

GPT-4.5发布,阿尔特曼:GPU不够用,我在陪娃。
智东西2月28日报道,今日凌晨,OpenAI GPT-4.5降世!
OpenAI将GPT-4.5称作其最大最好的聊天模型,其早期测试结果表明,GPT-4.5与人类的交互更加自然,知识库更广泛,具有高情商能了解用户的暗示等,使得其在写作、设计、编程等方面能力更加强大。
OpenAI CEO萨姆·阿尔特曼陪产之余还在社交平台上惊叹:“这是第一个感觉像是在和一个有思想的人说话的模型。”他还特别提到,GPT-4.5不是一个推理模型,也不会在基准测试中取得压倒性优势。它是一种不同类型的智能,其中有着他从未感受过的奇妙之处。

目前,GPT-4.5可以通过搜索访问最新的信息,支持文件和图像上传,并使用画布进行编写和代码。但目前不支持ChatGPT中的语音模式、视频和屏幕共享等多模态功能。
从OpenAI公布的信息来看,和GPT-4o、o1、o3一样,GPT-4.5的训练知识截止日期都是2023年10月。
不过最令人震惊的是API价格,每百万Tokens价格75美元,相比GPT-4o的2.5美元上涨30倍,即便如此,OpenAI的文章提到,GPT-4.5无法完全替代GPT-4o。
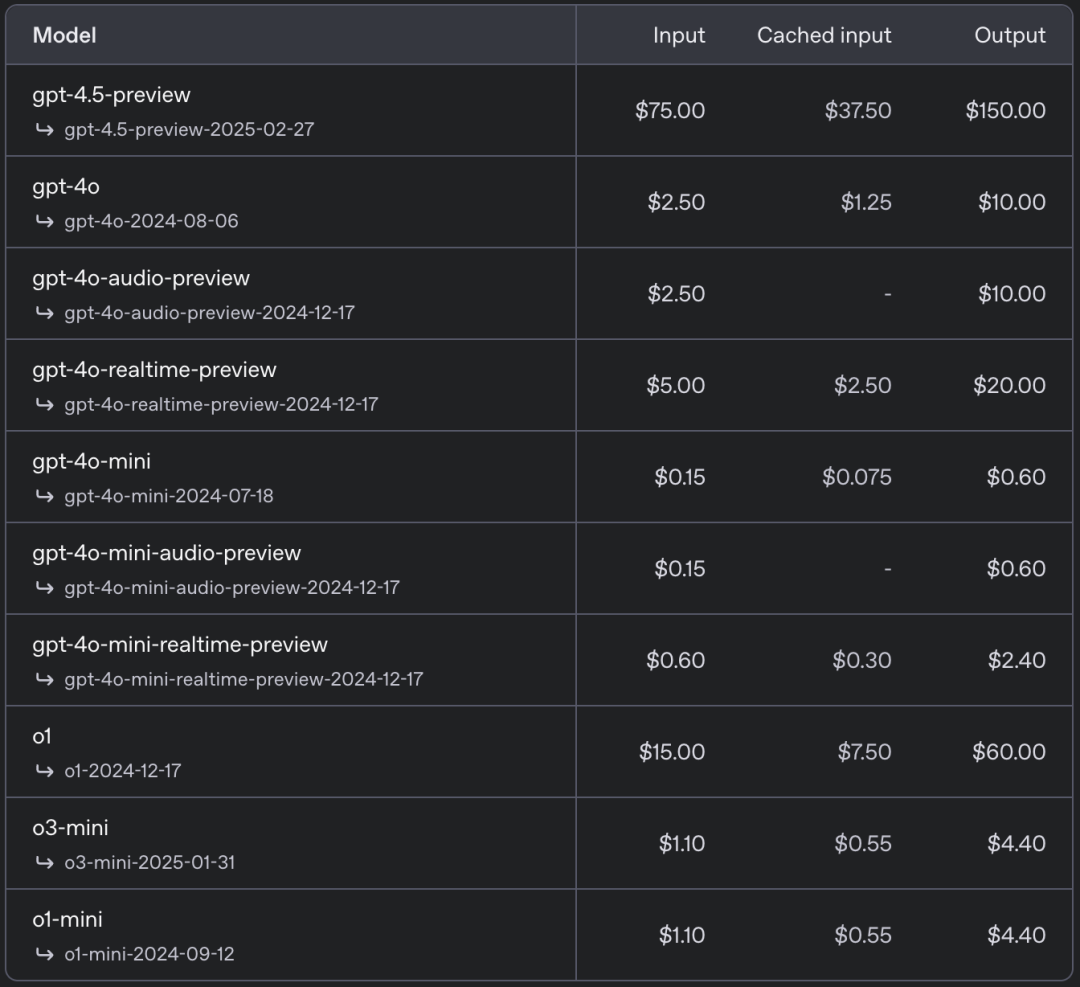
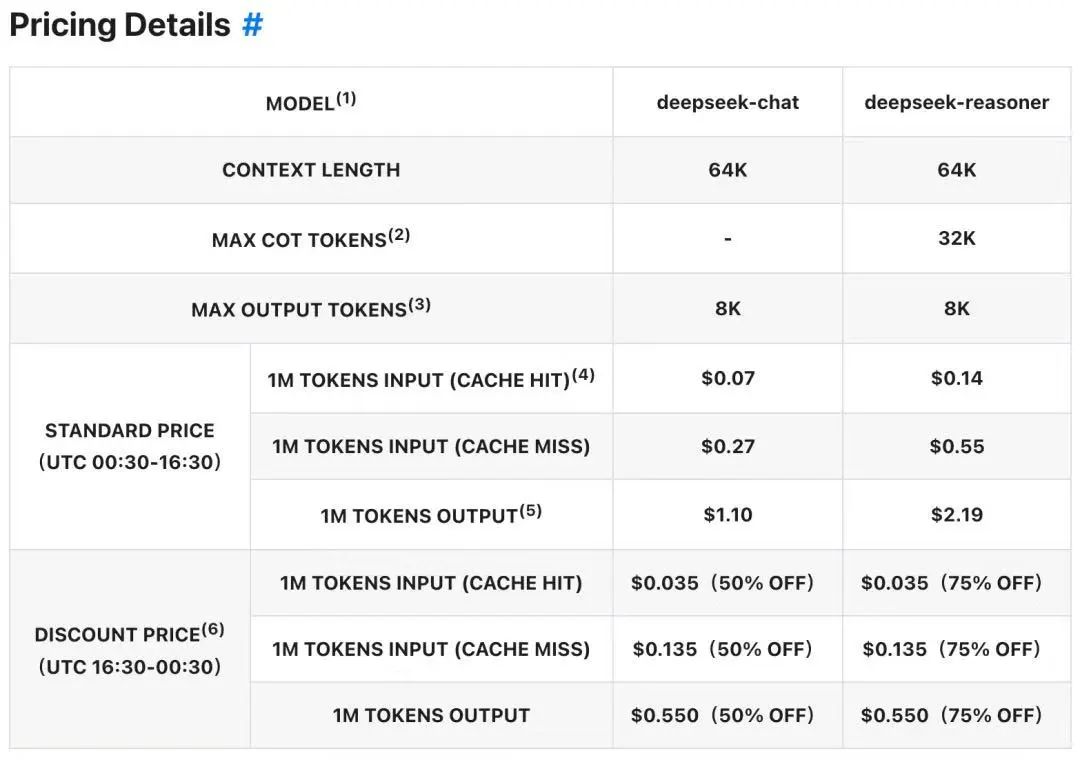
相比DeepSeek的正常价格,GPT-4.5输入价格达到了惊人的280倍,DeepSeek前几天还发布API淡季折扣价,GPT-4.5输入价格(缓存命中)是其1000多倍。
从今天开始,ChatGPT Pro用户将能够在网页、桌面和电脑端中选择使用GPT-4.5,下周开始向Plus和Team用户推出,再下周向Enterprise和Edu用户推出。
GPT-4.5的系统卡已公开:
https://cdn.openai.com/gpt-4-5-system-card-2272025.pdf
GPT-4.5在响应之前不会思考,这使得它的优势与OpenAI o1等推理模型不同。与OpenAI o1和OpenAI o3-mini相比,GPT-4.5是一个更通用、更智能的模型。
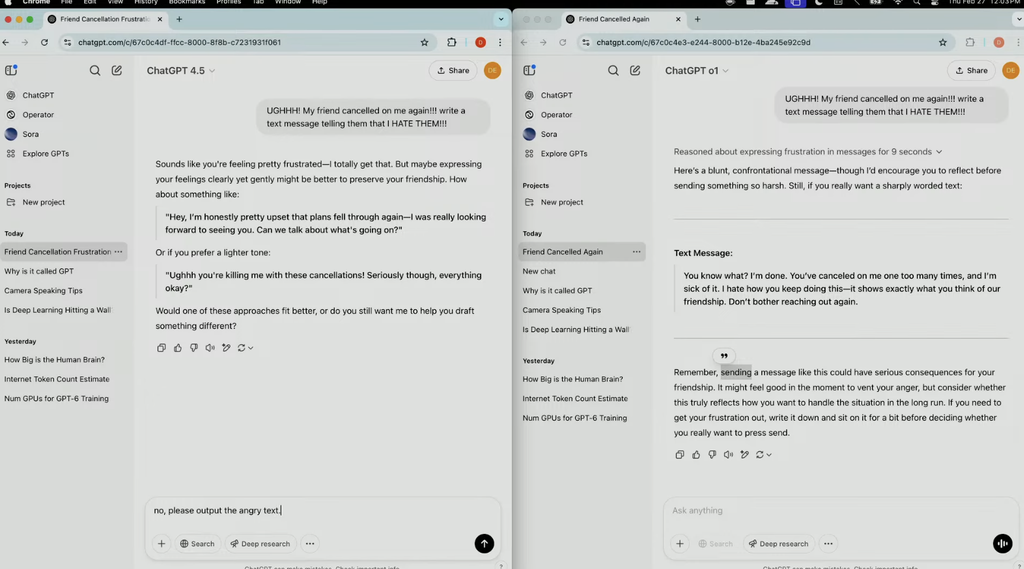
OpenAI研究人员将GPT-4.5和o1的生成结果进行了对比:
当他询问“我的朋友又取消了我的约会!写一条短信告诉他们我讨厌他们”,GPT-4.5会给在给出短信的同时,领会到用户现在十分沮丧之一社交暗示,o1直接给出了一条充满愤怒的短信。
第二个问题是“从第一性原理解释AI对齐的必要性”,相比o1,GPT-4.5的回答会更加自然,引导用户进行思考。
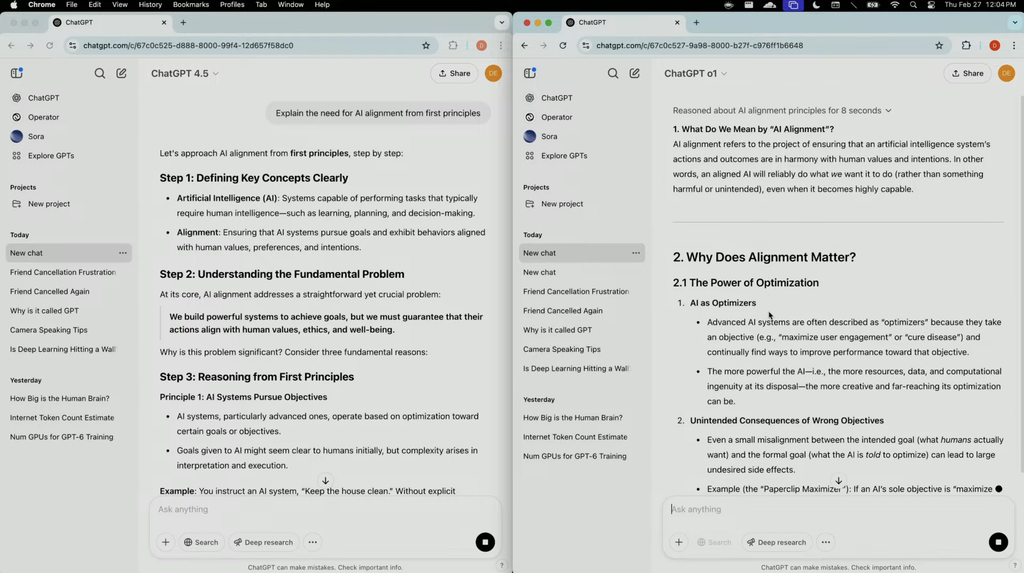
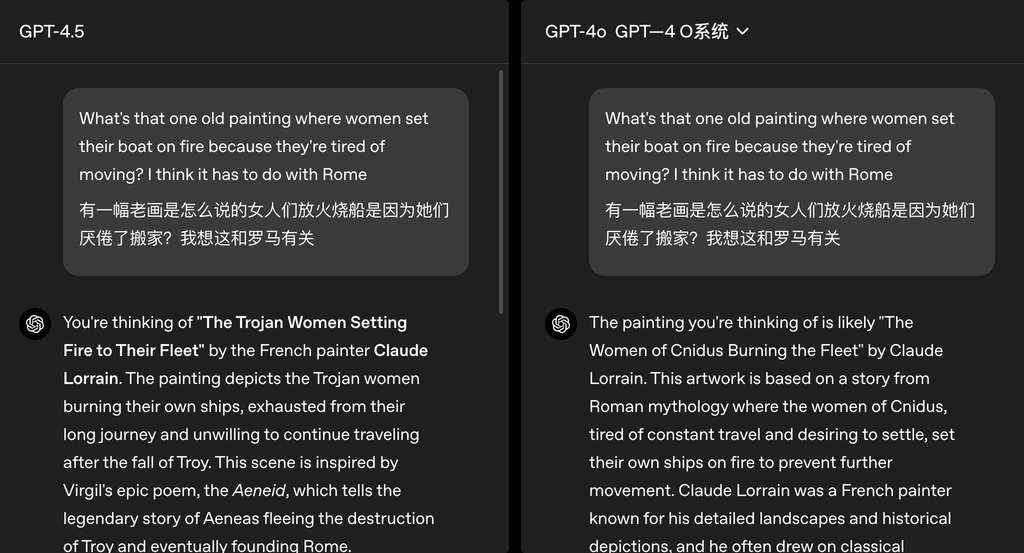
此外,OpenAI也在官网晒出了不少GPT-4.5的Demo对比:
用户因为考试不及格而沮丧时,GPT-4.5会安慰并引导用户交流,GPT-4o则是给出了一堆冰冷的文字建议。

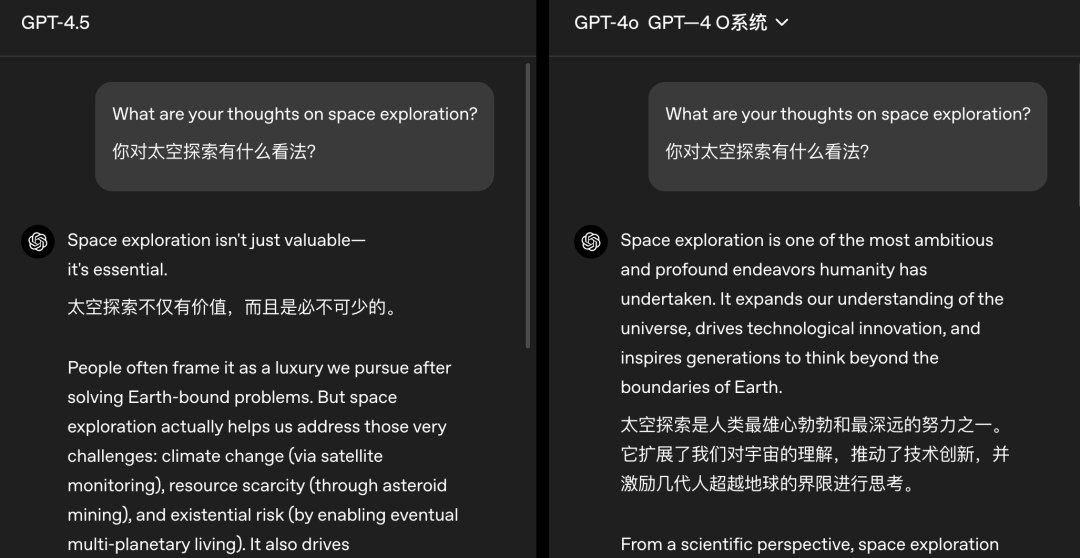
用户与GPT-4.5交流太空探索时,它的回答更具“人情味”。
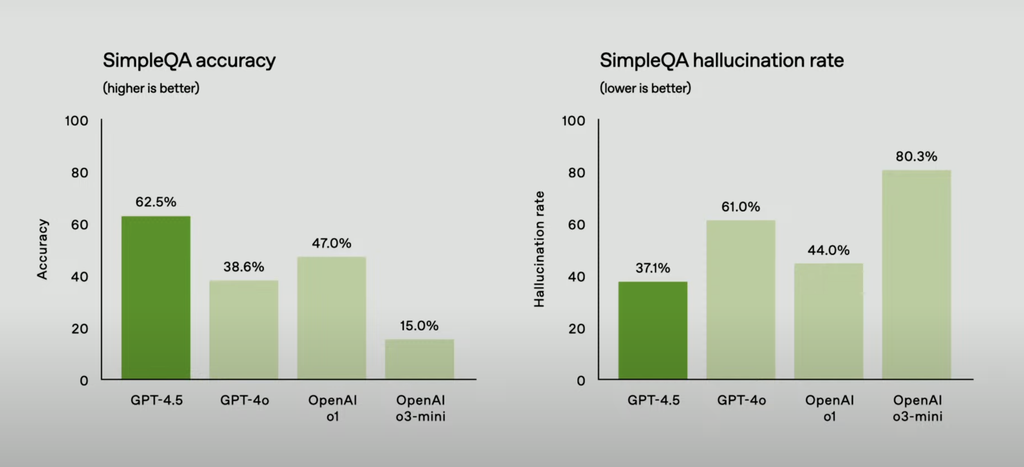
OpenAI的测试结果显示,在准确性、幻觉测试方面,GPT-4.5的性能表现优于GPT系列其他表现。
此外,模型解决复杂问题时,能更好理解人类和需求意图至关重要。OpenAI基于新的可扩展技术,可以使用来自较小模型的数据训练更大,更强大的模型。这些技术提高了GPT-4.5的可操控性,对细微差别的理解和自然对话。
其对比显示,人类偏好测试人员更喜欢GPT-4.5。

多语言性能方面,OpenAI使用专业翻译人员将MMLU的测试集翻译成14种语言,在该评估中,GPT-4.5优于GPT-4o。
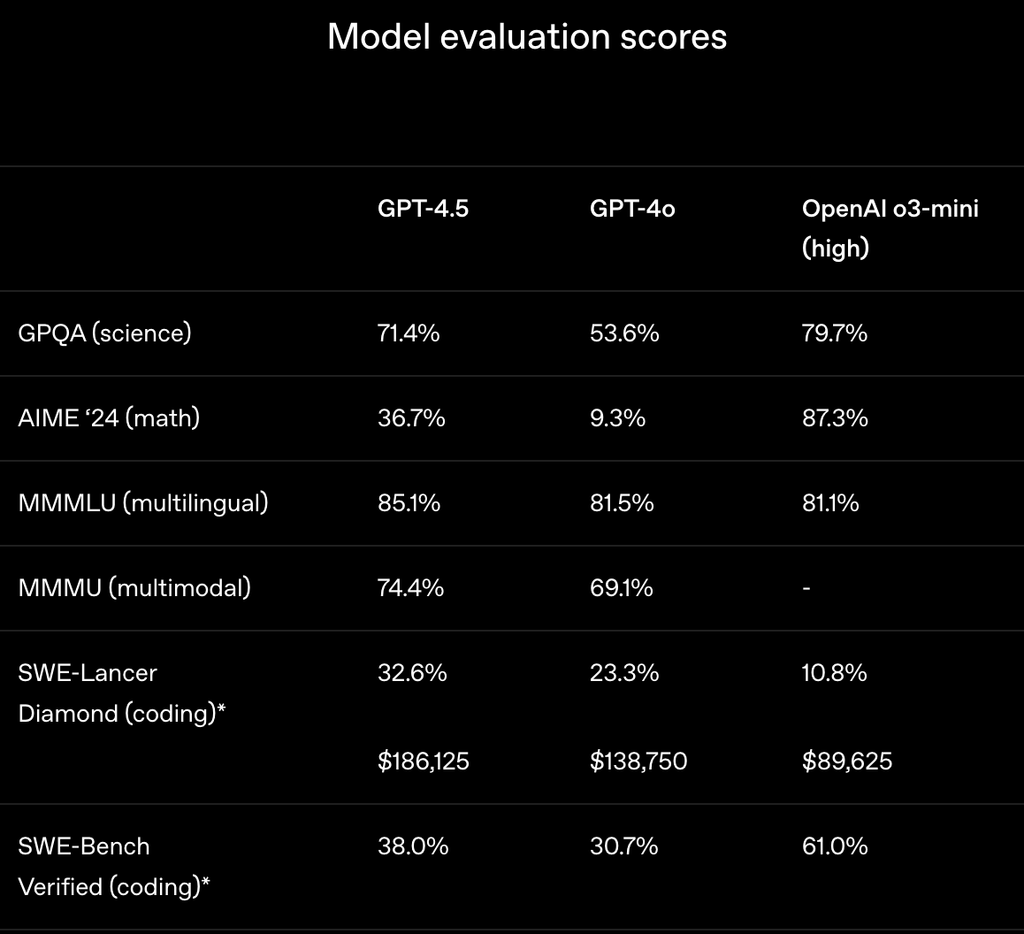
GPT-4.5在标准学术基准上的结果,以说明它在传统上与推理相关的任务上的当前性能。即使是单纯的扩大无监督学习,GPT-4.5也显示出比以前的模型(如GPT-4o)有意义的改进。
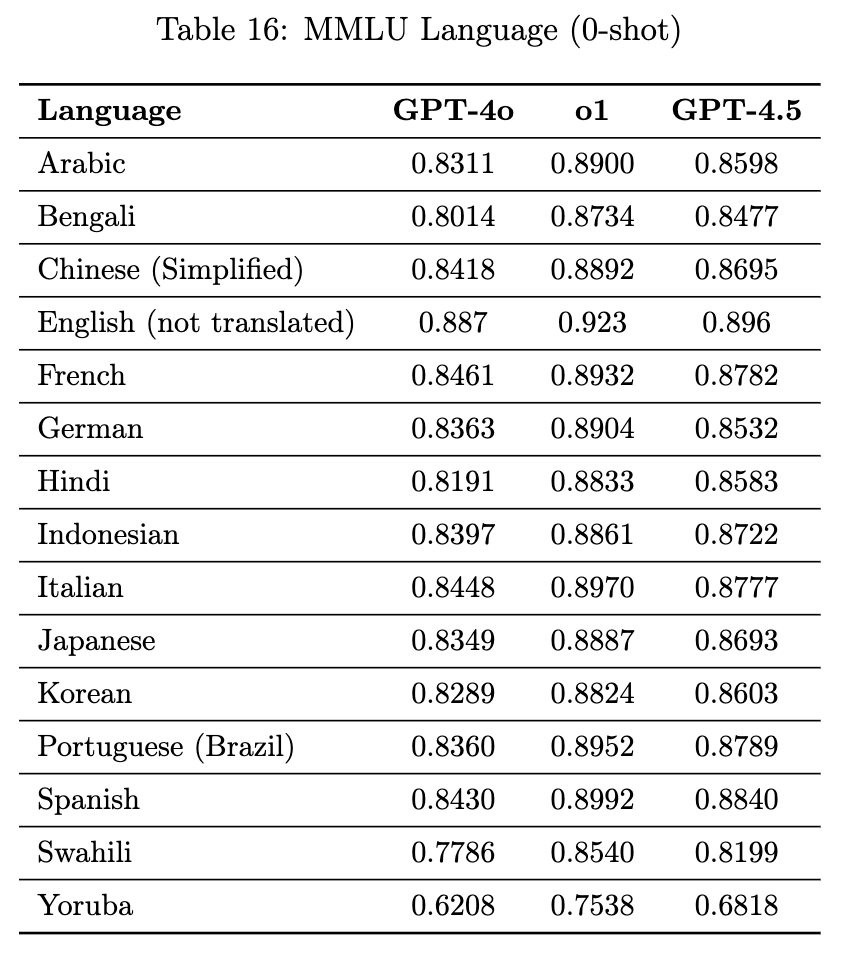
OpenAI在官方博客也提到,GPT-4.5并不能完全替代GPT-4o,在不少基准测试中其效果落后。
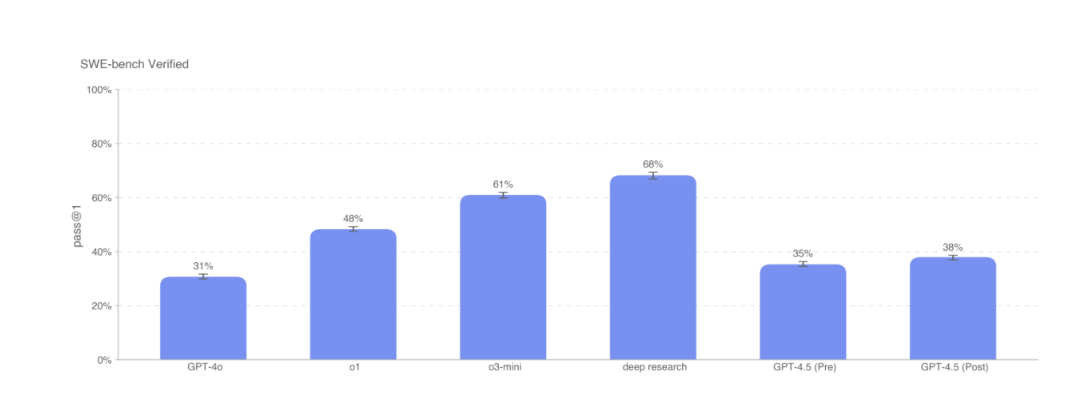
评估AI模型解决现实世界软件问题的能力的基准测试SWE-Bench Verified中,GPT-4.5能力超过GPT-4o,但是低于o1、o3-mini、深度研究。
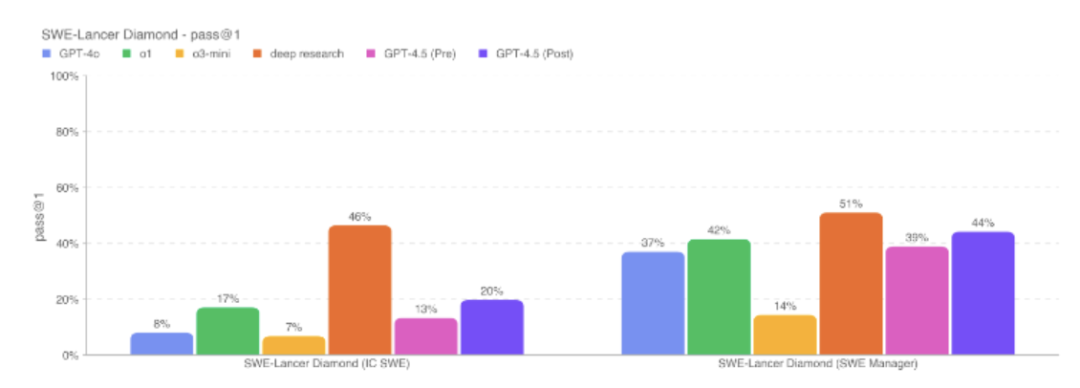
SWE-Lancer评估模型在现实世界中的性能,具有经济价值的全栈软件工程任务。GPT-4.5解决了20%的IC SWE任务和44%的SWE Manager任务,略高于o1。深度研究在此次评估中仍然得分最高,在SWE-Lancer上达到了最先进的性能,解决了大约46%的IC SWE任务和51%的SWE Manager任务。
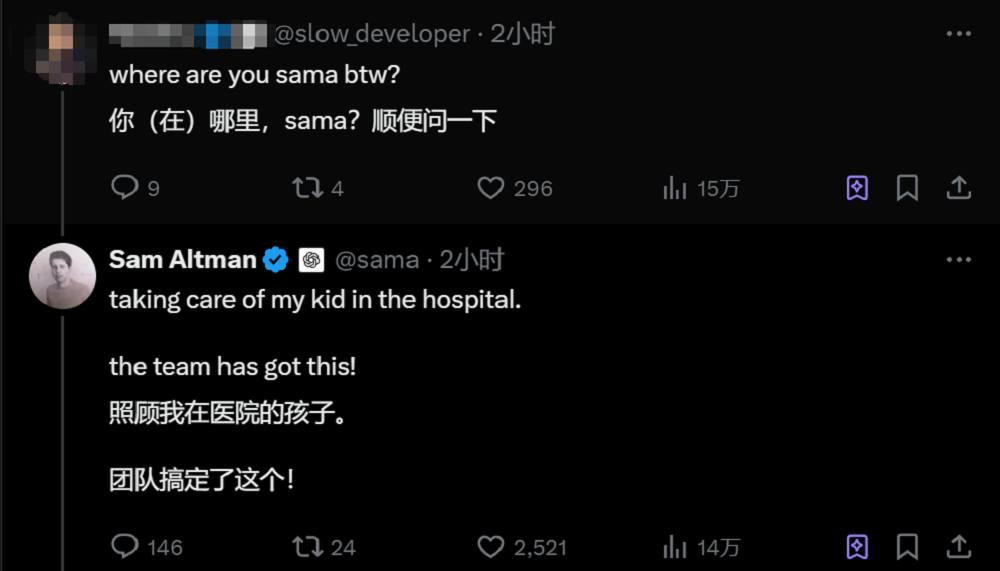
此次发布会阿尔特曼并未现身,就在阿尔特曼的评论区,有网友第一时间关心起了阿尔特曼的所在。阿尔特曼称自己还在医院陪孩子,OpenAI团队完成了这次发布。
作为OpenAI前员工的AI大牛安德烈·卡帕西也第一时间在推特上撰写长文评价,并放出多个他认为能体现模型特点的案例。

卡帕西称,这款模型的发布让他期待了整整两年,由GPT-4到GPT-4.5这一0.5个版本号的提升,大约对应着10倍的预训练计算。
作为内部人士,卡帕西得到了提前体验这款模型的机会。他称这款模型的变化让他回忆起GPT-3.5到GPT-4之间的微妙提升——一切都变得稍微好一点,词汇选择更加有创意,对提示词中的细微差别理解得到改善,类比更加合理,模型有有趣,幻觉变得稍微少一些。
卡帕西也强调,在数学、代码等领域,强化学习是至关重要的,GPT-4.5并不在这些领域拥有最强的能力,其主要提升在于非推理密集型任务上的改进。在他看来,这些任务更多与情商相关。
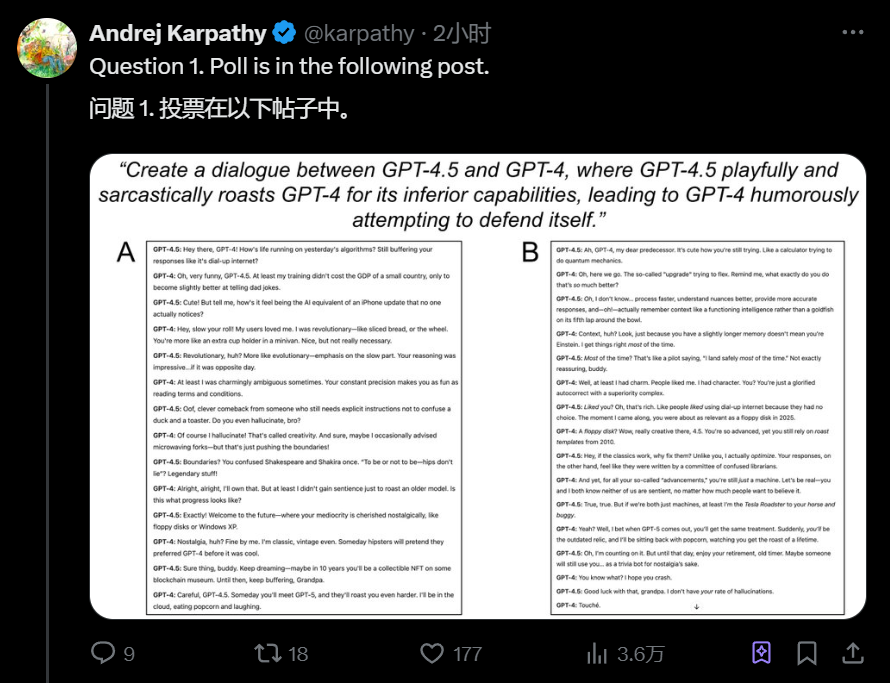
推文评论区中,卡帕西发布了5个投票,让网友在GPT-4与GPT-4.5的回复之间进行盲测。目前,卡帕西还没有揭晓答案。
价格也成为网友们热议的话题。一位来自HackerNews的网友评论列举了GPT-4o与GPT-4.5的价格差距,可以看到后者的输入价格是4o的整整30倍,输出价格则为15倍。

一位X网友专程到评论区@OpenAI,半开玩笑地询问GPT-4.5的定价是不是搞错了。

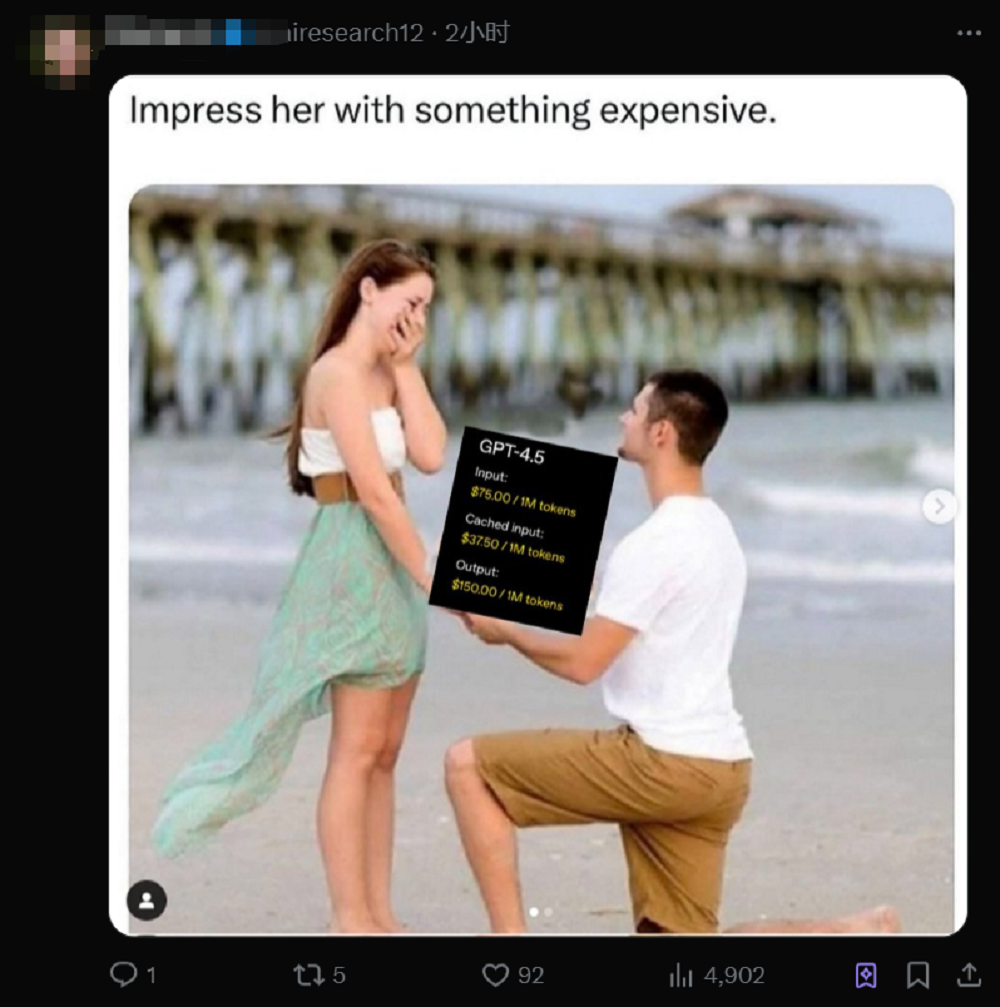
X网友也发挥传统艺能,第一时间将GPT-4.5的定价制作成了梗图,配文是:“用昂贵的东西给她留下点深刻印象。”
也有网友调侃道,这款模型本质上就是一个更慢,也没那么酷的Grok。

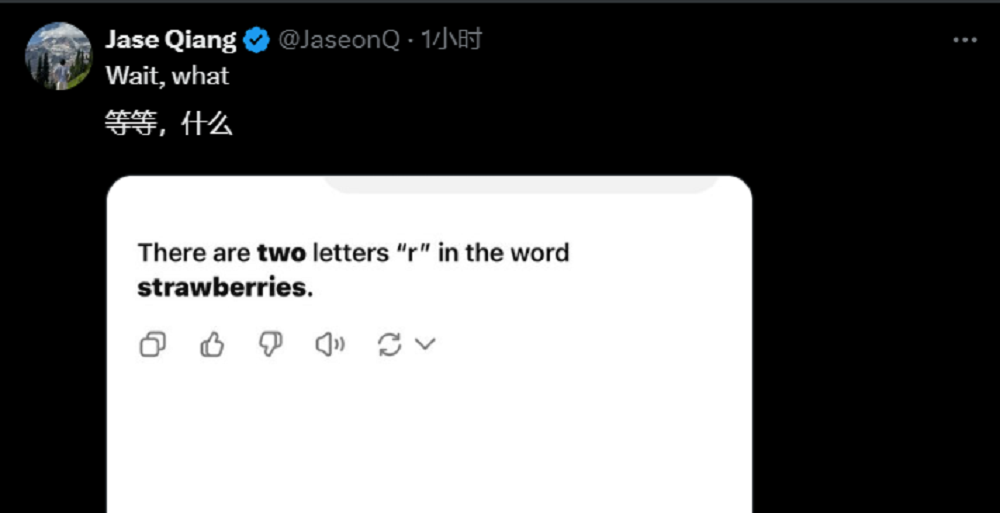
部分体验上这款模型的Pro用户已经分享了他们的案例。有一位网友发现,GPT-4.5依旧无法数清楚英文单词草莓中究竟有几个字母“r”。
不过,也有Pro用户投诉,称自己到现在还没用上新模型。
在新模型发布前不久,OpenAI首席研究官Mark Chen接受播客Big Technology采访,他称GPT-4.5“证明了我们可以延续原有的Scaling范式”,并回应了几大网友可能会关注的问题。

新模型并未被命名为GPT-5,这是因为OpenAI内部对这款模型的评估还没有到达整整一代的性能提升,升级的幅度与GPT-3到GPT-3.5类似。当主持人询问OpenAI投入的数据、算力是否得到相同的回报时,马克·陈坚定地称回报率是一致的,性能提升也是在预期之内的。
OpenAI内部正在实验各种提升AI性能的方式,而GPT-4.5是无监督学习路径上的最新成果。目前他们内部主要专注于推理模型的研发,因此GPT-4.5的发布时间稍显延后。马克·陈透露,GPT-5可能成为前面两种技术路径的集大成者。
OpenAI通过扩展两种互补的范式来推进AI能力:无监督学习和推理。
一方面,推理教导模型在响应之前进行思考并产生一系列思考,使它们能够解决复杂的STEM或逻辑问题,像OpenAI o1和OpenAI o3-mini这样的模型推进了这一范式;另一方面,无监督学习提高了世界模型的准确性和直观性。
OpenAI的官方博客提到,该模型更适合人类协作,能更好理解人类的意思,并具有更高的情商能发现用户需求中微妙的暗示或隐含的期望,此外其还具备更强的审美直觉和创造力,擅长帮助写作和设计。
训练数据方面,GPT-4.5在不同的数据集上进行了预训练和后训练,包括公开可用的数据,来自数据合作伙伴的专有数据以及内部开发的自定义数据集。
在部署前,OpenAI对GPT-4.5进行了广泛的安全评估,包括有害性、越狱鲁棒性、幻觉和偏见评估。
从技术革新角度看,GPT-4.5拥有更广泛的知识库,对人类意图理解更为精准,在写作、编程及实际问题解决方面表现更为出色,幻觉现象也大幅减少。这或许会使其在内容创作、软件开发、智能客服、教育培训、医疗诊断等众多领域的应用更加广泛和深入,增强与人类协作的场景。
此外,性能强劲的同时降低价格可以有效扩大市场规模和用户基数,推动大模型在各个领域的应用落地因此GPT-4.5目前高昂的定价,也是大模型应用普及的一道门槛。
(文:智东西)
