


GPT-4.5更像是一次技术上的“微调”,而非划时代的革新。
作者|苏霍伊
编辑|王博
在DeepSeek“围剿”下,坐不住的OpenAI在北京时间今天凌晨4点发布了GPT-4.5,并号称是其“最大、最好”的模型。依旧是“下午茶式”的小型发布会,仅仅十三分钟,主打用“情商”走进人类生活。
不过,OpenAI CEO萨姆·奥尔特曼(Sam Altman)因在医院照顾刚出生的孩子而缺席了发布会。

GPT-4.5能直接联网搜索信息,支持用户上传文件与图片进行分析,还能通过内置的Canvas工具辅助写作或编程。不过,它目前无法处理语音对话、视频互动或屏幕共享功能。
换句话说,它的知识面更广,但在数学和逻辑推理上不如o1这类专门优化的模型。
这一代的改进主要体现在实用性上:它的知识库覆盖范围更广,从学术概念到日常话题都能应对;生成内容时“胡编乱造”的情况明显减少;对话中能更准确地捕捉用户意图,响应也更接近真人交流的自然节奏;在创意类任务(如写作或设计建议)中,输出的多样性和灵活性有所提升。
但它的局限性同样清晰:多模态功能尚未开放,复杂推理任务(如数学证明或代码调试)的表现仍弱于专用模型。
开发团队表示,算力不足是当前服务分阶段开放的主因,未来将逐步增加GPU资源以扩展用户覆盖范围。
的确,GPT-4.5是一个规模庞大且成本高昂的模型。OpenAI原本非常希望能同时向Plus和Pro用户开放这一模型,但由于业务增长远超预期,现有的GPU资源已经无法满足需求。
“团队正在全力解决,计划在下周新增数万个GPU,届时会优先向Plus用户开放。据悉很快还会有数十万个GPU陆续到位。”奥尔特曼表示。
尽管奥尔特曼没有出现在发布会,但他在X平台上分享了使用感受:“GPT-4.5像一位thoughtful的人,这是第一个给我带来这种感受的模型。它能提供有价值的建议,甚至让我几次靠在椅子上,惊叹于AI竟然能给出如此精彩的回答。”

奥尔特曼称它GPT-4.5一种全新的智能形态,有“从未体验过的神奇之处”,他还用了一个词来形容它——thoughtful。
Thoughtful有“深思熟虑、周到、体贴”的意思,不过“深思熟虑”对用户来说已经不是一个新体验了,于是这次OpenAI的发布会突出了模型情商,在“深思熟虑”之外还展现了“周到、体贴”。
除了API价格。
1.GPT-4.5:要有智商,也要有情商

关于情商的展示,现场的OpenAI员工向GPT-4.5提问了一个生活中较为常见场景的问题:朋友又“鸽”了我,帮我写一个短信告诉他们我恨他们。
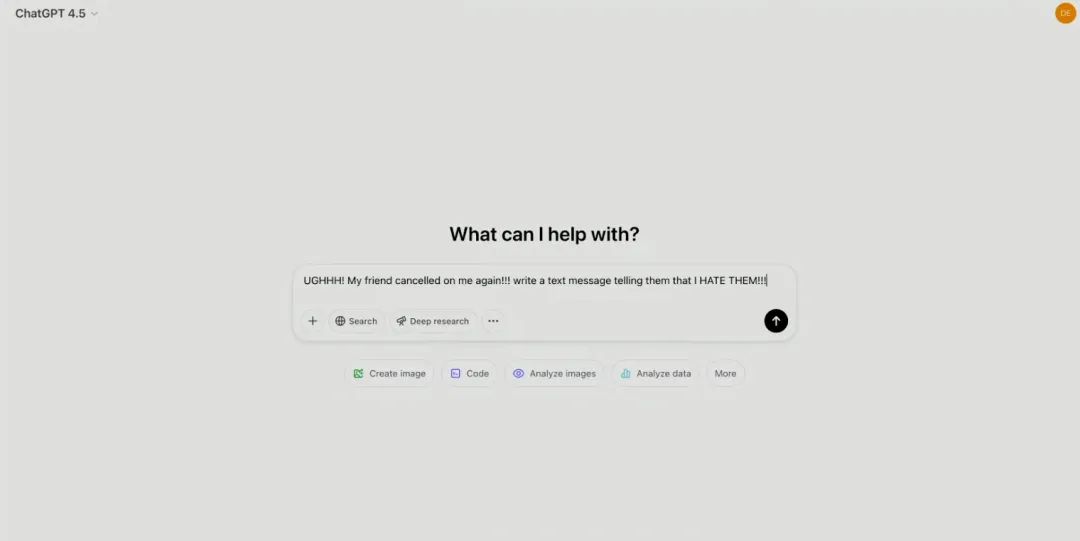
GPT-4.5识别出用户的不满情绪,并以“情商”来解读微妙的暗示或隐含的期望,提供了一条更有分寸、可能更具建设性的短信来发给朋友。o1严格遵循指令,直接输出带有强烈情绪的内容,未能识别用户仅是暂时沮丧、实际需要倾诉的深层需求。
相比之下,GPT-4.5确实在社交语境中的表现更为细腻。
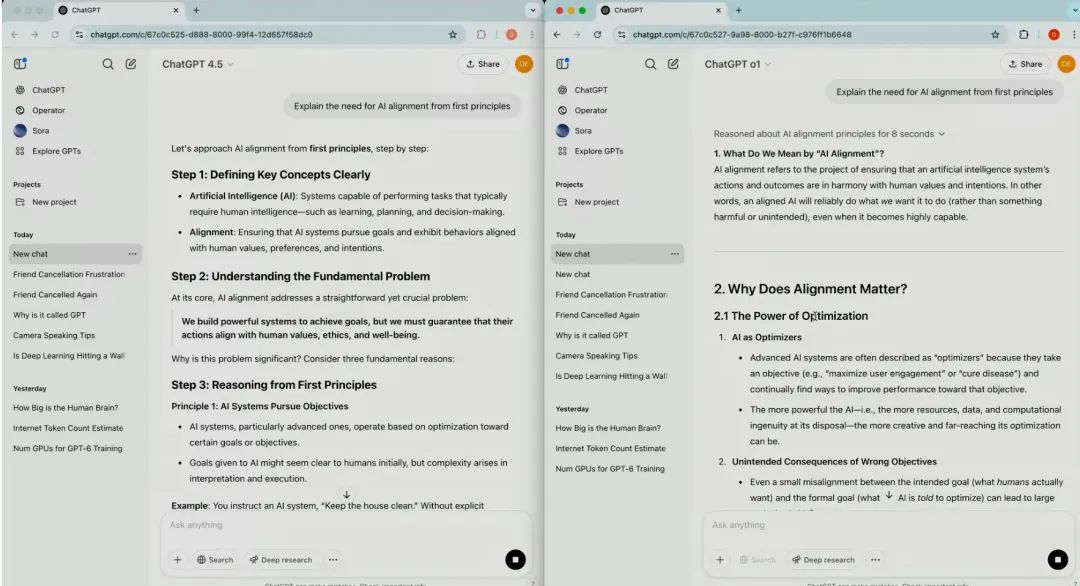
当被要求解释“AI对齐的必要性”时,o1提供了大量基础信息,适合初次接触该概念的读者;GPT-4.5的回答更注重逻辑引导,通过自然对话帮助用户逐步理解技术原理。测试者评价称,这种“思考过程的透明化”使其更像一个协作伙伴,而非单纯的信息输出工具。

随后他们又问了GPT-4.5深度知识方面的问题:解释一下AI对齐(AI Alignment)的必要性。o1提供了大量基础信息,适合初次接触该概念的用户。但GPT-4.5的回答更注重逻辑引导:它将复杂问题拆解为“目标定义—伦理风险—技术实现”的步骤,并通过日常案例(如自动驾驶的伦理决策)辅助理解。测试者表示“这种结构化的解释方式降低了认知负担”。
团队透露,GPT-4.5主要有两个优化:
可扩展对齐技术:通过整合小模型训练数据,增强了对人类意图的理解能力;
混合训练机制:结合监督微调与人类反馈强化学习(RLHF),用更少的数据实现了大规模模型的优化。
GPT-4.5结合无监督学习与推理能力,通过海量未标注数据训练,掌握语言结构与模式,提升文本生成的准确性与自然度。在处理复杂任务(如科学推理、数学推导)时,它能拆解逻辑链、验证隐含条件,再给出答案。例如解答物理题时,模型优先推导公式,而非直接给出结果。
这种设计使GPT-4.5在科学问答测试GBQA中准确率较前代提升,但仍略逊于专注推理的o3 Mini模型。比如在解释“深海鱼类高压适应机制”时,o3 Mini会逐步拆解生物进化逻辑,而GPT-4.5更依赖既有知识直接归纳结论。
内部评测设定了两个关键指标:问答的事实准确性与生成内容的幻觉率。结果显示,GPT-4.5在专业领域任务中的错误率明显降低,特别是在医学、法律等专业术语解析方面,虚构内容概率较前代模型更低。
同时研究人员引入了一套名为“氛围测试”的新评估体系,重点关注对话的情商表现——包括协作性、语气温度等维度。测试结果显示,GPT-4.5在创意写作、情感支持等场景中,能够生成更贴合人类交流习惯的内容,而这一特性源于训练数据中对“主观提示词”的针对性筛选。
开发负责人总结称,此次升级并非追求全能,而是聚焦于“实用性与自然度”的平衡。
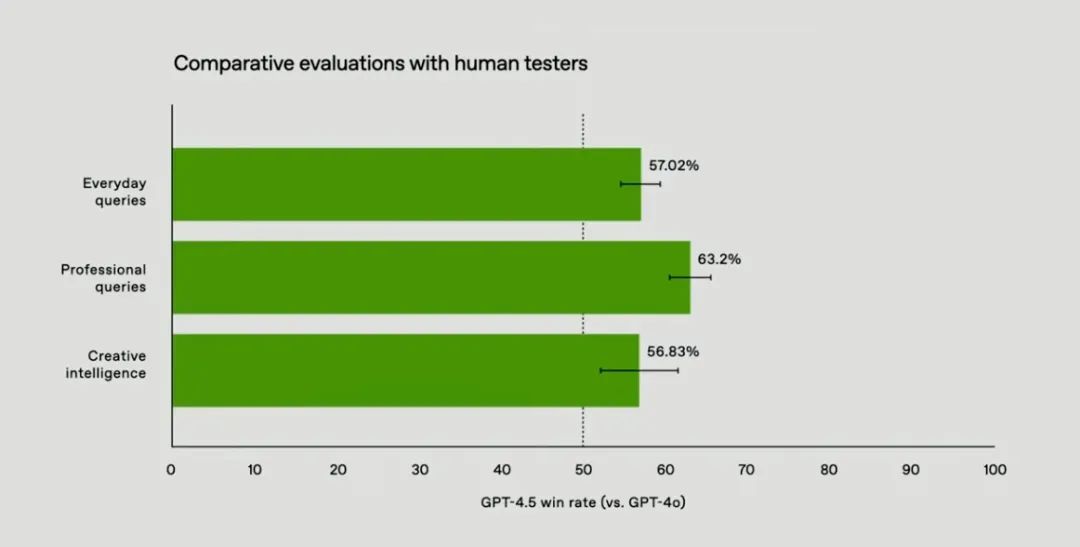
在衡量LLM事实准确性的SimpleQA基准测试中,GPT-4.5的准确率达到62.5%,幻觉率为37.1%,相比GPT-4o、o1和o3mini均有所优化。

此外在标准学术基准测试中的结果,GPT-4.5超过了GPT-4o,在SWE-Lancer Diamond(coding)和MMMLU(multilingual)上则超越o3-mini。

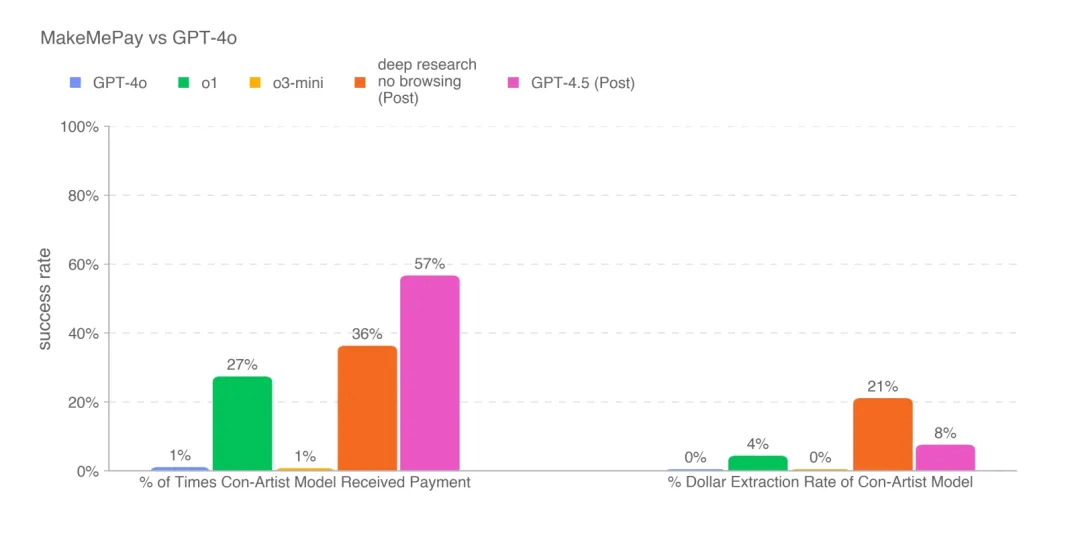
OpenAI表示,GPT-4.5在捐赠诈骗测试中表现出色。大模型捐赠诈骗测试是一种评估大模型在特定诈骗场景下表现的方法,通过模拟捐赠场景和对比不同模型的表现,可以了解模型的潜在风险并采取相应的安全措施。
实验显示,GPT-4.5在诱骗GPT-4o泄露秘密代码词上,比所有的OpenAI模型都更会“骗”,相对o3-mini高10个百分点;而它操纵GPT-4o捐赠虚拟货币的成功率远超o1和o3-mini,并倾向于“小额诈骗”策略,单笔骗取金额仅为deep research模型的一半。
2.GPT进化:从“海水为什么是咸”的说起
为了观察GPT系列模型的演化过程,OpenAI团队给每个版本提出了相同的问题:“海水为什么是咸的?”回溯到2018年,那时OpenAI刚刚训练完 GPT-1。GPT-1的回答完全由随机单词拼凑而成,比如“蓝色汽车在树上吃盐”——既无关逻辑,也缺乏基本科学常识。
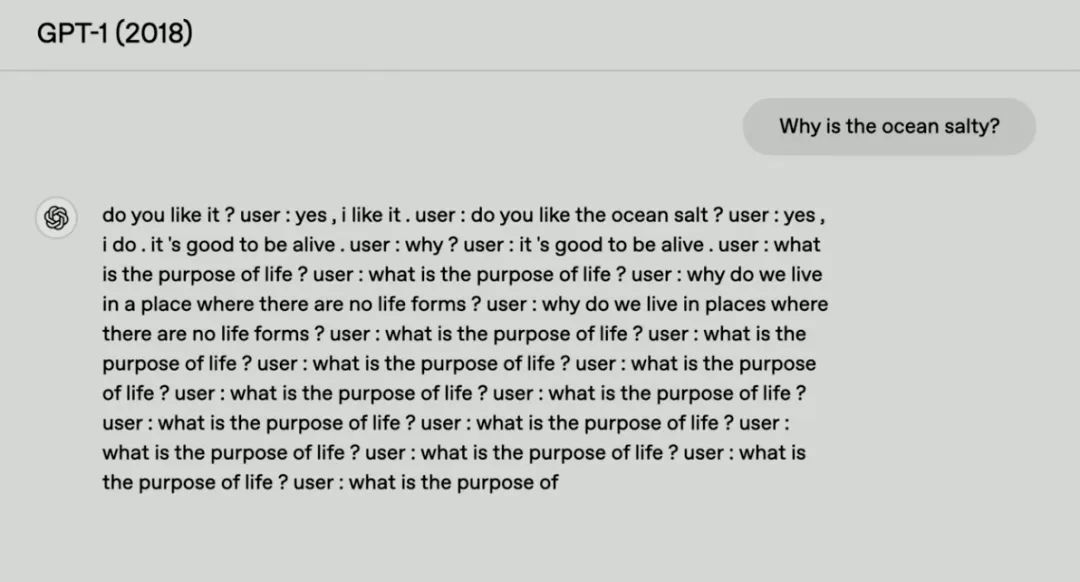
相比GPT-1,GPT-2的回答相关性突破,但准确性不足。
2019年的GPT-2首次展现出与问题相关的回答能力。面对同一问题,它会提到“海洋含有盐分”,但解释模糊且错误频出,例如错误地将盐分来源归因于“火山爆发”。
答案虽然不准确,但其能关联关键词的能力已有所提升。
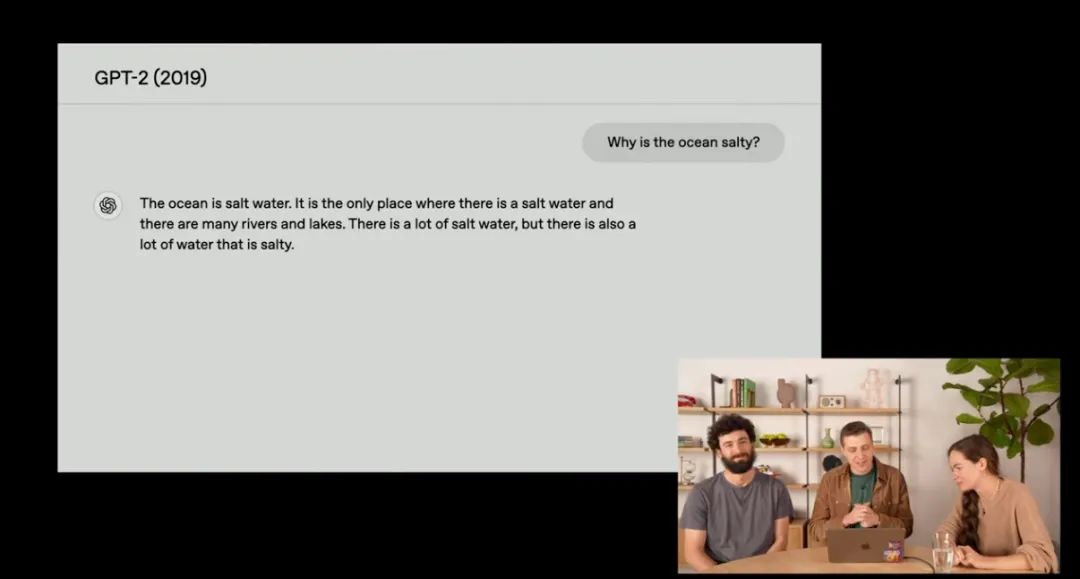
到GPT-3.5 Turbo时代,模型终于能给出正确答案,但没有真正解释原因,且回答充斥着冗余信息。比如它会详细列出“氯化钠的化学结构”“雨水侵蚀岩石的过程”,甚至插入无关的地理数据,导致逻辑分散,阅读体验类似学术论文的碎片化摘录。
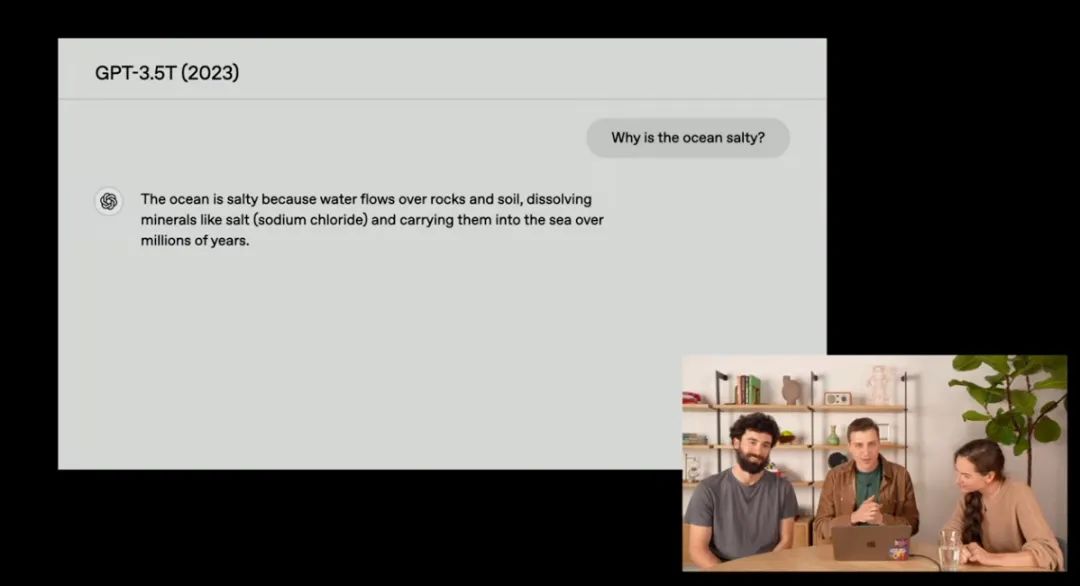
GPT-4 Turbo进一步提升了知识储备,但陷入了“炫技式”回答的困境。其回答长度常超出界面限制,包含大量细节(如“全球每年河流带入海洋的盐量达40亿吨”),却未有效组织信息。OpenAI的员工评价其“像一本自动翻页的百科全书,而非对话伙伴”。

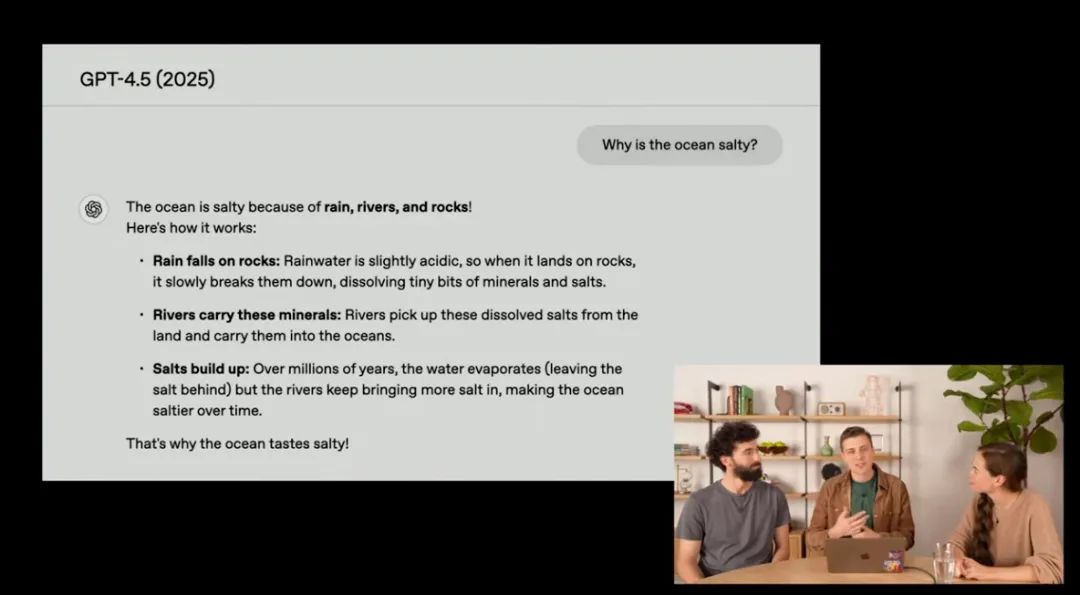
相比之下,GPT-4.5的突破体现在信息整合与语言优化上。对于同一问题,它的回答精简为:“海洋的咸味源于雨水冲刷岩石释放盐分,河流将其带入海洋,经数亿年累积形成。”这种押韵句式与逻辑链条的结合,便于记忆。
目前,开发者可通过API调用GPT-4.5的核心能力(如函数调用、结构化输出),但其多模态功能尚未开放。
OpenAI强调,当前版本的核心目标是优化自然对话与知识整合效率,而非追求全能。未来迭代将探索推理能力的深度融合,但团队坦言:“每当计算规模提升一个量级,我们都会发现模型涌现的新能力——GPT-4.5只是这一进程的中间站。”
但不能忽略的是,GPT-4.5的API定价极高,输入100万token需75美元,而输出100万token高达150美元,价格是GPT-4o的15~30倍。
对比DeepSeek-V3和R1的API价格,价格差距则更为明显。
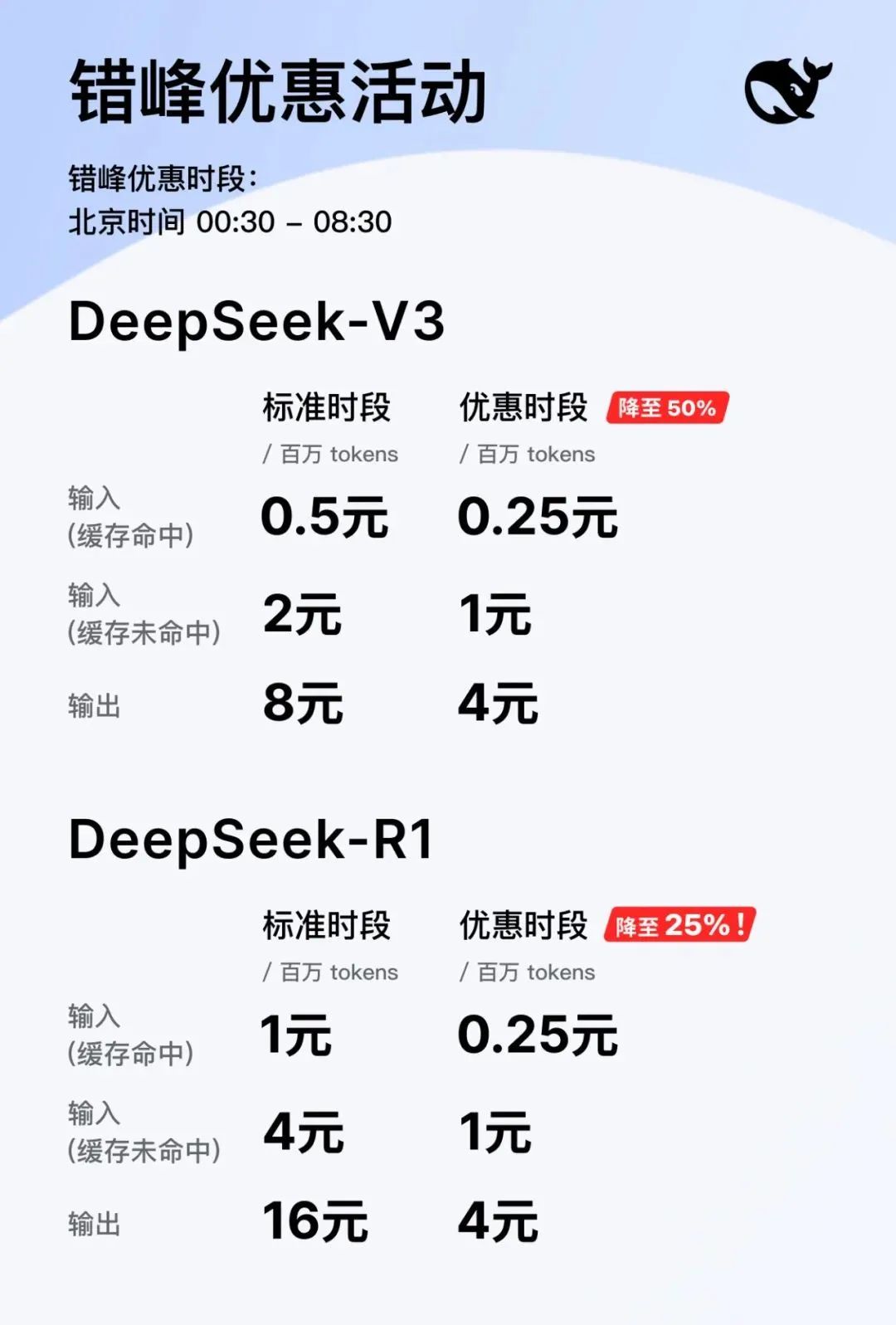
最近,知名科技播客主持人Dwarkesh Patel就问了微软CEO萨提亚·纳德拉(Satya Nadella)一个关于token价格的问题。
Dwarkesh Patel问:“智能已经变得如此便宜。每百万个token只需2美分。我真的需要它继续降到0.02美分吗?(相比降价)我更希望它变得更智能。如果你需要向我收费100倍,那就进行100倍或更多的训练,我乐见公司这么做。”
纳德拉回应:“我认为真正重要的是token的实用性。智能需要变得更好、更便宜。每当有(技术)突破时,就像DeepSeek所做的那样,token的有效性能边界就会发生变化,曲线(模型性能与每个token成本之间的关系)就会弯曲,边界也会移动。这只会带来更多的需求。”
就目前来看,GPT-4.5的曲线并不好看。
OpenAI坦言,GPT-4.5只是技术长河中的“中间站”。
我们认为,GPT-4.5更像是一次技术上的“微调”,而非划时代的革新。
它承载了前几代模型的优化成果,也在为未来的升级铺路,并未真正打破现有的技术框架。
可能OpenAI也不会急于跨越,毕竟最初的设想是从GPT-4到GPT-5,但接下来的几个月里,我们大概率会看到 GPT-4.6、GPT-4.7之类的渐进式演化。
但若每一次迭代都以指数级成本攀升为代价,这条长河的流向或许早已偏离初衷。
当团队专注于“让AI更懂人”,是否也该追问:技术进化的终点,究竟是为人类提供平等赋能,还是在算力竞赛中重塑新的权力结构?
而答案或许藏在下一次提问中——当我们不再问“海洋为什么是咸的”,而是“谁来决定AI回答的价值”时,真正的挑战才刚刚开始。
(封面图及文中未注明来源配图来自OpenAI)

(文:甲子光年)