跳至内容
最近肝到爆,一直以为昨天是账号建立两周年。然后回溯了下历史,才发现原来是前天。。。
从FlashMLA、DeepEP再到DeepGEMM,开源的世界里真就闯进来一位大神。
老黄辛辛苦苦多年建起来的商业护城河上,DeepSeek居然明目张胆地开始架桥了。。。
但是说实话,DeepSeek的所有开源的项目,全部都是基于英伟达的生态做的,虽然大家戏称说DeepSeek比老黄更懂显卡,但是这些项目开源出来,我咋感觉大家跟英伟达绑定的就更深了呢。。。
他们又一口气开源了俩东西,还有一个性能分析数据库。
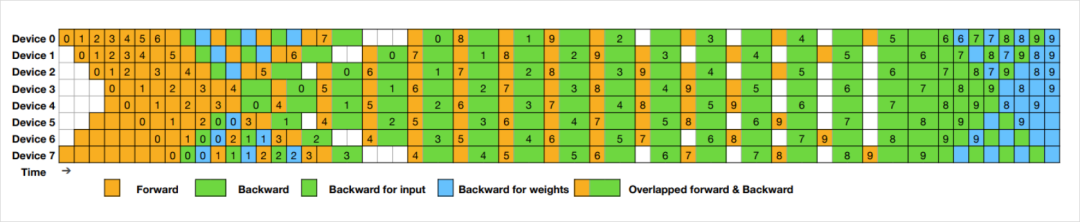
一个能把硬件资源,再度榨干到极致的双头流水线DualPipe。
还有一个能平衡所有任务,把效率拉爆的EP调度器EPLB。
https://github.com/deepseek-ai/DualPipe?tab=readme-ov-file
https://github.com/deepseek-ai/eplb
说DeepSeek牛逼已经说麻了,只能跪着给他们鼓掌了。。
这玩意儿是一种贼新的双向并行算法,在DeepSeek v3的论文里面其实已经出现过了。
我用一个做面包的例子给大家解释一下这玩意到底干啥用。
比如说你家里是开面包店的,叫X利来,每天都要卖好吃的面包给大家吃大家也很喜欢你。
你家里呢,有一条面包生产线,就像工厂里那种流水线一样。
面包从揉面、发酵、整形、烘烤到包装,需要很多道工序,而且每道工序都要排队依次进行。
如果是那种单向的传统的流水线就会有一个非常der的问题:比如说一个人先把面揉好然后送给下一个人发酵,等发酵好了再送给下一个人烤,烤好了再送给下一个人包装。。。
这就导致每个人在等待之前那道工序结束的时候,可能都要等上一会儿。如果有几道工序比较耗时,那么后边的人就只能干等,没法同时干点别的,这就拖慢了整体产量。
所以为了提高效率,你就就会想,能不能让前面的操作和后面的操作同时进行?比如这个人一边揉面,另一边又有人可以烤前一批次的面包,不至于让所有人都卡在同一个步骤上面。
这其实就类似最基本的流水线并行思想,也是现在很多工厂的流水线方式,简称,工业化。
可是,这样也会产生一种所谓的“气泡”,就比方说等你揉面的人实在太多了,而烘烤那边一时没得可烤,或者反过来,烘烤还没结束,就阻塞了包装,一来一回会浪费一些时间空档。
这个浪费的空档,形象点说就像流水线上两个工序之间充了空气的“气泡”,它还是没有完美的提升效率,会让人有摸鱼的“气泡”空间。
普通的流水线并行,还会遇到一个问题,就是你的搬运。
比如说你家工厂太大,揉面机在一楼,烤炉在八楼,中间还没电梯。有时候揉面好了要送到烤炉,这个来回搬运也得干死个人,但是又不得不做。
所以,你还在加上搬运的工序,也就是在搬运的同时,炉子、揉面机啥的也都不能闲着。
你现在可以歇一会,来考虑一下他们的计算量,是不是非常的恐怖。
但是相比于大模型的计算,面包厂这个case的复杂度,就是小巫见大巫了。
而DeepSeek掏出来的DualPipe,就是解决这个问题的,就是如果带入我们自己的话,你就可以把它想象成一个非常黑心但又非常聪明的资本家。。。
DualPipe这东西,中文可以叫“双管并行”或“双向流水线”,它直接把整套的逻辑和计算设计,都给你做完了,找到了最优解,你不用想着每个工序怎么安排了,你直接用就完了。
所以,DualPipe到底能把干活的人发呆的时间,降到什么程度?
主要有几个数据:流水线气泡(浪费的时间)和参数(用的资源)、激活(额外用的内存)。
能看得出来,效率最高,浪费时间最少。但用了更多资源(参数翻倍,空间多占一点)。
可能是为了适合需要超快速度的大任务,代价就是资源稍微多点。
我还记得老黄说自己是全世界最好的CEO。确实,一路给市值干到顶峰的人物。
但现在,DeepSeek要冲上山,走一条之前无人问津的羊肠小道,拔下那把勇者的宝剑了。
在开发者那一栏,还有个非常好玩的是,真大佬亲自下场了。。。
再说今天DeepSeek给的第二份大礼:EPLB。
Expert Parallelism Load Balancer,翻译过来可以叫“专家并行负载均衡器”,你也可以说是EP调度器。
会涉及到不少项目:布置会场、教室卫生、文艺汇演彩排、音响灯光调试、食堂伙食安排、礼仪接待……
各个项目可能都由不同的老师或同学去负责。要是这些项目的难度或工作量不一样,有些老师就会被忙得不可开交,而另一些可能比较清闲,这就不公平,也不高效。
那么这个所谓的“专家并行”就意味着,每个老师或同学都可以看作某个“专家”,专门负责一部分工作。
比如语文老师可能负责写文案,音乐老师负责排练合唱等等。
可是总会有一些专家特别抢手,比如PPT做的好的老师,那你肯定懂的,这绝壁是最抢手的专家。
于是这个专家就累死累活。要是能再安排两个PPT专家,这样就可以分担一部分压力,这个就叫“冗余专家”。
EPLB做的事情就是,根据统计到的每个专家最近一段时间的工作量,推测哪几个专家可能会特别繁忙,然后赶紧给它们“复制”一下,也就是直接给PPT大拿来几个复制人。
这样当需要调用这个专家时,一部分请求可以排到复制人那里执行,大家就不用都挤在同一个人那里里,工作可以被分散出去。
然后还得考虑你的学校有不同的教学楼对吧,教学楼之间的距离比较远(类似节点之间用IB连接)。
同一个教学楼里的人肯定近的多(类似节点内用NVLink),所以让同楼里老师之间的合作肯定比跨楼去合作更方便。
EPLB就希望那些经常一起合作的“专家组”能放在同一个楼里,避免来回跑的浪费。比如有几个老师最常交流合作,那就得把他们都排在一个楼层,就能减少在楼间奔跑。
相当于在DeepSeek里就可以减少节点间的数据通信。
所以,总结一下,学校庆典马上开始了,EPLB会先数一数每个专家上个庆典忙了多少,比如看历史统计,某个专家被调用了100次,另一个才10次,差距很大,就说明前者更忙,需要复制,直接就火速复制10个数字人。
然后它要决定这些复制的专家该放到哪张GPU卡上。如果有两张卡特别空闲,就把繁忙专家的复制人放到这两张卡上,以便一旦有请求过来,不管发到哪张卡都能快速处理。
它也会尽量把同一组的专家都放到同一个节点(同一个楼),减少跨节点的大量通信。
同样,DeepSeek并不只为了开源而开源,还给出来详细的接口和例子。
下面这串代码,就是这群聪明人,怎么安排工人干活的。
下面这个图就是他们,在专家少的情况下,做调度的策略(分层负载均衡策略)。
早上这两发完以后,看到这,一堆在技术中摸排滚打的群友坐不住了。。。
用好奇心解开AGI的奥秘,用长期主义回答本质问题。
(文:数字生命卡兹克)