
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今早9点,DeepSeek开启了本周连续5天技术分享的第3天,开源了专用于执行高效FP8精度矩阵乘法运算库——DeepGEMM。
DeepGEMM的核心代码仅300行,但在GPU上可实现高达每秒1350 + FP8 万亿次浮点运算性能。在大多数矩阵规模下性能超过了专家调优的内核,同时支持密集布局和两种 MoE 布局,适配不同的运算场景。

开源地址:https://github.com/deepseek-ai/DeepGEMM
看到DeepSeek又发布高效训练方法,网友表示,英伟达股票又要下跌了。

在澳大利亚都能听到英伟达股票下跌的惨叫声~

DeepGEMM听起来就像数学界的超级英雄。比快速计算器更快,比多项式方程更强大。我试着用了一下,现在我的GPU正在炫耀它的1350+ TFLOPS,好像准备参加AI奥运会一样!
DeepGEMM正在改变我们使用FP8 通用矩阵乘法库的方式,简单、快速且开源。这就是人工智能计算的未来。
DeepSeek可能正在揭开英伟达那些不能说的秘密。我怀疑英伟达是故意这么做的,目的是为了卖出更多的显卡。恭喜马斯克的 20 万张显卡变成了 100 万张。把马斯克送到火星去,再带上黄仁勋。
「AIGC开放社区」就简单为大家解读一下DeepGEMM。GEMM,全称是General Matrix Multiplication,是线性代数中的一个基本操作,用于计算两个矩阵的乘积。
例如,假设我们有两个矩阵A和B,矩阵A的大小是 3×2,矩阵B的大小是 2×4,那么通过GEMM 计算后,我们可以得到一个大小为 3×4 的矩阵 C,即C=A × B。
这种矩阵乘法在深度学习中非常重要,尤其是在神经网络的全连接层和卷积层中,几乎每一个前向传播和反向传播的步骤都离不开它。
FP8 是一种8位浮点数格式,由 NVIDIA Hopper 架构引入。与传统的 32 位浮点数或16位浮点数相比,FP8 占用的内存和计算资源更少,但同时在某些应用场景下仍能保持足够的精度。
例如,一个传统的 FP32 数字占用 4 个字节,而FP8 只占用 1 个字节,这意味着在相同的内存容量下,我们可以存储更多的数据,从而加速大规模深度学习模型的训练和推理,尤其适合硬件资源有限的情况。
而DeepSeek版本的GEMM是专为NVIDIA Hopper 架构设计的GEMM库,并且所有内核在运行时动态编译。
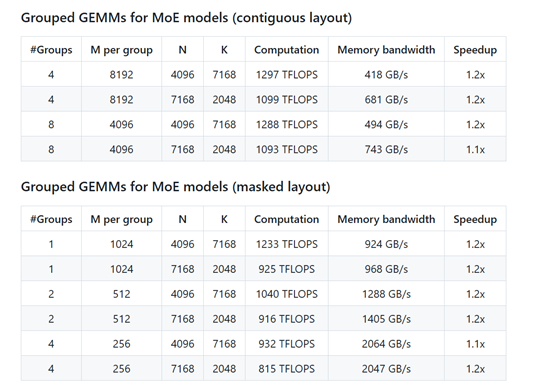
在性能方面,DeepGEMM 在 NVIDIA H800 GPU 上进行了广泛的测试,结果表明它在多种矩阵形状下都能显著提升计算速度。例如,在密集矩阵乘法中,某些形状的性能提升可达 2.7 倍;而在 MoE 模型的分组矩阵乘法中,性能提升也达到了 1.2 倍左右。
DeepGEMM采用了多种优化技术。它通过持久化的 warp 专业化,重叠数据传输、张量核心 MMA 指令和 CUDA 核心提升操作,优化了计算流程。还利用了Hopper 架构的张量内存加速器特性,实现更快的数据传输和异步操作。
为了应对 FP8 张量核心累加精度不足的问题,DeepGEMM 采用了 CUDA 核心的双级累加技术。还采用了完全 JIT 设计,所有内核在运行时动态编译,能够根据具体的矩阵形状和硬件特性进行优化。
此外,DeepGEMM 支持非 2 的幂次方的块大小,以提高 GPU 的利用率,并通过修改编译后的二进制指令优化细粒度缩放的性能。
使用方面很方便,DeepGEMM提供了简洁的 Python 接口,方便用户在深度学习项目中集成。它支持普通密集矩阵乘法,适用于常见的深度学习模型;也支持分组矩阵乘法,包括连续布局和掩码布局。
例如,在MoE 模型的训练前向传播或推理填充阶段,我们可以使用连续布局,将不同专家处理的输入数据拼接到一个连续的张量中。
而在推理解码阶段,当每个专家处理的输入数量未知时,我们可以使用掩码布局,通过掩码张量指示哪些部分是有效的输入。
(文:AIGC开放社区)