

今天是2025年02月26日,星期三,北京,天气晴。
我们继续来看看一些有趣的话题。
一个是关于Claude3.7的混合模型推理机制,昨天提出了一些疑问,思考了下,有些思路。
另一个是关于RAG,目前针对这块的一些论断很混乱,标题党很多,大家之前的原先概念也不统一,角度也不一,现在Deepresearch出来了,又在炒新概念,其实挺误导大众的,我们从基本逻辑出发,去看看这个问题,会有更清晰的认识。
专题化,体系化,会有更多深度思考。大家一起加油。
一、先看cluade的混合推理模式
昨天claude 3.7发布,有个点,大家比较关注,就是它的混合推理,我们看两个问题。
第一个问题,什么是混合推理模式。
参见https://aws.amazon.com/cn/blogs/aws/anthropics-claude-3-7-sonnet-the-first-hybrid-reasoning-model-is-now-available-in-amazon-bedrock/,这个工作
Claude3.7Sonnet采用了不同的模型思维方式。Claude3.7Sonnet不使用单独的模型(一个用于快速回答,另一个用于解决复杂问题),而是将推理作为核心功能集成到一个模型中。
有两种模式-标准模式和扩展思维模式-可在AmazonBedrock中切换。在标准模式下,Claude3.7Sonnet是Claude3.5Sonnet的改进版本。在扩展思维模式下,Claude3.7Sonnet需要更多时间详细分析问题、规划解决方案并考虑多个角度,然后再提供响应,从而进一步提高性能。您可以通过选择何时使用推理功能来控制速度和成本。扩展思维标记计入上下文窗口并作为输出标记计费。
可以从官网:https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking中找到使用说明。
使用方式:
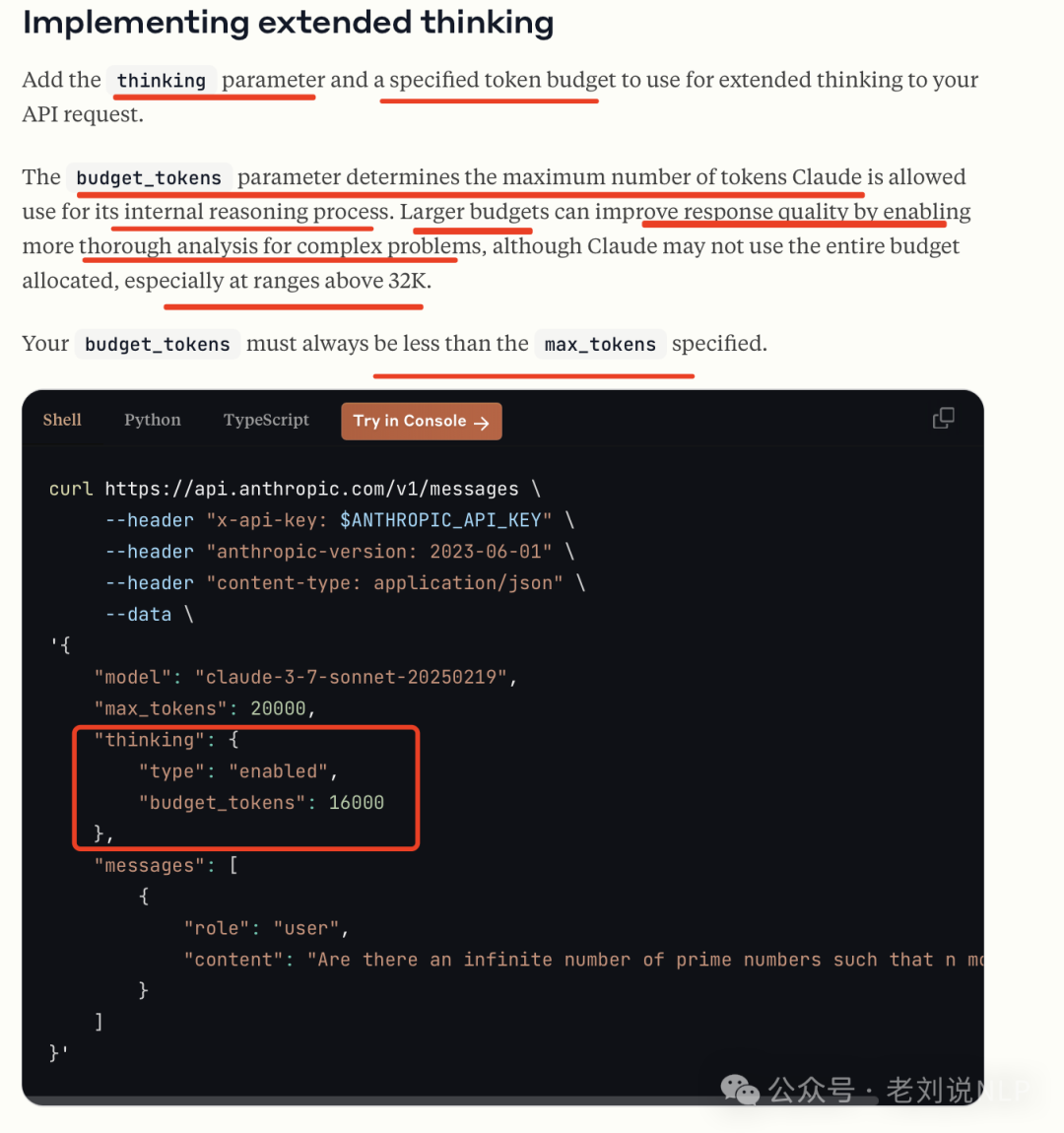
返回结果:

第二个问题,实现机制猜想?
所以,我们顺道来分析下这个机制,两个,一个是控制是否thinking,一个是thinking多久。
思路可以猜想下,可能使用了特殊的token,在提示词最后加上这个 token,模型就会开始推理模式回答,没有这个token,按旧有方式回答。然后工程上进行 API 包装。限制长度的部分应该也只是工程上的处理,程序会观察输出内容是否超过budget,超过了就强行插入终止思考。
那么,问题来了,这个其实还是依赖于大模型自身的能力,大家要想的是,假设这是微调或者强化出来的结果,这个是如何微调的,但claude这种,似乎验证了可以通过微调来实现这种效果,路线可行?
首先是是否触发思考的问题。
既然有开关,那么在训练数据侧就应该会有一个token,标记出是否要thinking。如果有限制token,那么是否构造训练数据时,也会将这类限制写入到input 当中,大家感兴趣的,可以去做做实验。如果使用特殊token做开关的话,这样训练时可以分开训练,模型可以同时拥有两种甚至多种能力。互相之间不会干扰。当然,如果将”<think>\n\n</think>”作为特殊token,或许也可以,但是这会产生一定的干扰。模型有几类事情,第一个是过于简单不必思考的,思考过程可以为空,R1 是这么做的;第二个是事情复杂,需要思考才能解决的,这类用 RL 激活<think>的思考复杂度;第三个是claude 目前做的,就是事情可能也是比较复杂,但是用户要求不思考,那么我依旧需要高质量的回答问题。
另一个是控制思考长度的问题
进一步想,如果Claude 3.7 采用的是s1 同样的方法,也就是不会插入”wait”启发继续思考,而是插入”</think>”来提前结束思考。关于s1,可可以看看:https://mp.weixin.qq.com/s/r8yoXRMWnoh_rUbHjzjEsQ,以及工作 S1《s1: Simple test-time scaling》(https://arxiv.org/pdf/2501.19393,https://github.com/simplescaling/s1),提到多种预算控制方案。一种是条件长度控制方案,依赖于在提示中告诉模型它应该生成多长时间。
例如可以执行多种粒度的控制,如token-条件控制,在提示中指定思考token的上限;步骤条件控制,指定思考步骤的上限,其中每个步骤大约为100个tokens;类-条件控制:编写两个通用提示,告诉模型思考一小段时间或很长一段时间。
二、再看RAG的一些误区
最近DeepResearch出来之后,大家提RAG提的少了,甚至都有些摒弃之嫌,一言以蔽之,就是什么火贴什么,然后架空历史,数典忘祖(注意这个成语)。
例如,最近看到一个文章《别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher》(https://mp.weixin.qq.com/s/gLyaLhWWDj1WoDSxEwpT6Q),纯标题党,带节奏,大家擦亮眼睛,看其写文章的目的是什么?
别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher?换个名字就能叫“新范式”了?早就有了,纯故事重提?这种表述是有很大误导性的。拥抱?需要成本,也不一定适用,无需号召拥抱。
先说一个基本事实,不要数典忘祖,现在无论是RAG,还是GraphRAG,还是AgenticRAG(也就是DeepResearch),都是RAG,都是为了LLM的输入上下文不充分,然后通过召回检索外部知识库的方式,来增强大模型生成的范式。
所以,这里有个统一理解,就是RAG到底是什么。有的人会分狭义RAG跟广义RAG,这些是在玩文字游戏。
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的技术范式。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力。
后续的方式,都是在这个框架下做的调优,所以别说什么DeepResearch要拥抱,GraphRAG不要搞了,任何技术都是螺旋式迭代上升优化的,提出之处都是为了解决特定的场景问题来做的,新的优化方案不是全干死了,它有他的长处,也有它的成本,有它的靶点,这些基本认识的糊涂,我们不要去犯。
例如,我们可以对比这几个的变化(来自于这篇文章的几个好图),其实更多的是在召回上做的优化,比如GraphRAG为了解决传统RAG之间chunk关联性差,召回率不高的问题,没法回答总结摘要类问题而提出。DeepResearch是为了解决上面两种方案是一次性的,无法让大模型自发的去反馈,去反思召回和生成结果,所以底层是个Agent,而RAG是Agent的一个特例,这些是一些局部优化操作。
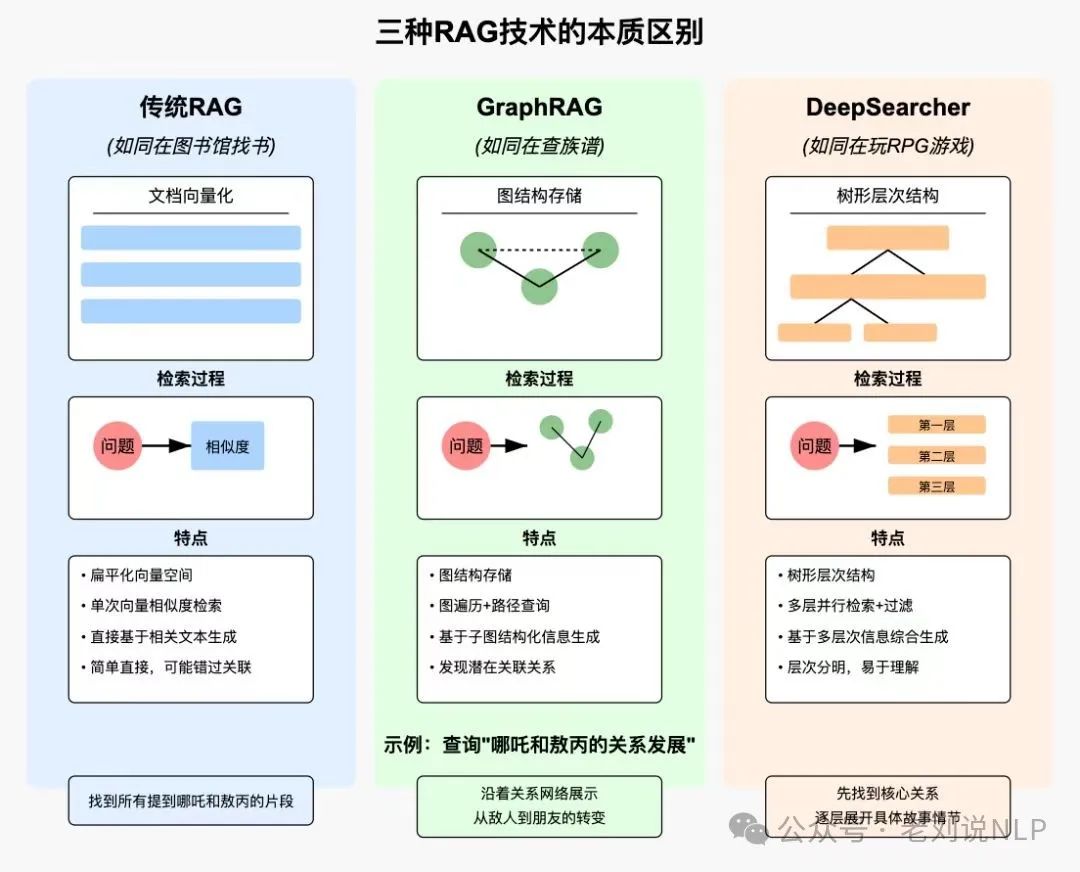
我们可以说的更直白点,对于DeepResearch,它和RAG没啥本质区别,和Graph RAG又没啥冲突,其本身就是一个do while 循环的RAG,加了reflection步骤,早就玩烂的模式,并且很慢,依赖于大模型的拆解跟反馈能力,成本很高,这块也不要去吹。
抛去刚才说的误导性的标题之外,这个工作中梳理的这张表倒不错,也供大家参考,很不错。
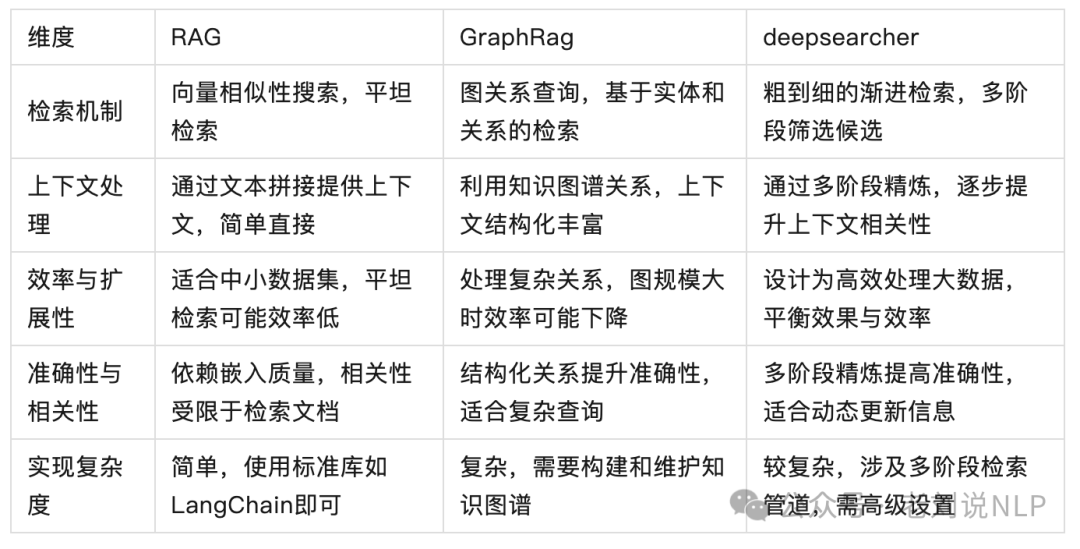
实际上,RAG是很有很大包容性的,因为它是一个范式,是个技术框架,可以往里面塞很多东西,也衍生出了很多子子孙孙,召回,生成,prompt优化等,这是RAG的魅力,范围足够大。
但是,大家追逐的,绝不是一个个新的技术本身,而是RAG这套,如何针对业务选择最好的变体去提升业务性能,没有最好的RAG方案,只有更合适的方案,每个方案都有自己的优势和劣势,大家做的是选择题,多选题,而不是客观题。
进一步的,说到DeepResearch,其加剧了对知识可信度的,知识整理的需求,并且对大模型的能力也提出了更多要求,以及对大家的容错性和场景忍耐性。因为这里面噪声太多了。
大家少扯一些概念,多回归到技术本身,会有更多的清晰的认知。一起加油
总结
本文主要讲了两个问题,一个是关于Claude3.7的混合模型推理机制,昨天提出了一些疑问,思考了下,有些思路。另一个是关于RAG,目前针对这块的一些论断很混乱,标题党很多,大家之前的原先概念也不统一,角度也不一,现在Deepresearch出来了,又在炒新概念,其实挺误导大众的,从基本逻辑出发,去看看这个问题,会有更清晰的认识。
参考文献
1、https://arxiv.org/pdf/2501.19393
(文:老刘说NLP)