跳至内容
开源周来到第五天,迎来了一个许多人等待了两年的开源:3FS。作为开源周的压台之作,3FS 的意义不可小觑:它不仅仅在于性能参数,更在于重构了 AI 训练的底层逻辑。
3FS 是幻方 AI 自研的高速读写文件系统,早在 2022 年的时候,幻方官方就发布了技术概览。全称是萤火超算文件系统(Fire-Flyer File System),因为有三个连续的 F,因此被简称为 3FS。
在当年,它只是一个内部专用的技术,深度依赖幻方自研的超算集群硬件,需配合特定型号的交换机和网卡。而且采用传统目录树结构,百万级文件遍历耗时长。
DeepSeek 开源周,APPSO 将持续带来最新动态和解读,往期回顾👇
Day1 :一文看懂 DeepSeek 刚刚开源的 FlashMLA,这些细节值得注意
Day2 :榨干每一块 GPU!DeepSeek 开源第二天,送上降本增效神器
Day3:一文看懂 DeepSeek 开源项目第三弹,300 行代码揭示 V3/R1 推理效率背后的关键
Day4:一文看懂 DeepSeek 开源第四弹,梁文锋亲自下场开发
3FS 是一个比较特殊的文件系统,因为它几乎只用在 AI 训练时计算节点中的模型批量读取样本数据这个场景上,通过高速的计算存储交互加快模型训练。
2023 年前的 3FS 已采用分解式架构雏形,但受限于硬件绑定和功能范围;而当前版本通过全栈解耦、协议优化和生态兼容,将其发展为通用型 AI 存储基座。
这一演进印证了,存储系统从专用设施向基础设施层的转型趋势——从 closed ai 走向 open ai,怎么不算一种逆流而上。
分解式架构就好像在城市上空架起多维立交桥。以前存储节点和计算节点就像固定搭配的收费站与服务区,当 AI 训练需要同时调度数百个节点时,数据只能在预设路径上「堵车」。
通过将存储节点与计算节点物理分离,让数据流动不再受物理位置限制。同时通过 FFRecord 格式管理数据库:想象一个快递站,面对大量小包裹时,快递找货会找到崩溃。3FS 的做法是按 FFRecord 格式)装进大集装箱并贴上索引标签,根据索引查找,速度直线上升。
这就是 FFRecord 格式的逻辑,将数百万小文件合并为逻辑大文件,通过索引文件记录样本偏移量。3FS 通过 6.6 TiB/s 的聚合读取吞吐,相当于每秒传输 1400 部 4K 电影,直接将 ImageNet 数据集加载耗时从 15 秒压缩到 0.29 秒。
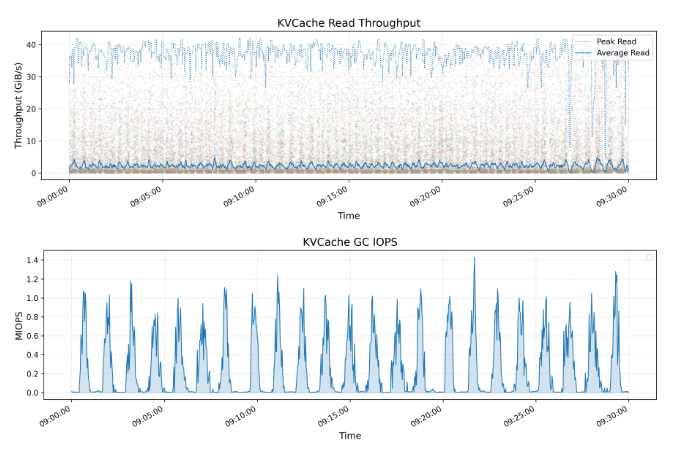
KVCache是一种用于优化大语言模型(LLM)推理过程的技术。它通过缓存解码层中先前token的key和value向量,避免了冗余计算。上方的图表展示了所有KVCache客户端的读取吞吐量,包括峰值和平均值,其中峰值吞吐量高达40 GiB/s。
大模型推理时,临时数据存 DRAM 内存(保险柜)太贵,存普通硬盘又太慢。3FS 想了个妙招:用平价高速仓库(SSD 硬盘)当缓存,成本只有 DRAM 的 1/10,但速度能达到 90%。再通过闪电取货通道(RDMA 网络),速度高达 40GB/s,相当于 1 秒传完 80 部高清电影。
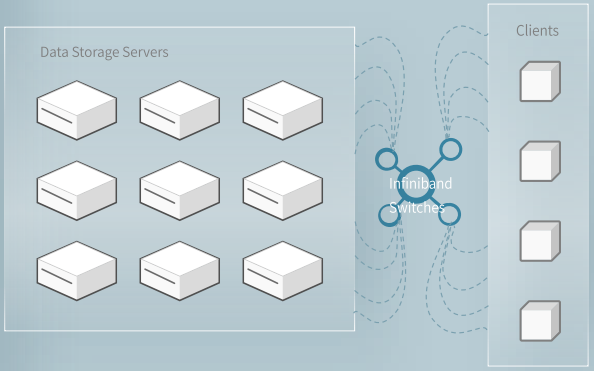
下图展示了一个大型 3FS 集群的读压测吞吐情况。该集群由 180 个存储节点组成,每个存储节点配备 2×200Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。大约 500+ 个客户端节点用于读压测,每个客户端节点配置 1x200Gbps InfiniBand 网卡。在训练作业的背景流量下,最终聚合读吞吐达到约 6.6 TiB/s。
整个 3FS 的设计,既包含了空间的重构:存算分离,数据存放 FFRecord 格式化;又包含了 CRAQ 协议、SSD 物理块直读+RDMA 等等等等。
当其他团队还在优化单个技术指标时,3FS 已实现存储介质、网络协议、分布式算法的深度协同,让存储系统从「被动仓库」进化为「智能供血系统」。
这指向的不仅仅是性能优化,而是对 AI 训练底层逻辑的重新塑造。

我们正在招募伙伴
✉️ 邮件标题
「姓名+岗位名称」(请随简历附上项目/作品或相关链接)

(文:APPSO)