
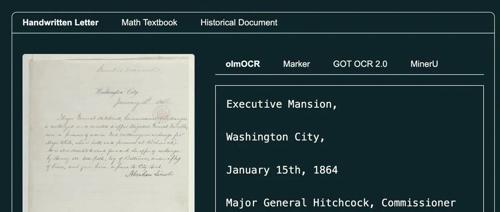
在 PDF 文档解析 领域,准确提取文本、表格、公式等结构化数据一直是一个难题。
许多 OCR 工具在遇到复杂布局、手写内容或数学公式时,往往会出现信息丢失、顺序错乱甚至误识别的情况。
就在昨天由 Ai2 最新推出的 olmOCR 引发关注,体验后效果拉满,获得很多大佬的点赞转发。
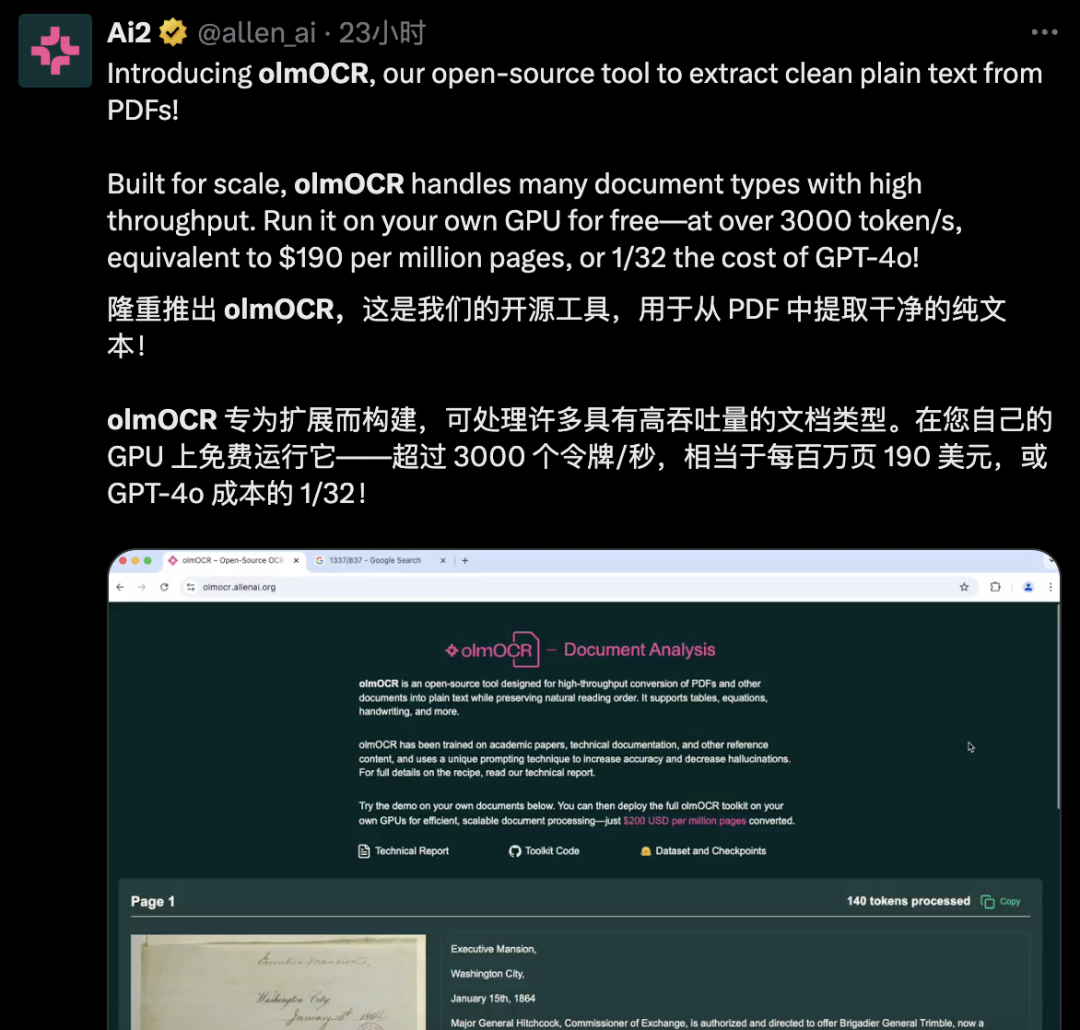
它通过 Qwen2-VL-7B-Instruct(阿里多模态模型) 进行训练,专门针对 PDF 和文档图像 提取 干净、结构化的纯文本,并以 Markdown 格式输出,极大地提升了文本解析的 精准度、可读性和可用性。
它特别擅长处理复杂布局,如表格、方程式和手写内容,适合需要高精度文本提取的场景。
背景问题
语言模型(LMs)需要高质量的纯文本数据才能表现良好,但 PDF 等电子文档格式的设计目标是页面渲染,而非逻辑文本结构。这导致以下挑战:
-
• 难以准确提取文档中的标题、段落、表格和方程式。 -
• 复杂布局(如多栏、多页表格)可能导致阅读顺序混乱。 -
• 传统 OCR 工具在处理手写内容和方程式时表现不佳。
olmOCR 旨在解决这些问题,提供高效、准确的文本提取方案。
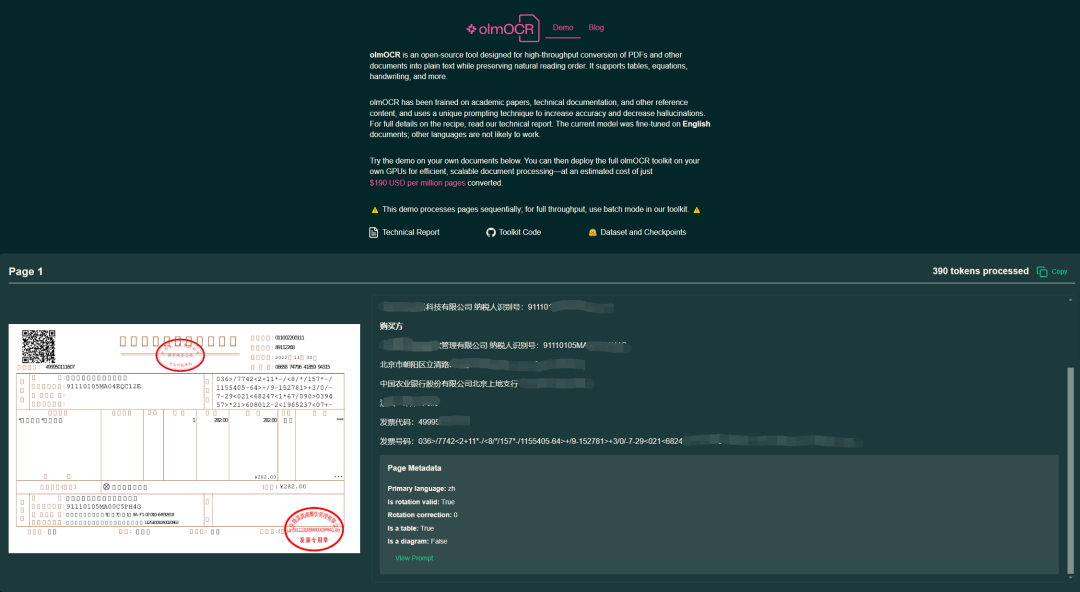
(实测图源:@karminski-牙医)
olmOCR 的核心优势
1、高效精准的 PDF 文本提取
通过在 25 万页多样化 PDF 数据集上微调训练,能够应对 复杂布局(如 多栏排版)、嵌入表格、数学公式 和 手写文本 等挑战。
结合 “文档锚定” (document anchoring) 技术,提高 文本解析质量,在 标题、段落、表格、方程式 等元素提取方面表现出色。
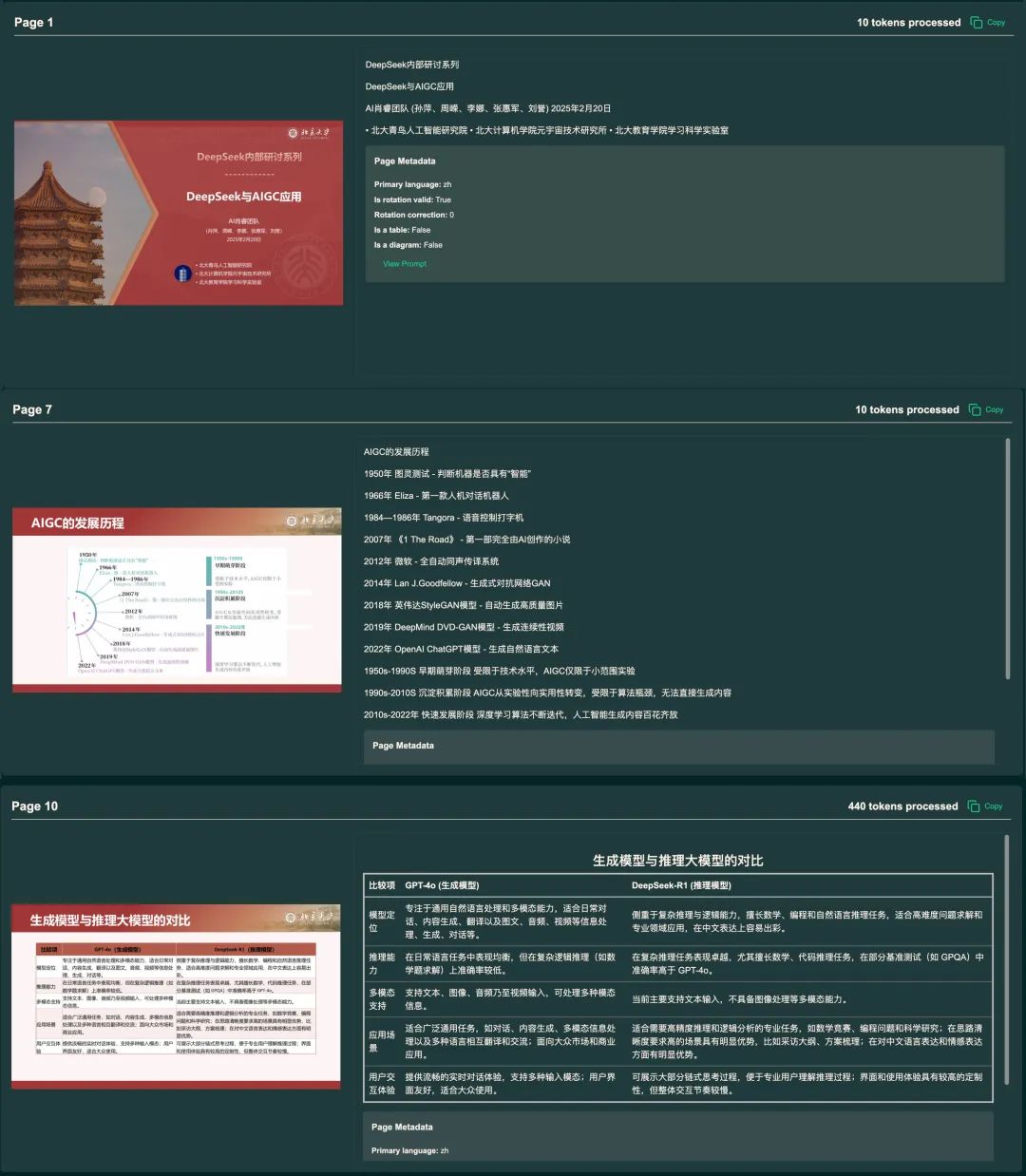
2、Markdown 格式输出
olmOCR 会生成易于解析的 Markdown 格式文本,能准确处理方程式、表格和手写内容。这种格式便于后续使用,如与语言模型集成或文档编辑。
3、低成本效益
处理 100 万页 PDF 的成本约为 190 美元,相比使用 GPT-4o API 的批处理模式,成本仅为其 1/32。
这使得 olmOCR 成为预算有限的用户的理想选择,特别是在处理学术论文、法律文档等大批量 PDF 时,性价比极高。
4、完全开源
olmOCR 完全开源,并发布了 模型权重、训练数据集、代码,可自由部署使用。支持 多 GPU 扩展,可以在本地或云端进行高效批量处理。
快速使用
olmOCR 的使用也非常方便,提供两种方式:在线Web 和 本地部署。
① 在线Web
可以直接访问官方上线的网页端,可直接体验,上传文档进行解析提取。
体验地址:https://olmocr.allenai.org
② 本地部署
olmOCR 对硬件要求还是有的,需要有英伟达显卡支持。
如果是 Linux 环境需要安装一下依赖:
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools然后就是需要创建一个Python虚拟环境,并克隆项目&安装依赖
conda create -n olmocr python=3.11
conda activate olmocr
git clone https://github.com/allenai/olmocr.git
cd olmocr
pip install -e .如果需要在GPU上运行推理,还要使用flashinfer安装sglang。
pip install sgl-kernel==0.0.3.post1 --force-reinstall --no-deps
pip install "sglang[all]==0.4.2" --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/本地使用示例,比如转换单个PDF:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf结果将存储为JSON格式至./localworkspace。
将结果与原始 PDF 并排查看命令:
python -m olmocr.viewer.dolmaviewer localworkspace/results/output_*.jsonl性能评估
Ai2 团队对 olmOCR 进行了详细的对比测试,评估其与 Marker、MinerU、GOT-OCR 2.0 等主流 PDF 解析工具的性能差距。
Elo 评分:1800+(显著优于竞品)
在实际用户评估中,olmOCR 的优选比例:
-
• 对比 Marker:61.3% -
• 对比 GOT-OCR 2.0:58.6% -
• 对比 MinerU:71.4%(表现最优)
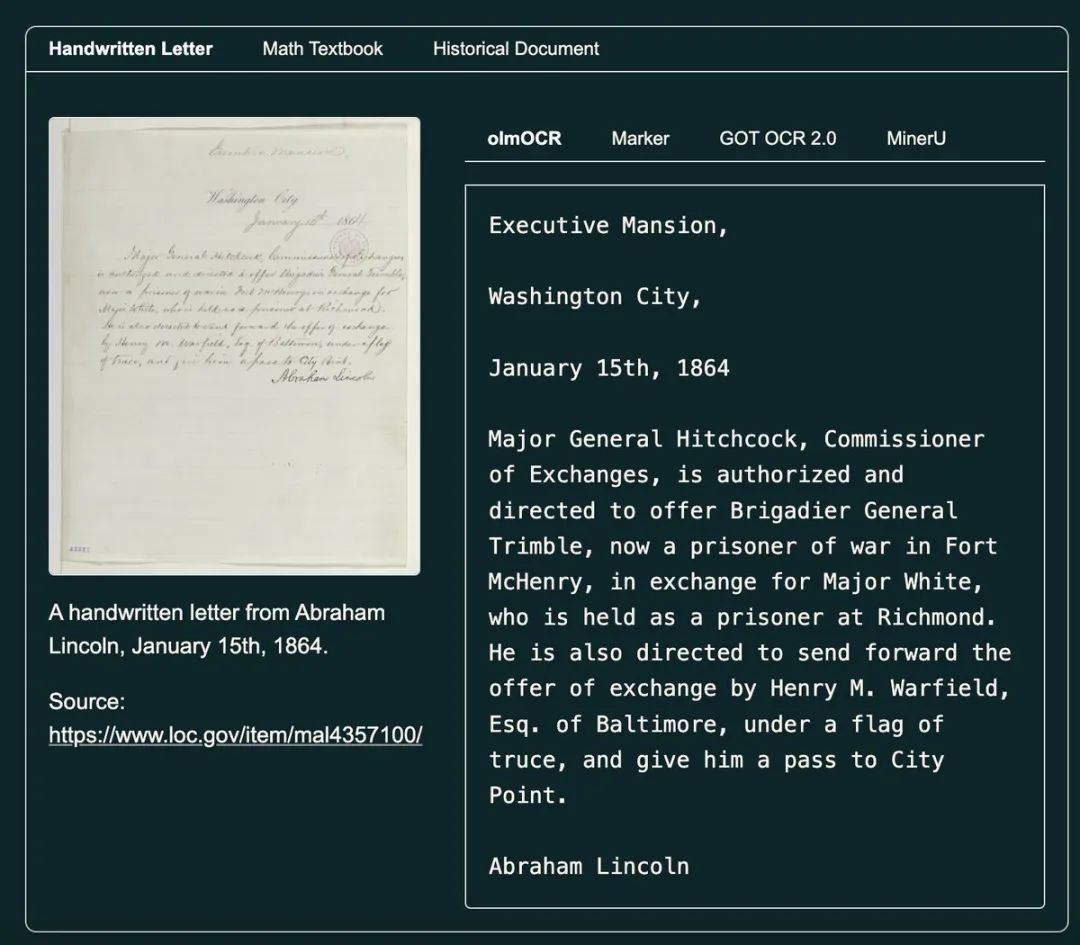
从以上数据可以看出,olmOCR 在各项任务中均优于现有主流工具,尤其在 表格解析、公式识别、多栏布局处理 等方面表现突出。
写在最后
olmOCR 作为 Ai2 最新推出的 高效 PDF 解析工具,不仅在 准确率、解析能力、成本效益 等方面全面超越现有工具,还开源了现有模型及代码,完全自主。
特别适合需要处理复杂文档的用户,其高性能、低成本和开源特性使其成为研究者和开发者的首选。无论是学术研究还是商业应用,也都能提供高效、可靠的解决方案。
GitHub 项目地址:https://github.com/allenai/olmocr

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)