


新智元报道
新智元报道
【新智元导读】Zep,一个为大模型智能体提供长期记忆的插件,能将智能体的记忆组织成情节,从这些情节中提取实体及其关系,并将它们存储在知识图谱中,从而让用户以低代码的方式为智能力构建长期记忆。
无论是ChatGPT还是Deepseek,随着大模型性能的提升,其能够处理的上下文也越来越长。但是,一旦超出上下文窗口的限制,大模型就需要重新开一个对话,如同「失忆」一般忘记之前交流的内容。
然而,站在用户的角度,智能体应该能够记住之前的所有对话,因此如何有效地管理和利用对话历史,就成为了提升AI智能体用户体验的关键。拥有长期记忆后,智能体能够回忆过去的对话,减少幻觉、延迟和成本。
将聊天记录作为文本导入,然后使用RAG来「恢复记忆」,是一种让大模型具有长期记忆的常用方式,但这往往需要额外的工程,构建RAG也存在无法忽视的时间差。
最近,一家名为Zep AI的初创公司推出了为智能体打造的记忆层,通过回忆聊天历史,可以自动生成摘要和其他相关信息,使AI助手能够在不影响用户聊天体验的情况下,异步地从过去的对话中提取相关上下文。
Zep AI成立于2023年,是一家位于湾区的YC系初创,主要愿景就是为AI构筑长期记忆。他们开发的核心插件已经在GitHub上开源,获得了3k+标星,同时也发表了详解技术原理的预印版论文。
仓库地址:https://github.com/getzep/zep
Zep:更适合工业界的MemGPT

论文链接:https://arxiv.org/pdf/2501.13956
当前使用RAG的方法主要集中在领域知识和静态语料库上,即添加到语料库的文档很少发生变化。
要使智能体的落地场景更加普遍,解决各种各样琐碎或高度复杂的问题,就需要访问大量的动态数据,比如与用户的交互、相关的业务数据以及世界知识。
Zep的开发者们认为,当前的RAG方法并不适合实现这一愿景;要想赋予智能体以动态、广泛的「记忆力」,需要让LLM驱动的智能体真正拥有存储部件。
事实上,这个想法并非Zep AI团队的原创。2023年,UC伯克利的研究者们发表的MemGPT就提出了这一点。

论文链接:https://arxiv.org/pdf/2310.08560
具体来看,Zep可视为AI智能体的基本内存,由具有时间感知能力的知识图谱引擎Graphiti所驱动,可以摄入并综合结构化业务数据和非结构化的消息数据,并动态更新知识图,从而表征一个复杂、不断发展的世界。
与其他知识图引擎相比,Graphiti的一个关键不同是具有时间提取和边失效过程,从而具备了管理动态信息更新的能力。

相比MemGPT,Zep更适用于工业界的生产场景,在内存检索机制的各方面性能上都有所提升,包括准确性、延迟和可扩展性。
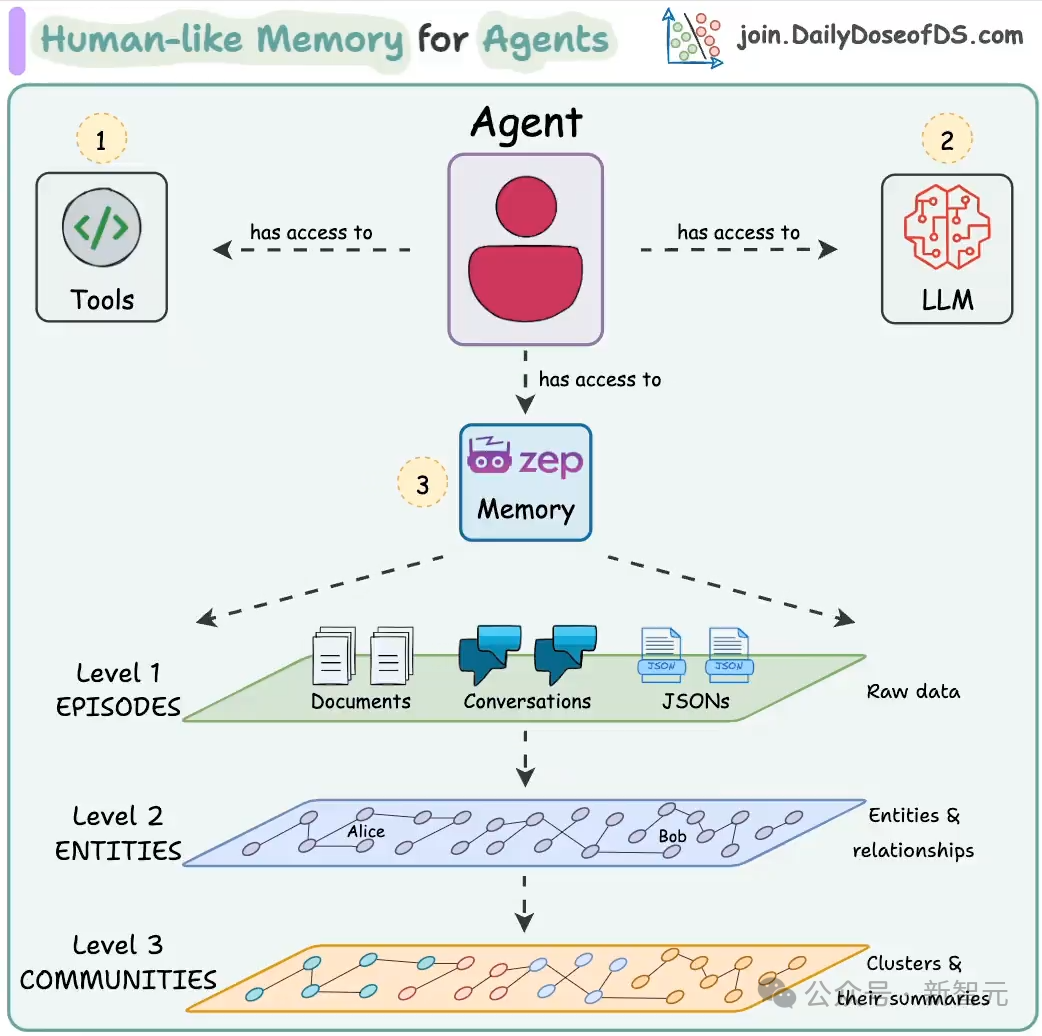
构建知识图谱
Zep的「记忆」由一个具有时间感知能力的动态知识图谱(temporally-aware dynamic knowledge graph)所驱动,可以表示为𝒢=(𝒩,ℰ,ϕ),其中𝒩为节点,ℰ表示边,而ϕ则是一个形式关联函数(formal incidence function),可表示为ℰ→𝒩×𝒩。
整个知识图谱共包含3层子图,从底层到顶层分别为:情节(episode)子图𝒢e,语义(semantic)子图𝒢s以及社区(community)子图𝒢c。
-
情节子图:以消息、文本或JSON的形式保留原始输入数据,其中的每个边将情节链接至下一层的相应语义实体
-
语义子图:基于情节子图提取实体及其关系
-
社区子图:每个节点表示一簇具有较强关联的实体,每个边将上一层的语义实体和社区相连接
这种分层表示与之前的AirGraph和GraphRAG有相近之处,更接近人类心智中的记忆模式,从而让使用Zep的LLM智能体发展出更加复杂和细微的存储结构。
内存检索
Zep的一大亮点就是功能强大、高效且高度可配置的的内存检索系统,包括3个核心步骤:
-
搜索(φ):根据输入文本S,识别出可能包含相关信息的候选节点和边,可以表示为φ:S→ℰsn×𝒩sn×𝒩cn
-
重排(ρ):对上一步的搜索结果重新排序,即ρ:φ(α),…→ℰsn×𝒩sn×𝒩cn
-
构造器(constructor χ):将相关的节点和边转换为文本形式的上下文,即χ:ℰsn×𝒩sn×𝒩cn→S
第一步骤的搜索中,除了RAG常用的余弦相似度搜索和全文搜索,Zep还加入了广度优先搜索,分别针对相似性的不同方面:全文搜索识别词语相似性,余弦搜索捕获语义相似性,而广度优先搜索揭示了上下文相似性,从而最大程度地从图谱中挖掘最佳语境。
实验评估
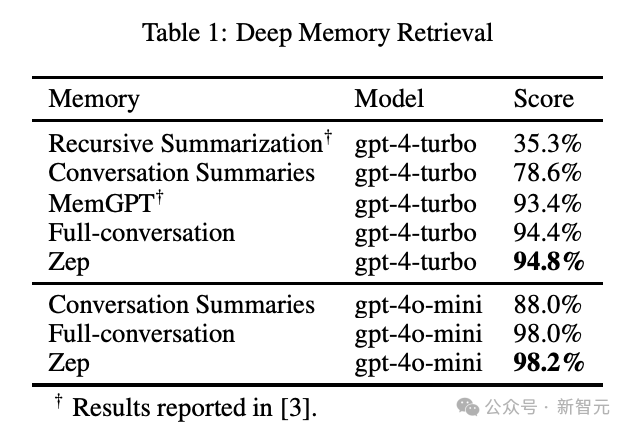
论文采用了两种针对LLM内存的基准测试,分别是DMR任务(Deep Memory Retrieval)和LongMemEval基准,相关的实验代码已经公布在GitHub仓库中。
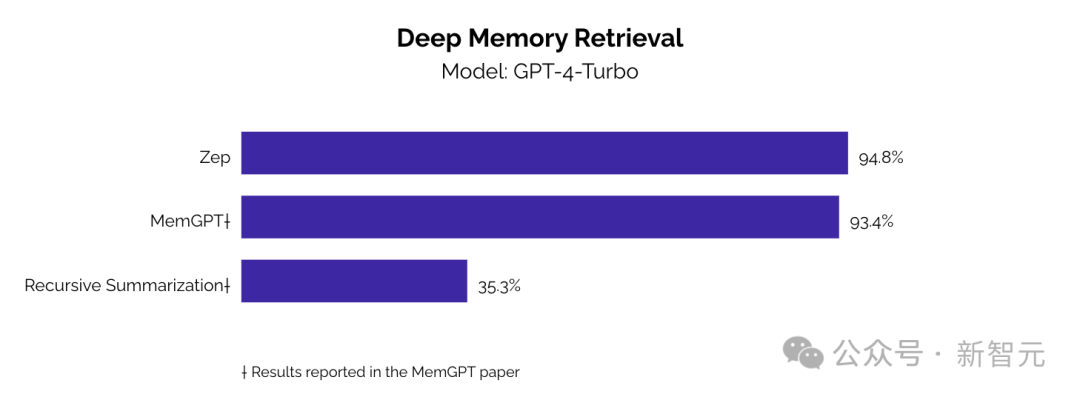
DMR的基线除了MemGPT外,还有两种常见的LLM内存方法:完整对话上下文(full-conversation context)和会话摘要(session summary)。
从下图和表格中可以看出,无论使用GPT-4-Turbo还是GPT-4o-mini模型,Zep都可以超过基线方法,但DMR基准的设计存在一个显著缺陷:无法评估对复杂记忆内容的理解,完整上下文搜索所得到的高分就能从侧面证明这一点。
LongMemEval基准的弥补了DMR的这一缺陷,加入了更长、更连贯的对话内容以及更多样化的评估问题,从而更好地反映真实场景的需求,实验结果如下表所示。
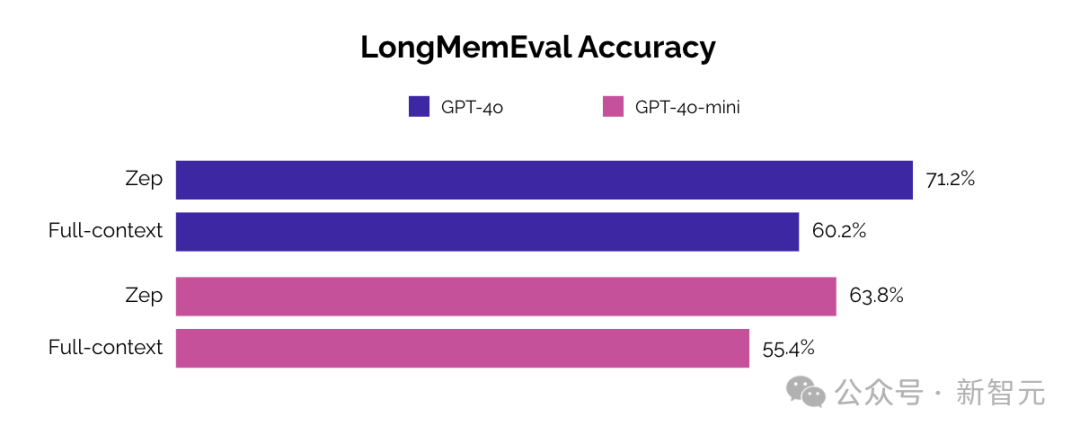

可以看到,相比基线方法,Zep不仅提升了结果的精度,而且将响应时间减少了约90%,相比其他LLM供应商也有约80%的提升。
(文:新智元)