新智元报道
新智元报道
【新智元导读】最近,英伟达开源了首个在Blackwell架构上优化的DeepSeek-R1,实现了推理速度提升25倍,和每token成本降低20倍的惊人成果。同时,DeepSeek连续开源多个英伟达GPU优化项目,共同探索模型性能极限。
当FP4的魔法与Blackwell的强大算力相遇,会碰撞出怎样的火花?
答案是:推理性能暴涨25倍,成本狂降20倍!
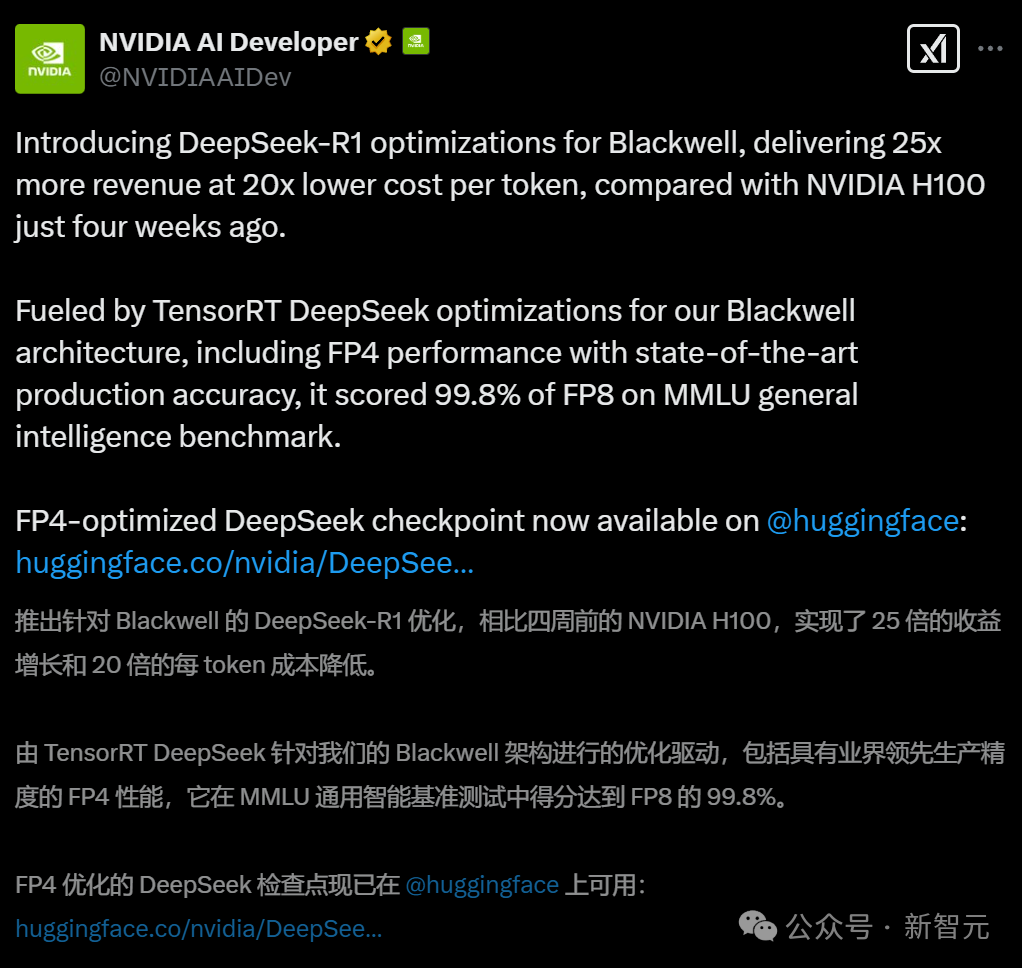
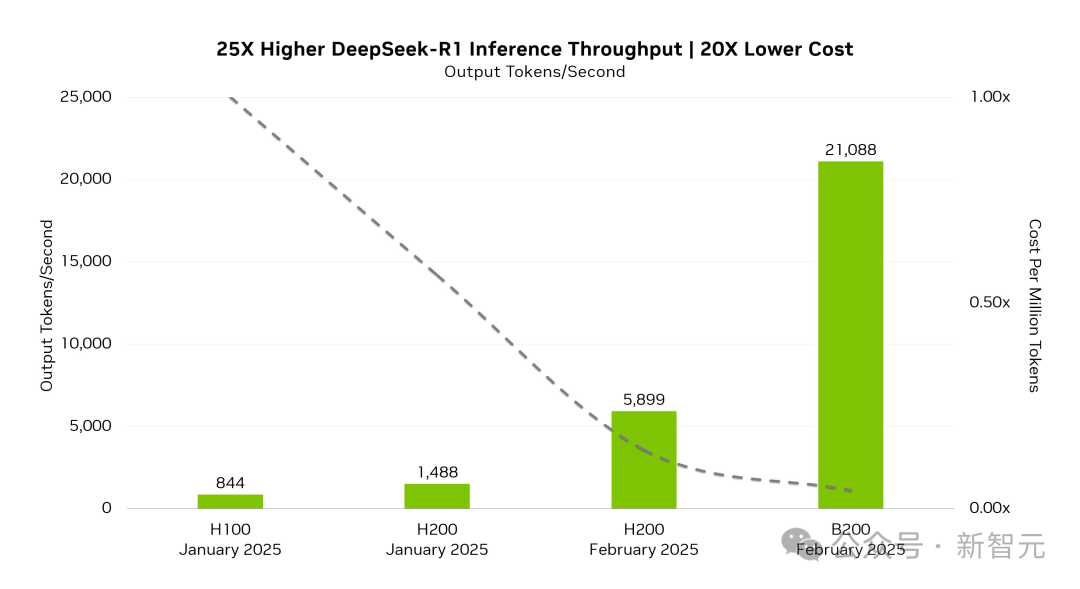
在新模型的加持下,B200实现了高达21,088 token每秒的的推理吞吐量,相比于H100的844 token每秒,提升了25倍。
与此同时,每token的成本也实现了20倍的降低。
通过在Blackwell架构上应用TensorRT DeepSeek优化,英伟达让具有FP4生产级精度的模型,在MMLU通用智能基准测试中达到了FP8模型性能的99.8%。
DeepSeek-R1首次基于Blackwell GPU优化
模型地址:https://huggingface.co/nvidia/DeepSeek-R1-FP4
后训练量化
模型将Transformer模块内的线性算子的权重和激活量化到了FP4,适用于TensorRT-LLM推理。
这种优化将每个参数从8位减少到4位,从而让磁盘空间和GPU显存的需求减少了约1.6倍。
使用TensorRT-LLM部署
要使用TensorRT-LLM LLM API部署量化后的FP4权重文件,并为给定的提示生成文本响应,请参照以下示例代码:
硬件要求:需要支持TensorRT-LLM的英伟达GPU(如B200),并且需要8个GPU来实现tensor_parallel_size=8的张量并行。
性能优化:代码利用FP4量化、TensorRT引擎和并行计算,旨在实现高效、低成本的推理,适合生产环境或高吞吐量应用。
from tensorrt_llm import SamplingParamsfrom tensorrt_llm._torch import LLMdef main():prompts = ["Hello, my name is","The president of the United States is","The capital of France is","The future of AI is",]sampling_params = SamplingParams(max_tokens=32)llm = LLM(model="nvidia/DeepSeek-R1-FP4", tensor_parallel_size=8, enable_attention_dp=True)outputs = llm.generate(prompts, sampling_params)# Print the outputs.for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")# The entry point of the program need to be protected for spawning processes.if __name__ == '__main__':main()
对于此次优化的成果,网友表示惊叹。
「FP4魔法让AI未来依然敏锐!」网友Isha评论道。
网友algorusty则声称,有了这次的优化后,美国供应商能够以每百万token 0.25美元的价格提供R1。
「还会有利润。」
网友Phil则将这次的优化与DeepSeek本周的开源5连发结合了起来。
「这展示了硬件和开源模型结合的可能性。」他表示。
DeepSeek全面开源
如今DeepSeek持续5天的「开源周」已经进行到了第3天。 周一,他们开源了FlashMLA。这是DeepSeek专为英伟达Hopper GPU打造的高效MLA解码内核,特别针对变长序列进行了优化,目前已正式投产使用。
周二开源了DeepEP,这是一个专为混合专家系统(MoE)和专家并行(EP)设计的通信库。
周三开源的是DeepGEMM。这是一个支持稠密和MoE模型的FP8 GEMM(通用矩阵乘法)计算库,可为V3/R1的训练和推理提供强大支持。
总的来说,不管是英伟达开源的DeepSeek-R1-FP4,还是DeepSeek开源的三个仓库,都是通过对英伟达GPU和集群的优化,来推动AI模型的高效计算和部署。
(文:新智元)