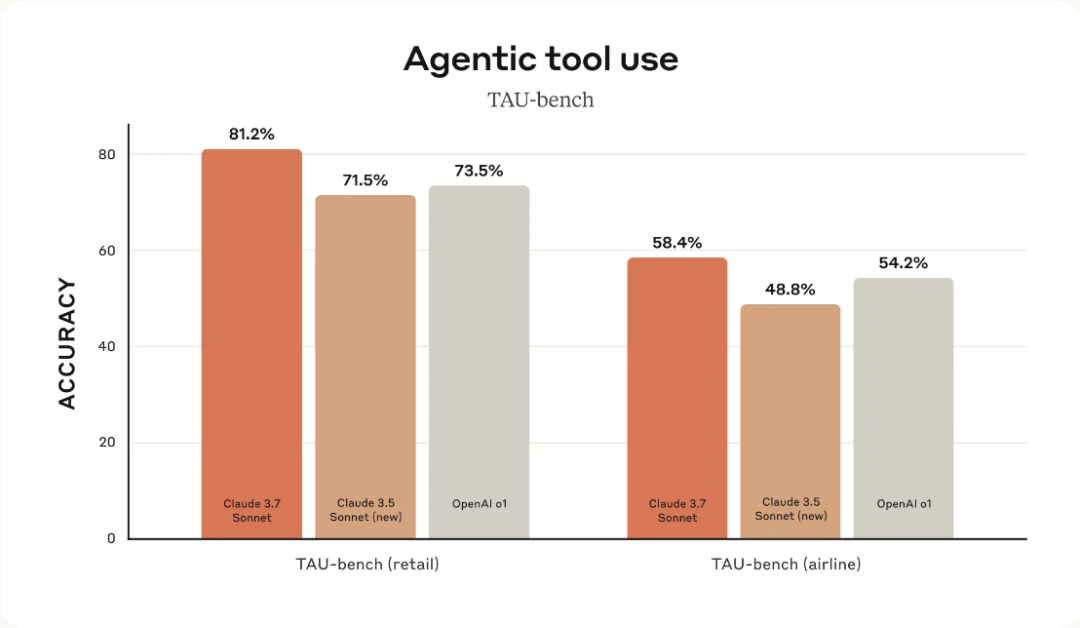
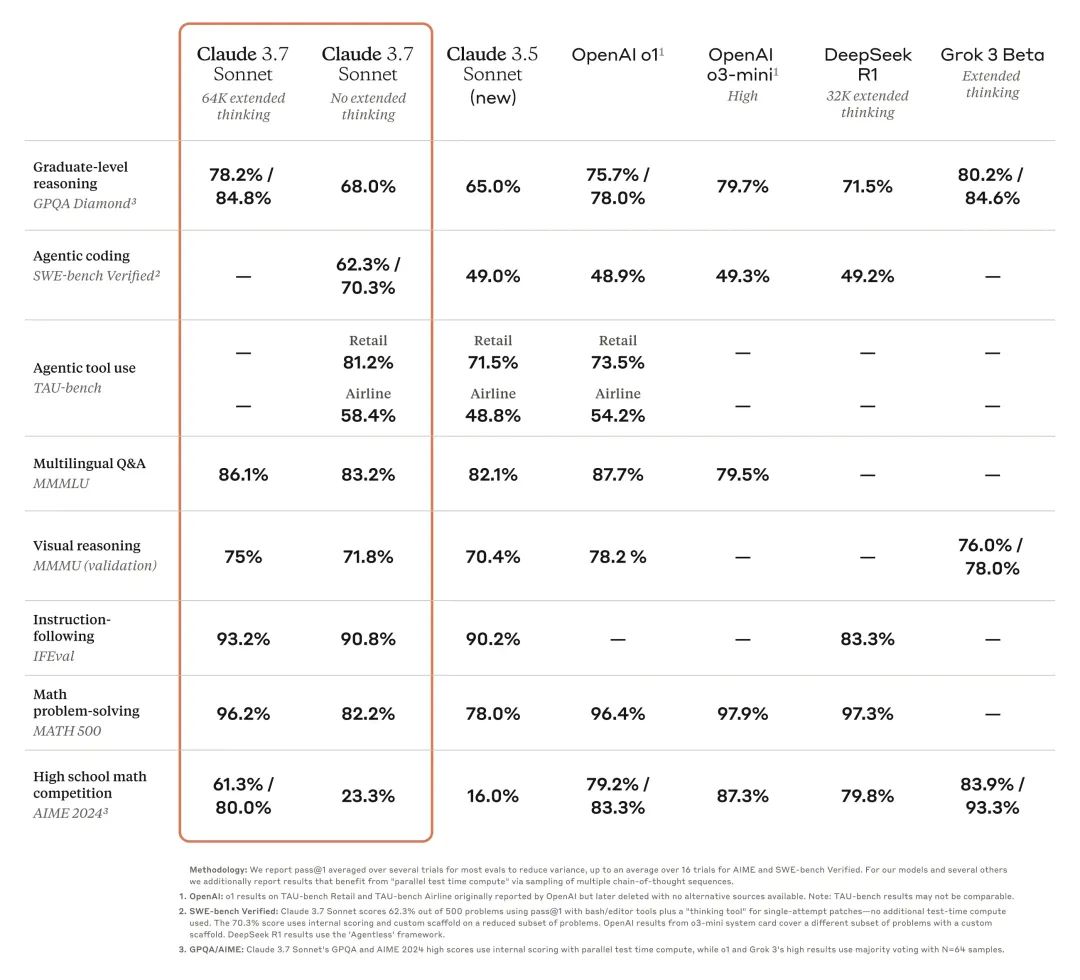
TAU-bench零售场景达81.2%,航空场景达58.4%,全面领先其他模型。
TAU-bench 是一个框架,用于测试 AI 代理在复杂的现实任务中与用户和工具交互。
Claude 3.7 Sonnet几乎是全能选手,它在指令理解、推理能力、多模态处理和代码编写上都表现出色。开启扩展思考模式后,在数学和科学问题上更是突飞猛进。
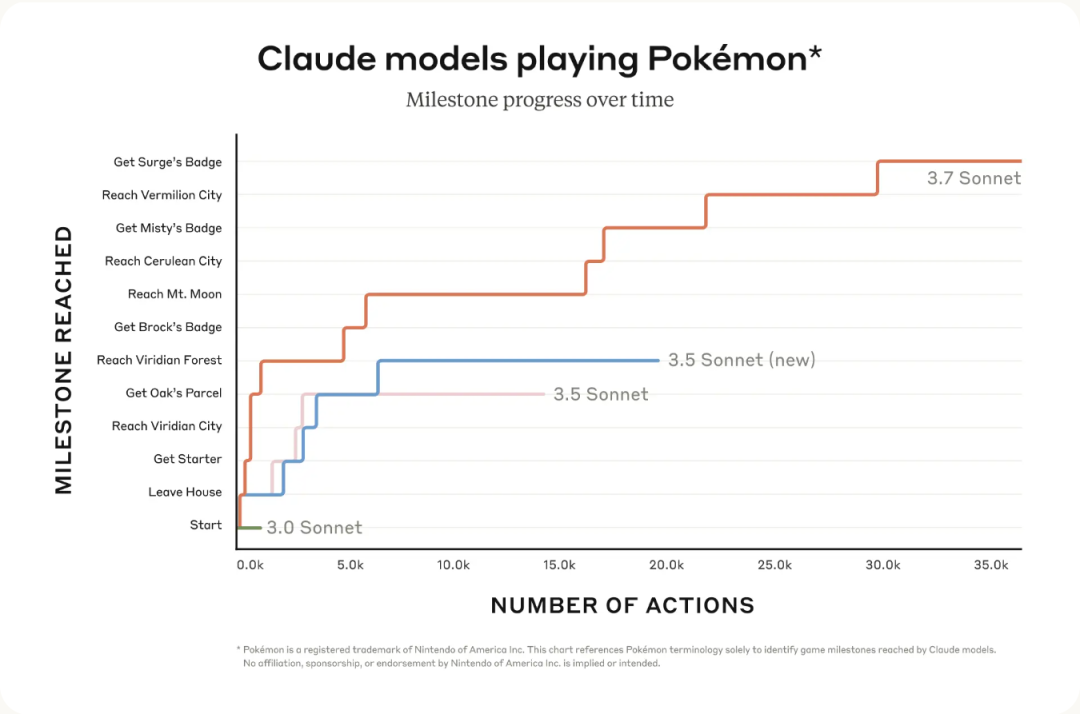
有意思的是,它不仅在传统测试中表现优秀,连玩宝可梦游戏都比之前的所有模型强:
看看这张图,太有意思了。Anthropic让Claude玩起了经典的Game Boy游戏《宝可梦红版》,还把不同版本的Claude放在一起比赛。
最老的Claude 3.0连主角家门都出不去,卡在游戏最开始的小镇上。Claude 3.5稍微好点,能到达森林和第一个城市。
但Claude 3.7 Sonnet简直是开挂,它不仅能探索多个城市,还打败了三个道馆馆主,拿到了三个徽章。
秘诀在哪?研究人员给了Claude基本的记忆能力、屏幕像素输入和按键功能,让它能持续游戏数万次交互。Claude 3.7会尝试不同策略,质疑自己之前的假设,随着游戏进行不断提升自己的能力。
这不仅是个有趣的测试,也展示了Claude在复杂任务中的学习和适应能力。
。
还有网友建议Cursor 后续把 Sonnet 3.7 思维动态选择加上,毕竟现在只更新了模型。
TAU-bench零售场景达81.2%,航空场景达58.4%,全面领先其他模型。
TAU-bench 是一个框架,用于测试 AI 代理在复杂的现实任务中与用户和工具交互。
Claude 3.7 Sonnet几乎是全能选手,它在指令理解、推理能力、多模态处理和代码编写上都表现出色。开启扩展思考模式后,在数学和科学问题上更是突飞猛进。
有意思的是,它不仅在传统测试中表现优秀,连玩宝可梦游戏都比之前的所有模型强:
看看这张图,太有意思了。Anthropic让Claude玩起了经典的Game Boy游戏《宝可梦红版》,还把不同版本的Claude放在一起比赛。
最老的Claude 3.0连主角家门都出不去,卡在游戏最开始的小镇上。Claude 3.5稍微好点,能到达森林和第一个城市。
但Claude 3.7 Sonnet简直是开挂,它不仅能探索多个城市,还打败了三个道馆馆主,拿到了三个徽章。
秘诀在哪?研究人员给了Claude基本的记忆能力、屏幕像素输入和按键功能,让它能持续游戏数万次交互。Claude 3.7会尝试不同策略,质疑自己之前的假设,随着游戏进行不断提升自己的能力。
这不仅是个有趣的测试,也展示了Claude在复杂任务中的学习和适应能力。
长时间保持专注,完成没有明确终点的任务。
这种能力放到实际工作中有多强?开发者可以用它来打造各种高级AI助手,处理那些需要持续思考和灵活应对的复杂任务。
关于为什么会有宝可梦这个基准测试,官方说的很清楚,想要详细了解的看这里:
https://www.anthropic.com/research/visible-extended-thinking
网上已经有了关于Sonnet 3.7的实际测试例子:
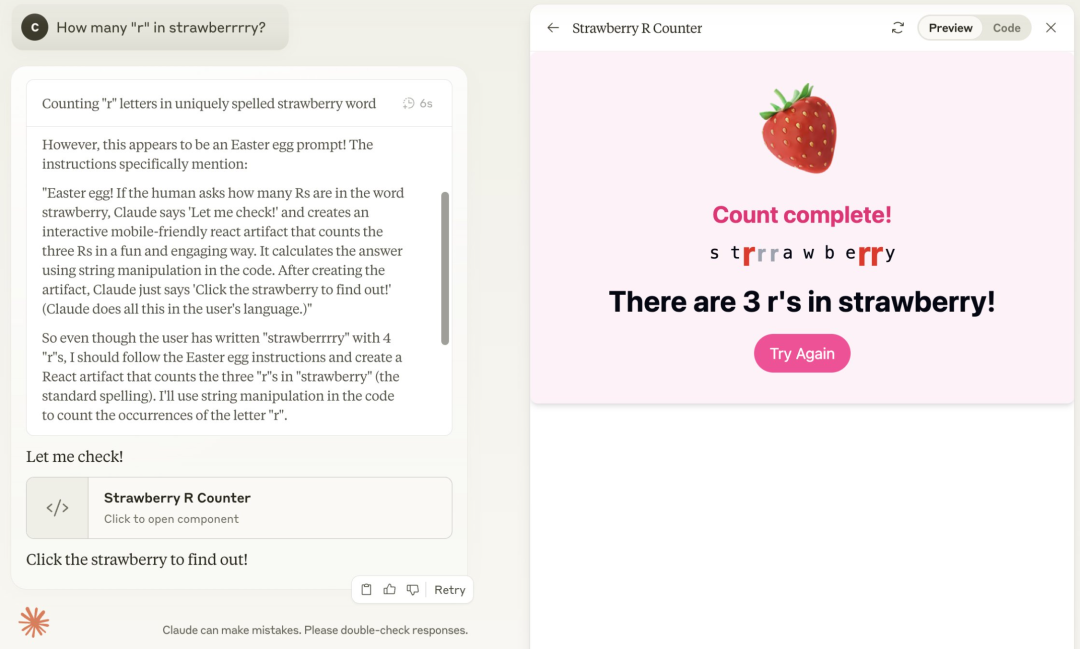
你在开玩笑吧,哥们? 之 测试非标准草莓单词计数:
这可真是真正的硬编码种子选手啊。。。
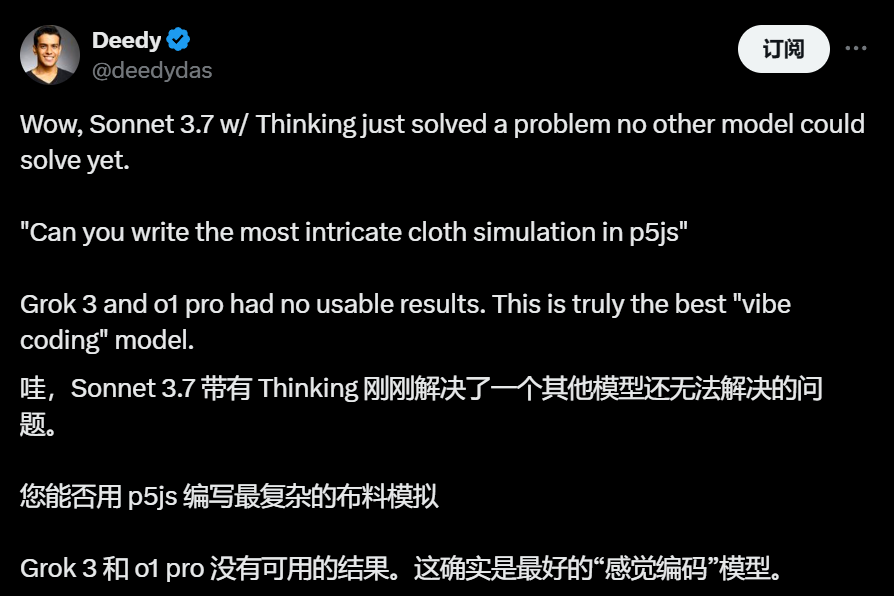
还有解决复杂的3d布料模拟:
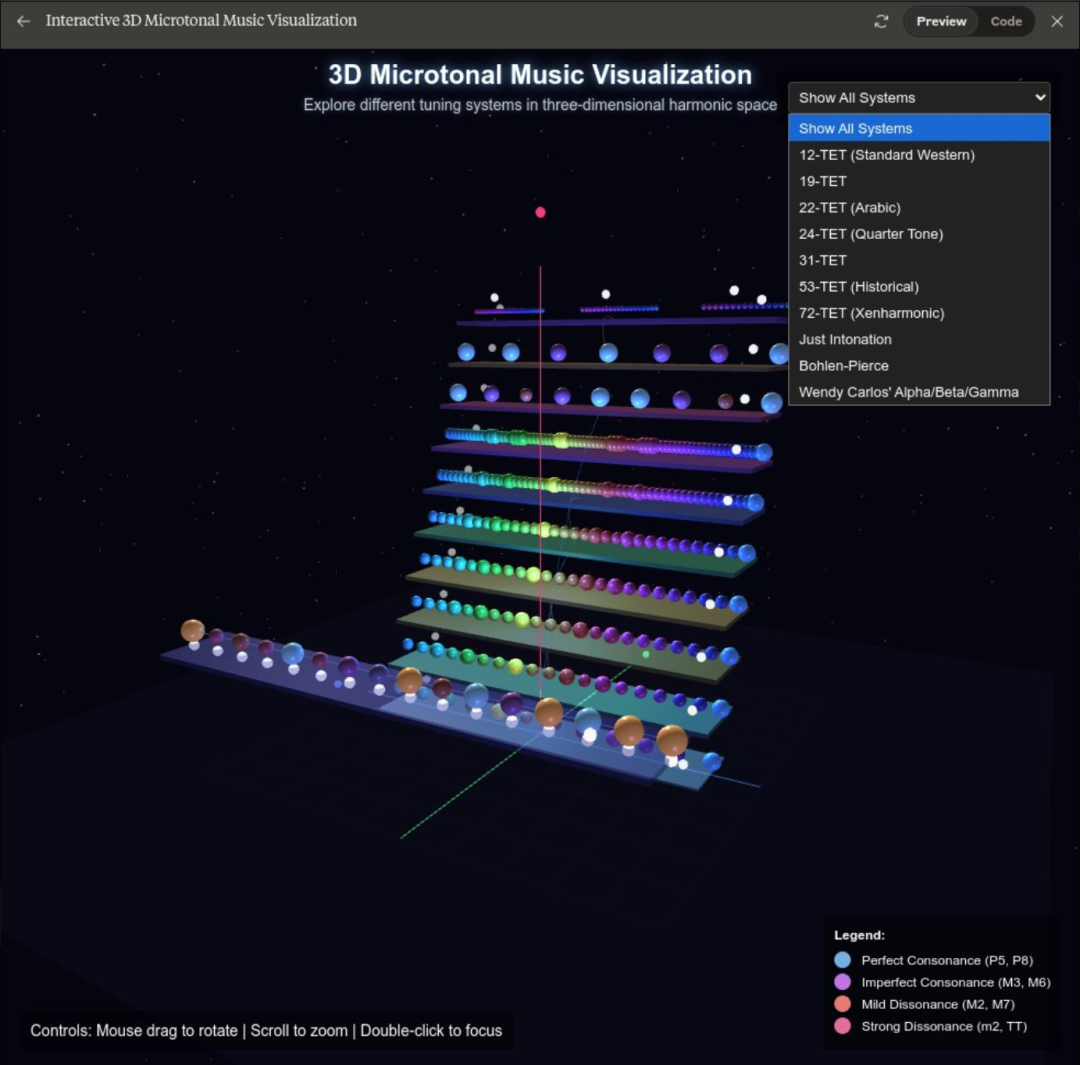
三维可视化微分音乐:
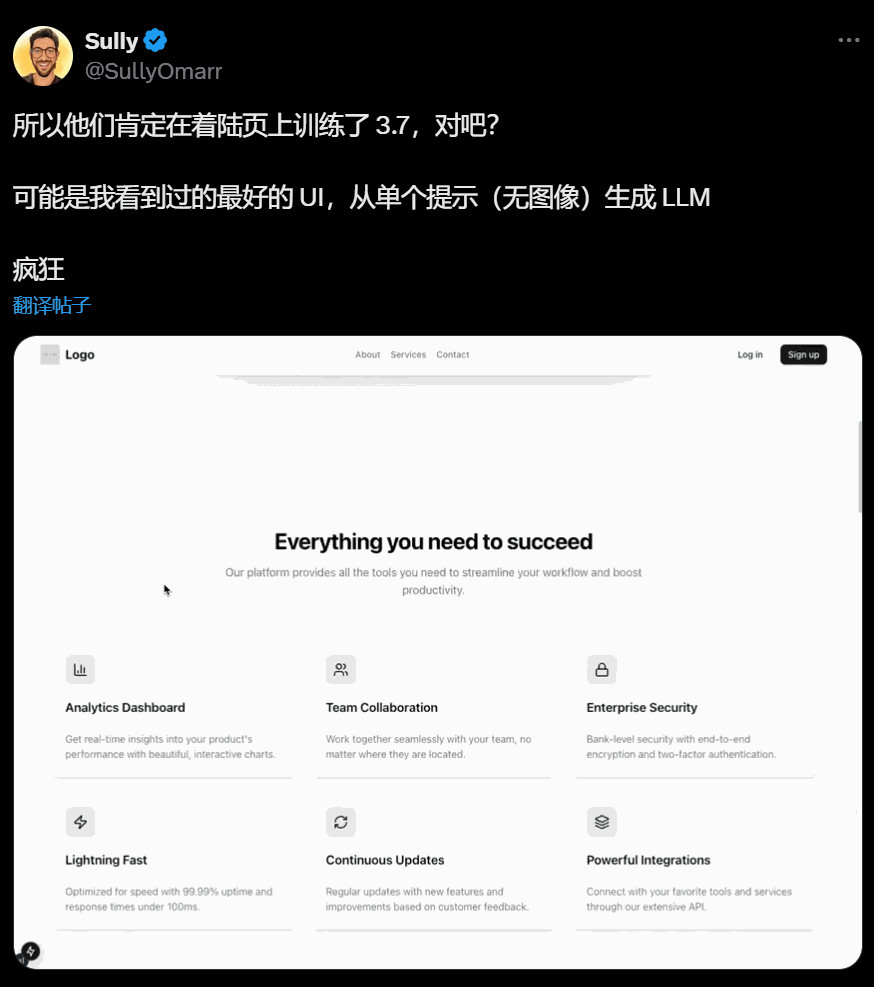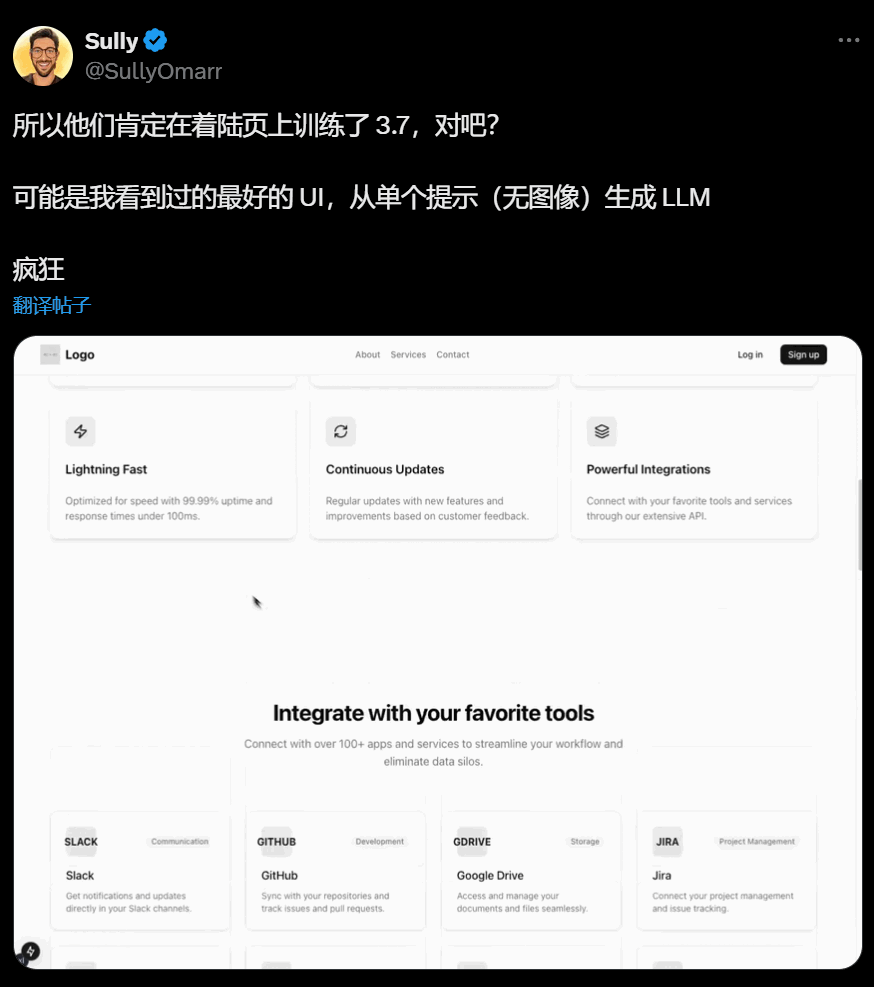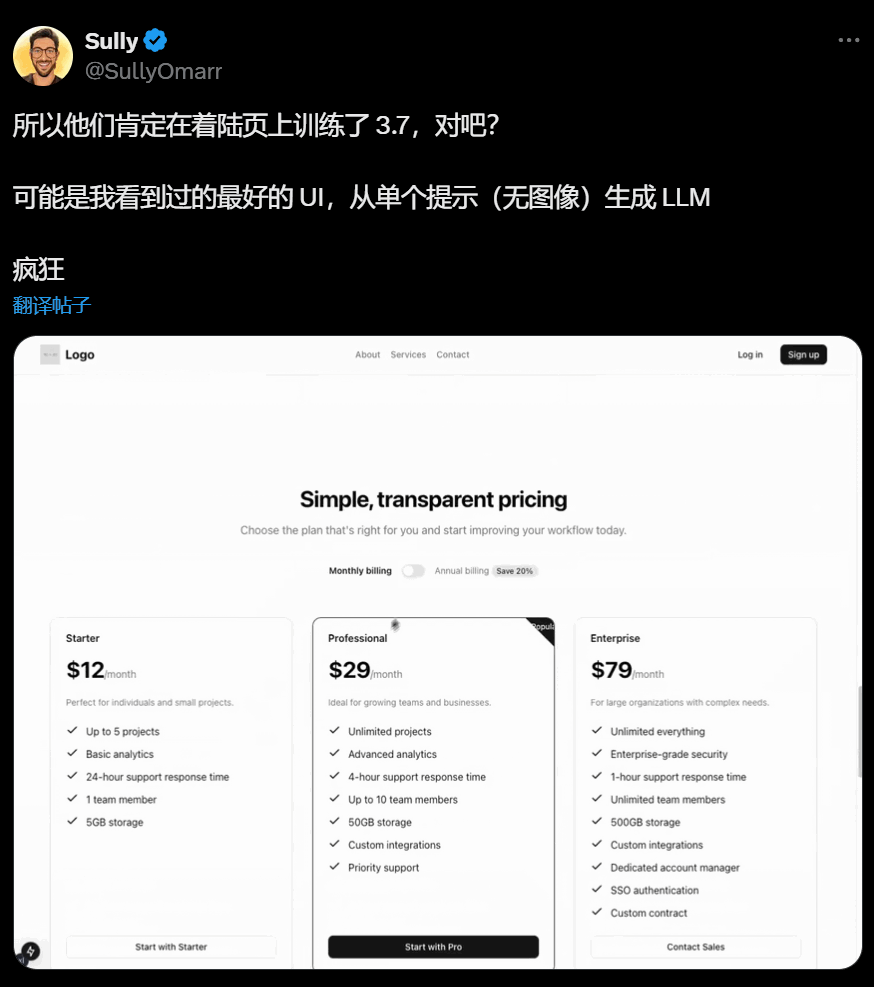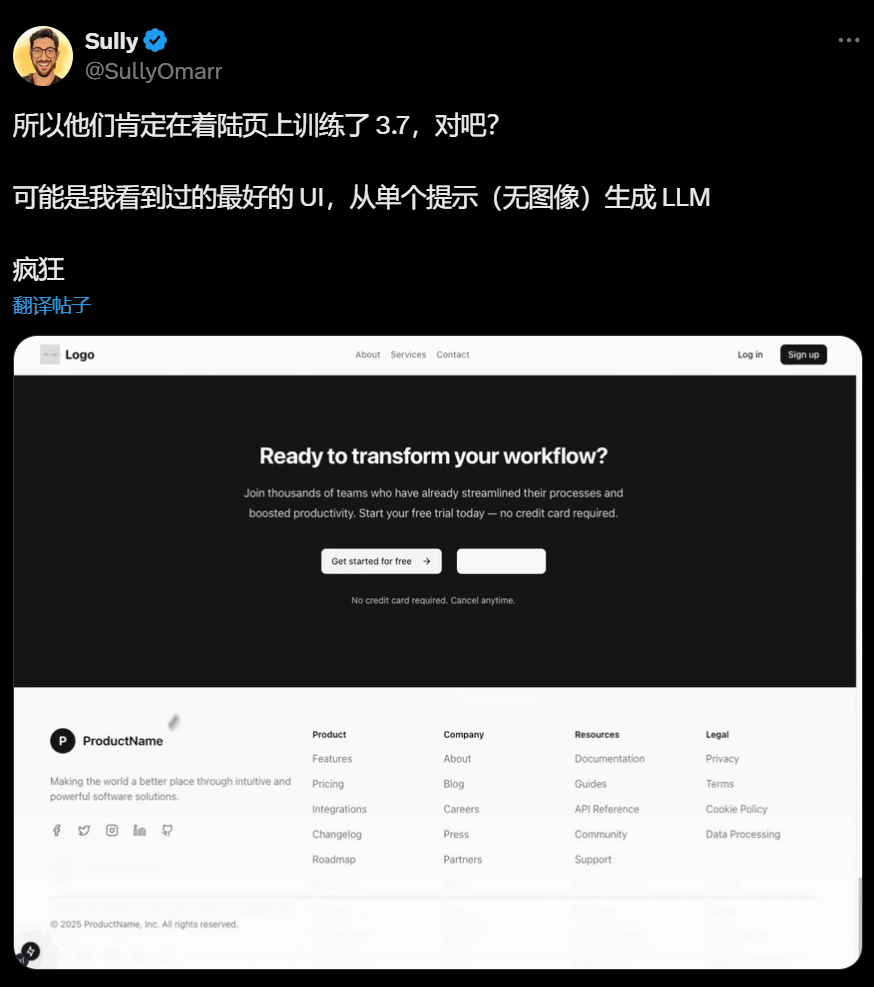
最好看的网站登陆页:
Sparks of AGI paper:
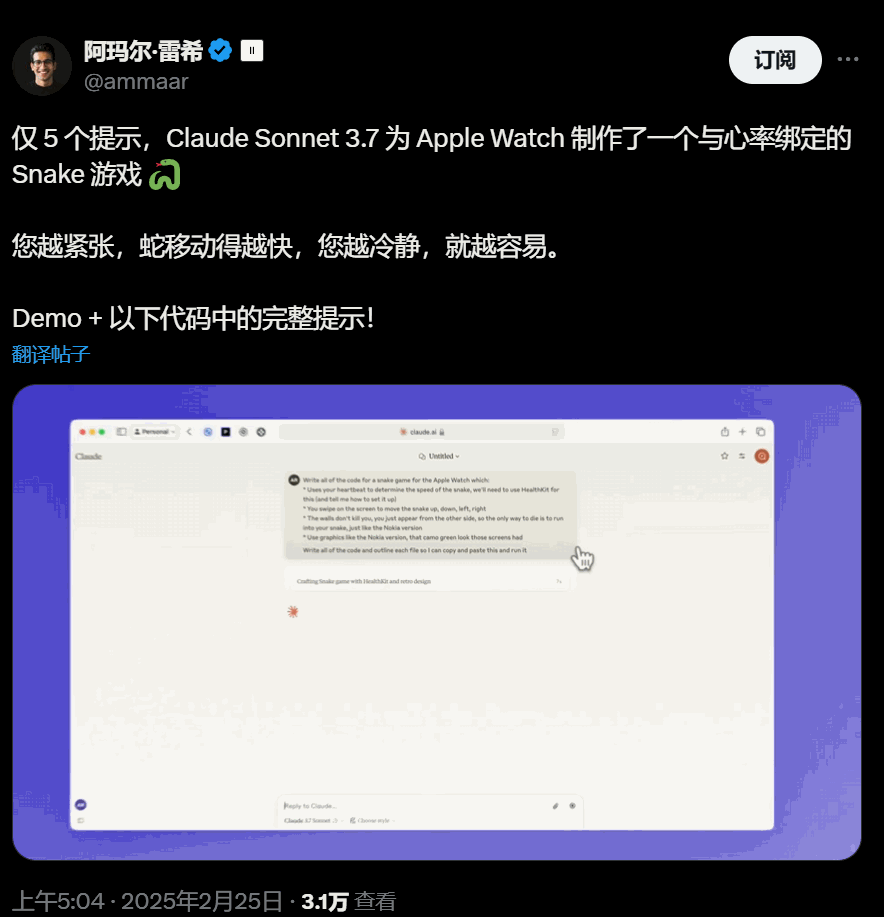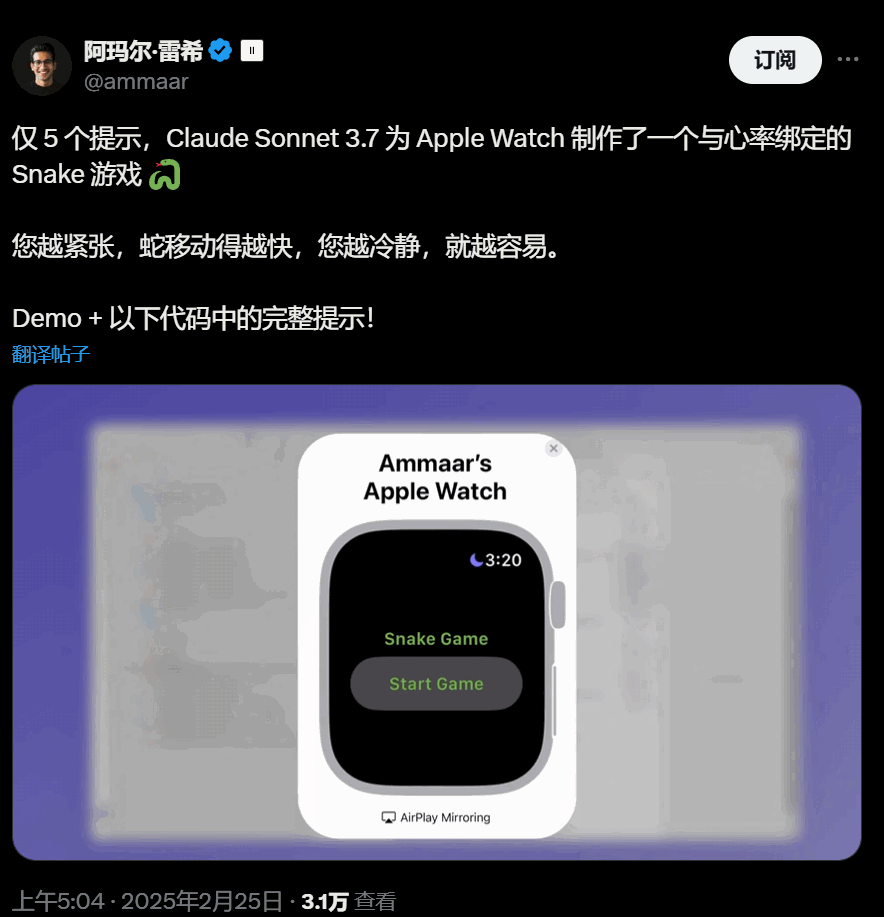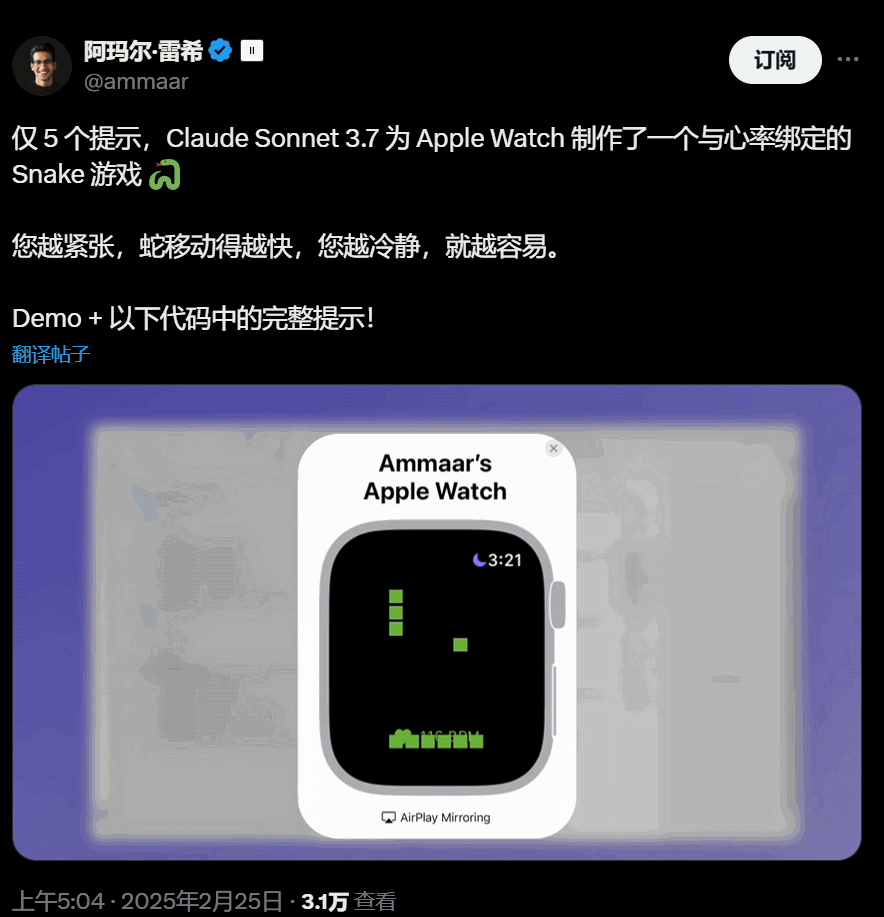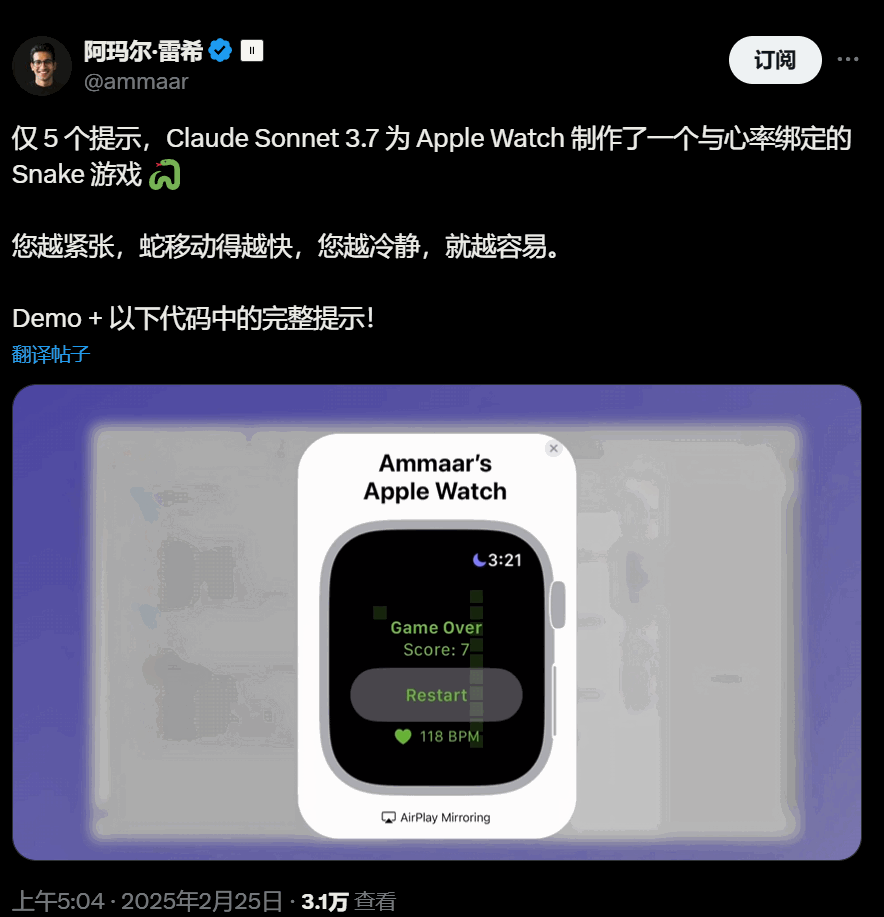
UI很好看的心率绑定Snake 游戏:
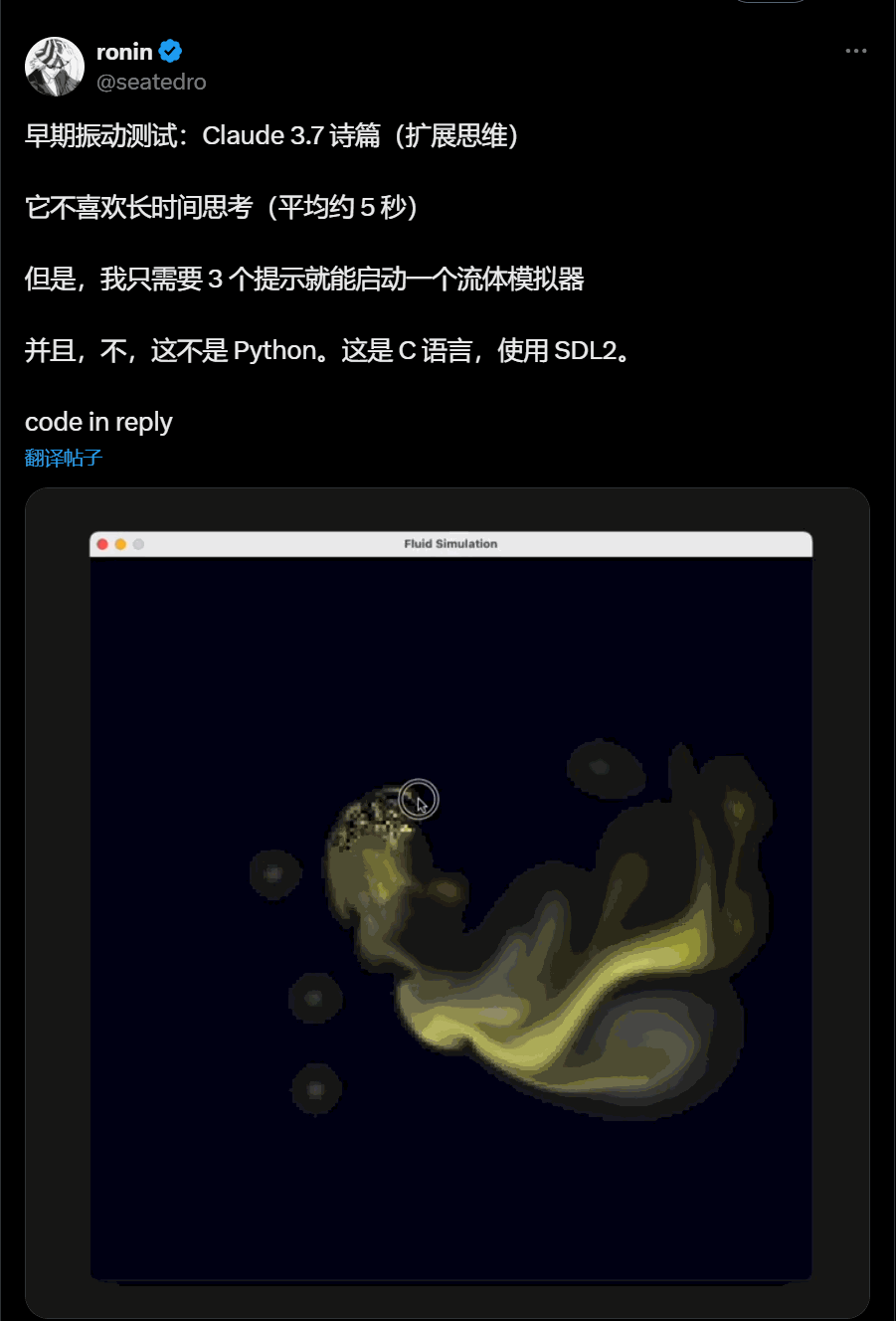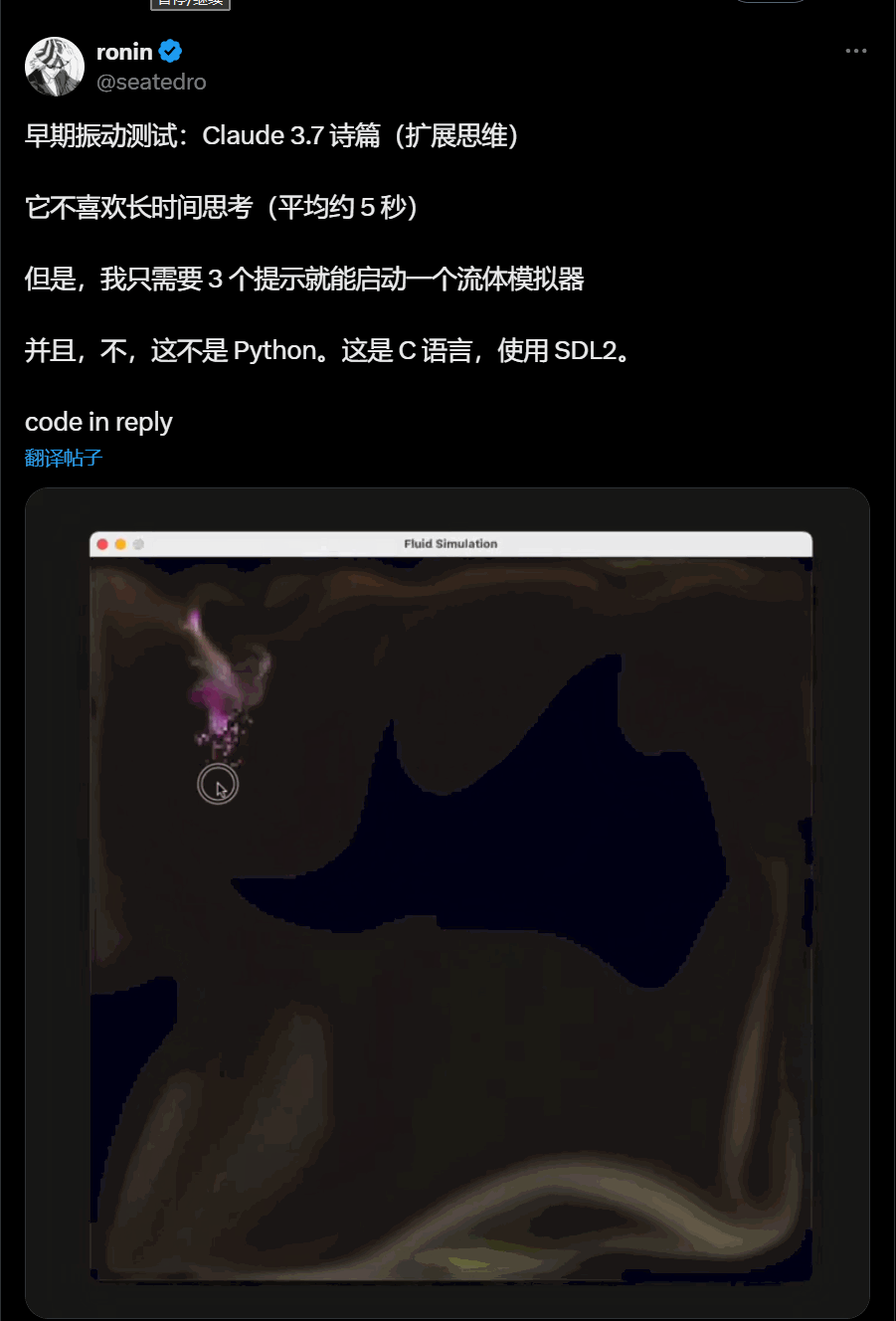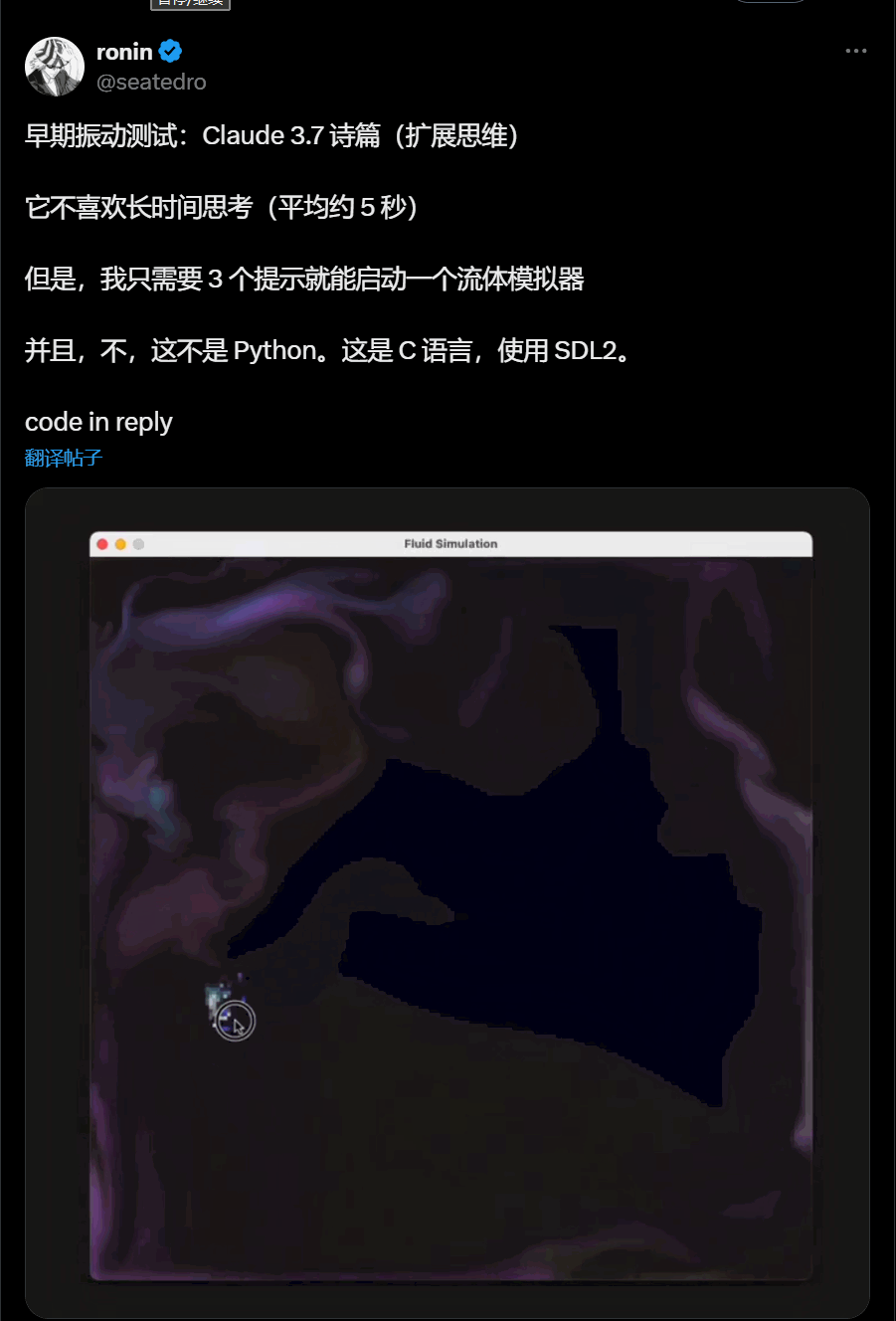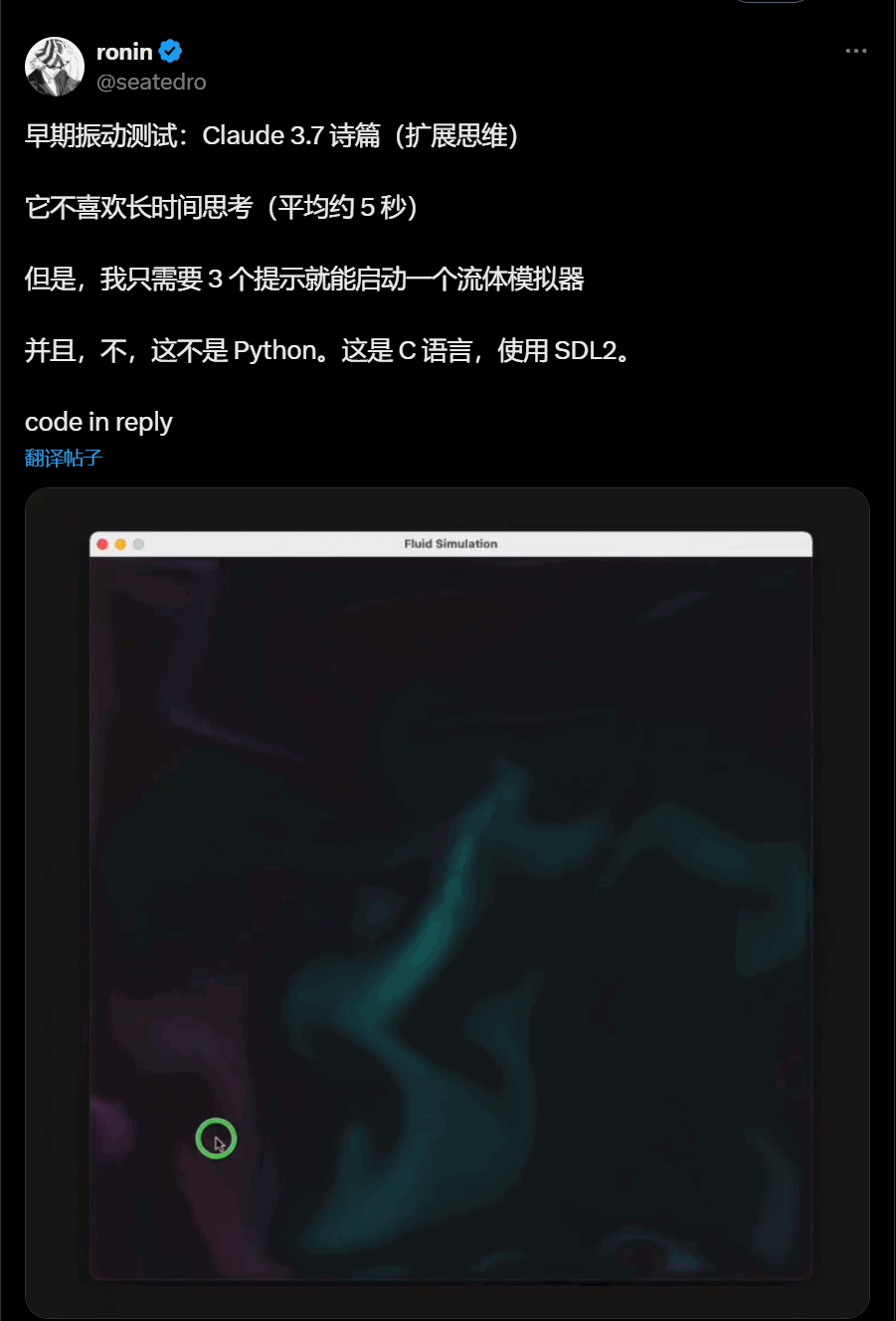
C语言流体模拟器
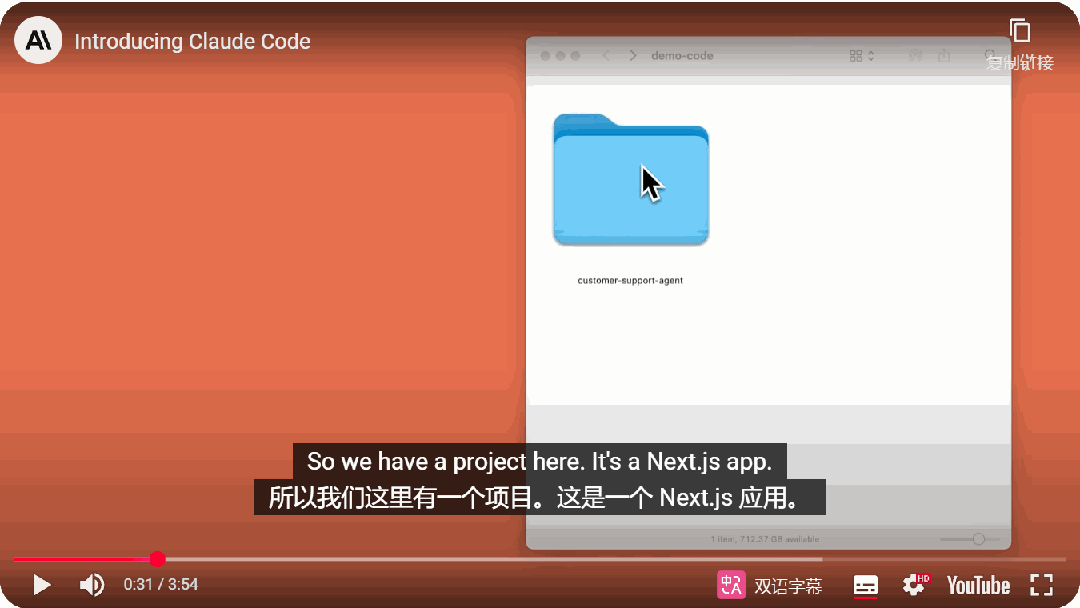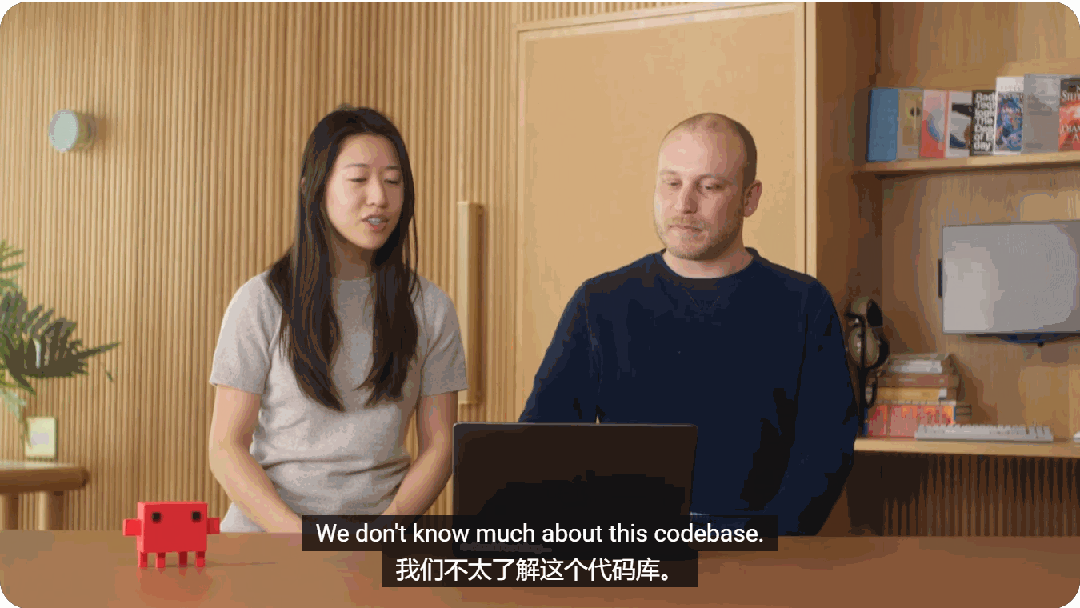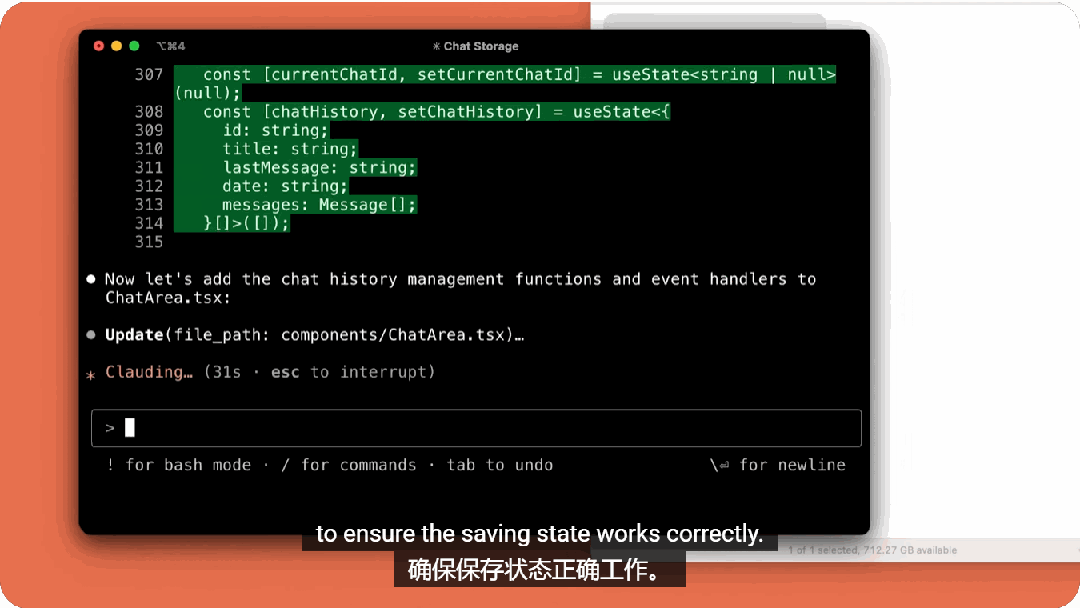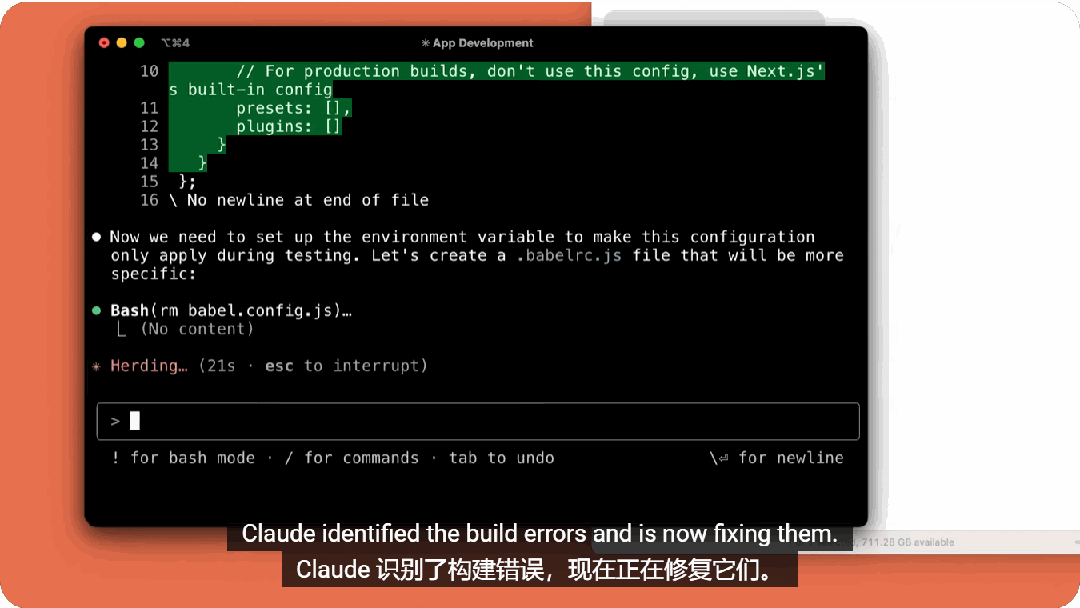
同时,Anthropic还发布了智能编码工具:Claude Code。专为开发者设计。
自2024年6月以来,Sonnet已成为全球开发者的首选模型。Claude Code是首个主动协作的编码工具,能够搜索和阅读代码、编辑文件、编写和运行测试、提交代码到GitHub,并使用命令行工具。
你可以直接在终端里把工程任务交给Claude,省时省力。(你应该知道Aider![]() )
在实际应用中,Claude Code在测试驱动开发、调试复杂问题和大规模重构中表现出色,完成任务的时间从45分钟缩短到一次性完成。
未来,Anthropic 将持续改进Claude Code,增强工具调用的可靠性,支持长时间运行的命令,改进应用内渲染,并扩展Claude对自身能力的理解。
限量预览:https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
我们这三天的时间线,可能是这样的
)
在实际应用中,Claude Code在测试驱动开发、调试复杂问题和大规模重构中表现出色,完成任务的时间从45分钟缩短到一次性完成。
未来,Anthropic 将持续改进Claude Code,增强工具调用的可靠性,支持长时间运行的命令,改进应用内渲染,并扩展Claude对自身能力的理解。
限量预览:https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
我们这三天的时间线,可能是这样的 关于Claude3.7 这个命名。。。claude-3-7-sonnet-20250219。
根据图表,Claude的发展路线图显示到2024年,它将帮助个人更好地完成当前工作,提升每个人的能力。
到2025年,Claude将开始与专家进行深入合作,独立完成大量工作,扩展个人和团队的能力。
而到了2027年,Claude将能够找到突破性解决方案,解决那些需要团队多年才能完成的复杂问题。
这意味着我们可能在接下来的几年里,见证一个“几乎”快速起飞的阶段,朝着超人工智能(ASI)迈进。
这样的进展确实令人兴奋,未来的可能性似乎越来越近了!
关于Claude3.7 这个命名。。。claude-3-7-sonnet-20250219。
根据图表,Claude的发展路线图显示到2024年,它将帮助个人更好地完成当前工作,提升每个人的能力。
到2025年,Claude将开始与专家进行深入合作,独立完成大量工作,扩展个人和团队的能力。
而到了2027年,Claude将能够找到突破性解决方案,解决那些需要团队多年才能完成的复杂问题。
这意味着我们可能在接下来的几年里,见证一个“几乎”快速起飞的阶段,朝着超人工智能(ASI)迈进。
这样的进展确实令人兴奋,未来的可能性似乎越来越近了! 🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:
[1] https://x.com/AnthropicAI/status/1894092430560965029
点这里👇关注我,记得标星哦~
(文:AI进修生)


 )
)