


今日凌晨,Anthropic 宣布推出其“迄今为止最智能的模型” Claude 3.7 Sonnet,这也是全球首个混合推理模型。据官方介绍,Claude 3.7 Sonnet 不仅可以给出近乎即时的回答,还可以生成可扩展的、逐步思考的结果,甚至用户还能通过 API 精确控制模型的思考时间。

Anthropic 强调,Claude 3.7 Sonnet 的开发理念与市场上其他推理模型不同:“就像人类用同一个大脑进行快速反应和深入思考一样,我们认为推理应该是前沿模型的一项综合能力,而不是一个完全独立的模型。”
因此,Claude 3.7 Sonnet 集普通 LLM 和推理模型于一身:在「标准」模式下,Claude 3.7 Sonnet 是 Claude 3.5 Sonnet 的升级版,快速输出答案;而在「扩展思考」模式下,它在回答问题前可以进行自我反思,从而提高其在数学、物理、指令跟踪、编码和许多其他任务中的性能。
其中,Claude 3.7 Sonnet 在编码方面的表现尤为突出,Anthropic 表示:“Claude 3.7 Sonnet 是我们迄今为止最好的编码模型。”
早期测试表明,Claude 3.7 Sonnet 的编码能力方面全面领先:在 SWE-bench Verified(一个用于评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集)测试中,它不仅超越了前代 Claude 3.5 Sonnet,还明显优于 OpenAI o1、DeepSeek R1 等其他模型。
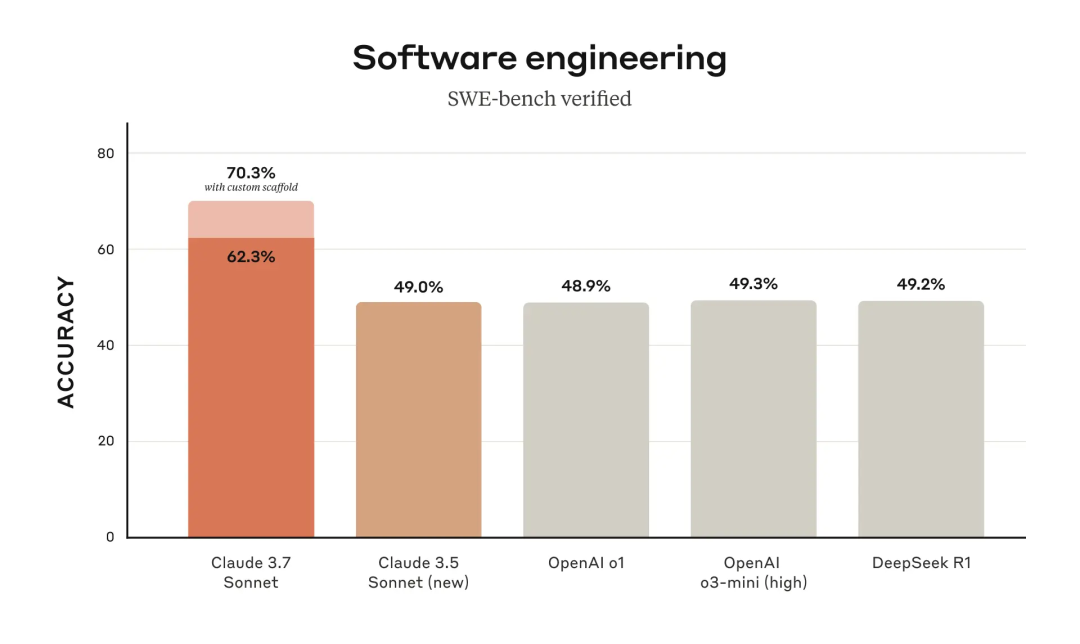
伴随 Claude 3.7 Sonnet 一同推出的还有 Claude Code ——这是 Anthropic 首次推出的代理编程工具,可以搜索和读取代码、编辑文件、编写和运行测试、提交代码并将其推送到 GitHub,还可以使用命令行工具……也就是说,开发者可以直接向 Claude Code 委派大量的工程任务。
目前,Claude Code 还只是一款早期产品,仅可作为有限的研究预览版提供,但已成为 Anthropic 内部团队不可或缺的工具。据介绍,Claude Code 曾在一次测试中,一次性完成了通常需要 45 分钟以上手动工作的任务,显著减少了开发时间和工作量,在测试驱动开发、调试复杂问题和大规模重构方面更是很大程度上解放了开发者。Anthropic 透露道,未来几周内将继续改进 Claude Code,包括增强工具调用的可靠性、支持长时间运行的命令、改进应用内渲染,并扩展模型对自身能力的理解。
值得一提的是,除了编码能力,「扩展思考」模式下的 Claude 3.7 Sonnet 在多项基准测试中各方面几乎也都处于领先地位,与用了 20 万张 GPU 训练的 Grok 3 不相上下——从已有的测试数据来看,Anthropic 所说的“迄今为止最智能的模型”,至少目前来看是成立的。

当前,Claude 3.7 Sonnet 适用于所有 Claude 计划,包括免费、专业、团队和企业计划,以及 Anthropic API、亚马逊 Bedrock 和谷歌云的 Vertex AI;而「扩展思考模式」适用于除免费 Claude 计划以外的所有计划。
最后在价格方面,Claude 3.7 Sonnet 的定价与前代产品相同:不论是「标准模式」还是「扩展思考模式」,都是每百万输入 Token 3 美元,每百万输出 Token 15 美元(包括推理过程中消耗的 Token)。
原文链接:https://www.anthropic.com/news/claude-3-7-sonnet


(文:AI科技大本营)