
Wan:开放和先进的大规模视频生成模型
在此存储库中,我们介绍了 Wan2.1,这是一套全面而开放的视频基础模型,它突破了视频生成的界限。Wan2.1 提供以下主要功能:
- 👍 SOTA 性能:Wan2.1 在多个基准测试中始终优于现有的开源模型和最先进的商业解决方案。
- 👍 支持消费级 GPU:T2V-1.3B 型号仅需 8.19 GB VRAM,几乎兼容所有消费级 GPU。它可以在大约 5 分钟内在 RTX 4090 上生成 4 秒的 4P 视频(无需量化等优化技术)。它的性能甚至可以与一些闭源模型相媲美。
- 👍 多任务:Wan2.1 擅长文本到视频、图像到视频、视频编辑、文本到图像和视频到音频,推动了视频生成领域的发展。
- 👍 视觉文本生成:Wan2.1 是第一个能够同时生成中英文文本的视频模型,具有强大的文本生成功能,增强了其实际应用。
- 👍 强大的视频 VAE:Wan-VAE 提供卓越的效率和性能,对任意长度的 1080P 视频进行编码和解码,同时保留时间信息,使其成为视频和图像生成的理想基础。
🔥 最新消息!!
- 2025 年 2 月 25 日:👋我们发布了 Wan2.1 的推理代码和权重。
- 2025 年 2 月 27 日:👋 Wan2.1 已集成到 ComfyUI 中。享受!
📑 待办事项列表
- Wan2.1 文本到视频
- 14B 和 1.3B 模型的多 GPU 推理代码
- 14B 和 1.3B 模型的检查点
- 构建演示
- ComfyUI 集成
- 扩散器集成
- Wan2.1 图像到视频
- 14B 模型的多 GPU 推理代码
- 14B 模型的检查点
- 构建演示
- ComfyUI 集成
- 扩散器集成
快速入门
安装
克隆存储库:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
安装依赖项:
# Ensure torch >= 2.4.0
pip install -r requirements.txt
模型下载
| 模型 | 下载链接 | 笔记 |
|---|---|---|
|
|
|
支持 480P 和 720P |
|
|
|
支持 720P |
|
|
|
支持 480P |
|
|
|
支持 480P |
💡请注意: 1.3B 型号能够生成 720P 分辨率的视频。但是,由于此分辨率下的训练有限,因此与 480P 相比,结果通常不太稳定。为了获得最佳性能,我们建议使用 480P 分辨率。
使用 huggingface-cli 下载模型:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
使用 modelscope-cli 下载模型:
pip install modelscope
modelscope download Wan-AI/Wan2.1-T2V-14B --local_dir ./Wan2.1-T2V-14B
运行文本到视频生成
此存储库支持两种文本到视频模型(1.3B 和 14B)和两种分辨率(480P 和 720P)。这些模型的参数和配置如下:
| 任务 | 分辨率 |
|
|
|---|---|---|---|
|
|
|
||
|
|
|
|
广域网2.1-T2V-14B |
|
|
|
|
广域网2.1-T2V-1.3B |
(1) 没有及时延期
为了便于实施,我们将从跳过提示扩展步骤的基本版本的推理过程开始。
- 单 GPU 推理
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
如果您遇到 OOM(内存不足)问题,可以使用 --offload_model True 和 --t5_cpu 选项来减少 GPU 内存使用量。例如,在 RTX 4090 GPU 上:
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
💡注意:如果您使用的是
T2V-1.3B型号,我们建议将参数--sample_guide_scale 6设置。--sample_shift 参数可以根据性能在 8 到 12 的范围内进行调整。
- 使用 FSDP + xDiT USP 的多 GPU 推理
pip install "xfuser>=0.4.1"
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
(2) 使用提示扩展
扩展提示可以有效地丰富生成的视频中的细节,进一步提升视频质量。因此,我们建议启用提示扩展。我们提供以下两种提示扩展方式:
- 使用 Dashscope API 进行扩展。
- 提前申请
dashscope.api_key(EN |CN)。 DASH_API_KEY配置环境变量以指定 Dashscope API 密钥。对于阿里云国际站的用户,您还需要将环境变量DASH_API_URL设置为 ‘https://dashscope-intl.aliyuncs.com/api/v1‘。有关更详细的说明,请参阅 dashscope 文档。- 将
qwen-plus模型用于文本到视频任务,将qwen-vl-max用于图像到视频任务。 - 您可以使用参数
--prompt_extend_model修改用于扩展的模型。例如:
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'ch'
-
使用本地模型进行扩展。
- 默认情况下,HuggingFace 上的 Qwen 模型用于此扩展。用户可以根据可用的 GPU 内存大小选择 Qwen 模型或其他模型。
- 对于文本转视频任务,您可以使用
Qwen/Qwen2.5-14B-Instruct、Qwen/Qwen2.5-7B-Instruct和Qwen/Qwen2.5-3B-Instruct等模型。 - 对于图像到视频任务,您可以使用
Qwen/Qwen2.5-VL-7B-Instruct和Qwen/Qwen2.5-VL-3B-Instruct等模型。 - 较大的模型通常提供更好的扩展结果,但需要更多的 GPU 内存。
- 您可以使用参数
--prompt_extend_model修改用于扩展的模型,从而允许您指定本地模型路径或 Hugging Face 模型。例如:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'ch'
(3) 运行本地无线电
cd gradio
# if one uses dashscope’s API for prompt extension
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14B
# if one uses a local model for prompt extension
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14B
运行图像到视频生成
与 Text-to-Video 类似,Image-to-Video 也分为带和不带提示扩展步骤的进程。具体参数及其对应的设置如下:
| 任务 | 分辨率 |
|
|
|---|---|---|---|
|
|
|
||
|
|
|
|
广域2.1-I2V-14B-720P |
|
|
|
|
广域网2.1-T2V-14B-480P |
(1) 没有及时延期
- 单 GPU 推理
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
💡对于 Image-to-Video 任务,
size参数表示生成的视频的区域,长宽比遵循原始输入图像的长宽比。
- 使用 FSDP + xDiT USP 的多 GPU 推理
pip install "xfuser>=0.4.1"
torchrun --nproc_per_node=8 generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
(2) 使用提示扩展
提示扩展的流程可以参考这里。
使用 Qwen/Qwen2.5-VL-7B-Instruct 通过本地提示符扩展运行:
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
使用 dashscope 通过远程提示扩展运行:
DASH_API_KEY=your_key python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_method 'dashscope' --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
(3) 运行本地无线电
cd gradio
# if one only uses 480P model in gradio
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P
# if one only uses 720P model in gradio
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
# if one uses both 480P and 720P models in gradio
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
运行文本到图像生成
Wan2.1 是图像和视频生成的统一模型。由于它针对这两种类型的数据进行了训练,因此它还可以生成图像。生成图片的命令类似于视频生成,如下所示:
(1) 没有及时延期
- 单 GPU 推理
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人'
- 使用 FSDP + xDiT USP 的多 GPU 推理
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --prompt '一个朴素端庄的美人' --ckpt_dir ./Wan2.1-T2V-14B
(2) 及时延长
- 单 GPU 推理
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
- 使用 FSDP + xDiT USP 的多 GPU 推理
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
手动评估
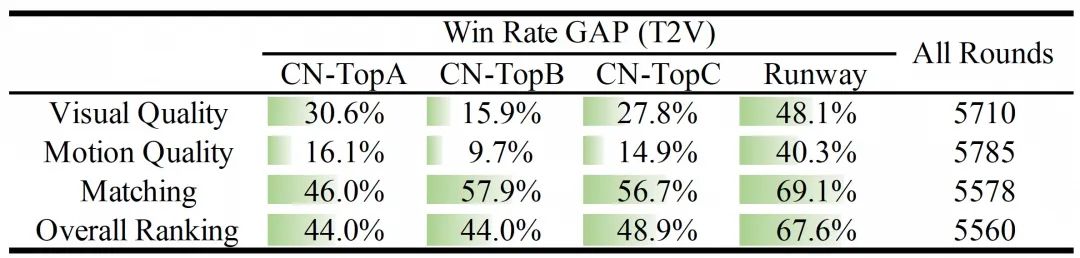
(1) 文本到视频评估
通过人工评估,提示扩展后生成的结果优于闭源和开源模型的结果。
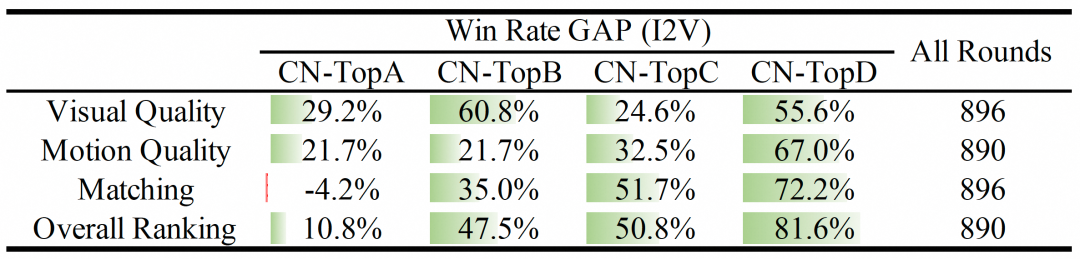
(2) 图像到视频评估
我们还进行了广泛的手动评估,以评估 Image-to-Video 模型的性能,结果如下表所示。结果清楚地表明,Wan2.1 的性能优于闭源和开源模型。
不同 GPU 上的计算效率
我们在下表中测试了不同 Wan2.1 模型在不同 GPU 上的计算效率。结果以以下格式显示:总时间 (s) / 峰值 GPU 内存 (GB)。
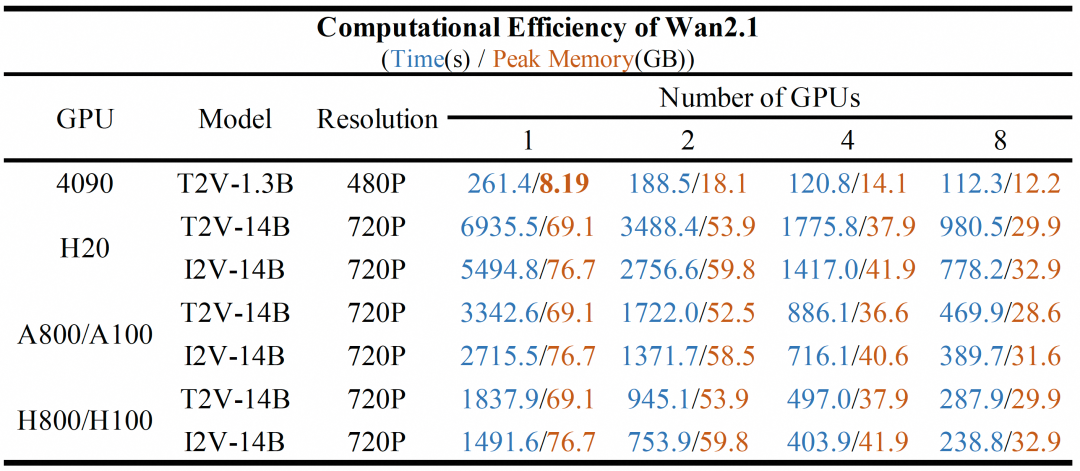
下表中所示测试的参数设置如下:(1) 对于 8 个 GPU 上的 1.3B 模型,设置
--ring_size 8和--ulysses_size 1;(2) 对于 1 个 GPU 上的 14B 模型,请使用--offload_model True;(3) 对于单个 4090 GPU 上的 1.3B 模型,设置--offload_model True --t5_cpu;(4) 对于所有测试,都没有应用提示扩展,这意味着--use_prompt_extend未启用。
💡注意:T2V-14B 比 I2V-14B 慢,因为前者采样 50 步,而后者使用 40 步。
社区贡献
- DiffSynth-Studio 为 Wan2.1 提供了更多支持,包括视频到视频、FP8 量化、VRAM 优化、LoRA 训练等。请参考他们的例子。
Wan2.1 简介
Wan2.1 基于主流的 diffusion transformer 范式设计,通过一系列创新实现了生成能力的重大进步。其中包括我们新颖的时空变分自动编码器 (VAE)、可扩展的训练策略、大规模数据构建和自动评估指标。总的来说,这些贡献增强了模型的性能和多功能性。
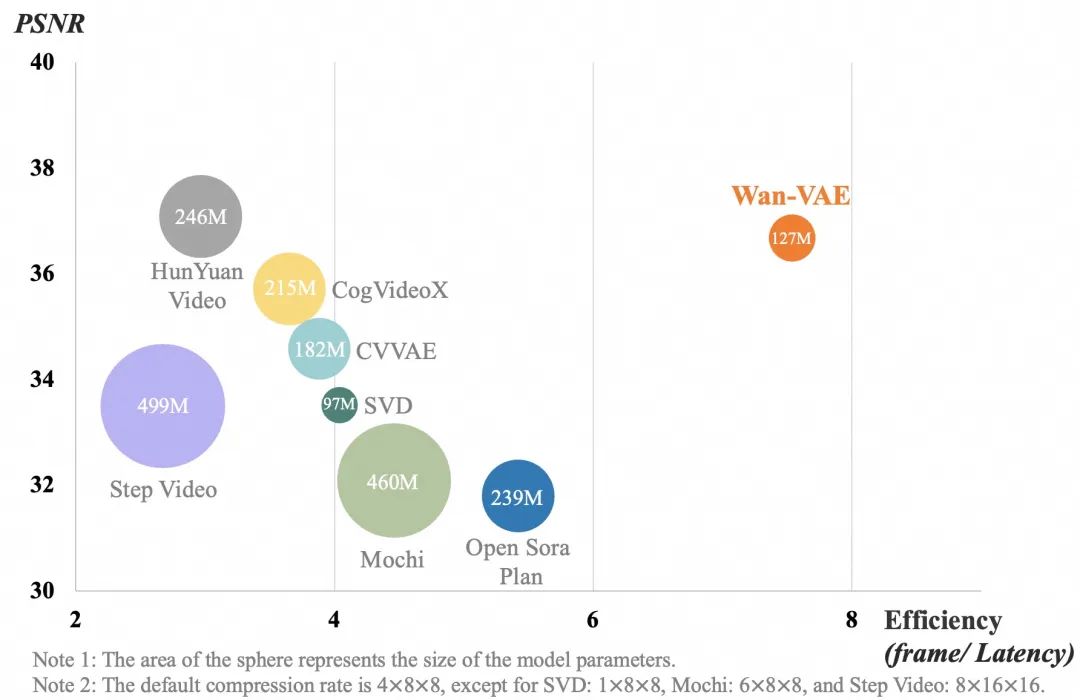
(1) 3D 变分自动编码器
我们提出了一种新颖的 3D 因果 VAE 架构,称为 Wan-VAE,专为视频生成而设计。通过组合多种策略,我们改进了时空压缩,减少了内存使用,并确保了时间因果性。与其他开源 VAE 相比,Wan-VAE 在性能效率方面表现出显著优势。此外,我们的 Wan-VAE 可以对无限长度的 1080P 视频进行编码和解码,而不会丢失历史时间信息,因此特别适合视频生成任务。
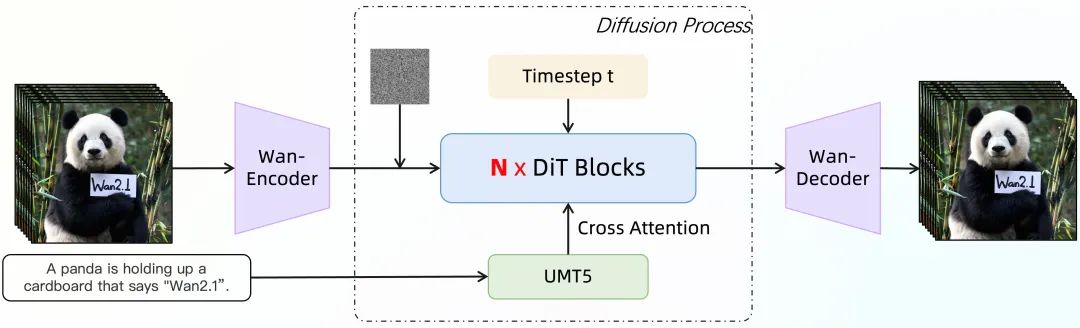
(2) 视频扩散 DiT
Wan2.1 是在主流 Diffusion Transformer 的范式中使用 Flow Matching 框架设计的。我们模型的架构使用 T5 编码器对多语言文本输入进行编码,每个 transformer 块中的交叉注意力将文本嵌入到模型结构中。此外,我们采用具有线性层和 SiLU 层的 MLP 来处理输入时间嵌入并分别预测六个调制参数。此 MLP 在所有 transformer 模块之间共享,每个模块学习一组不同的偏置。我们的实验结果表明,在相同的参数尺度上,这种方法的性能得到了显著的提高。
|
|
尺寸 | 输入维度 | 输出维度 | 前馈维度 | 频率维度 | 喷头数量 | 层数 |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据
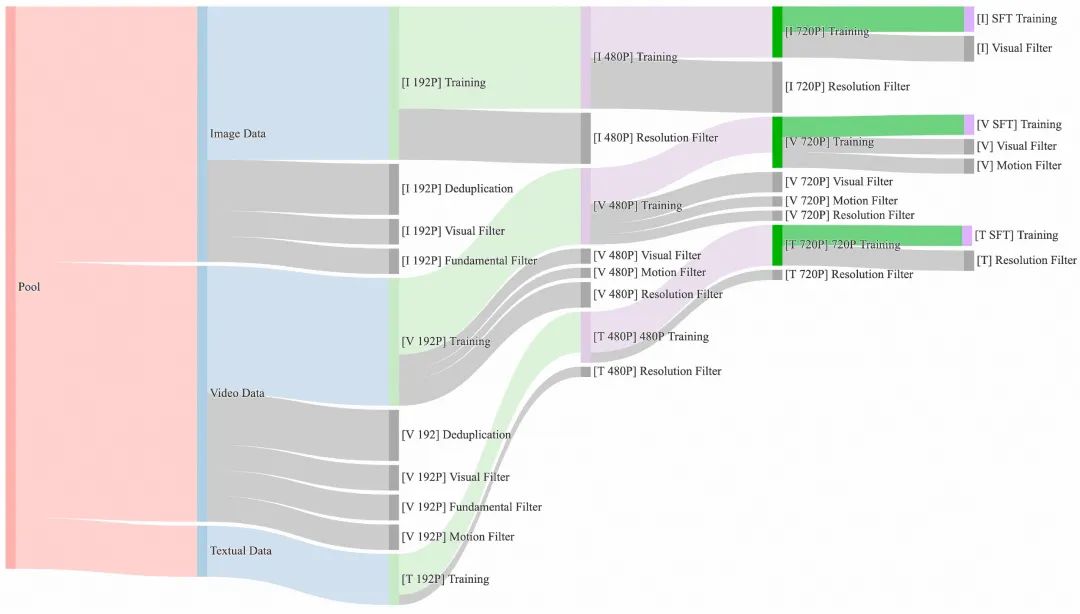
我们整理并删除了一个包含大量图像和视频数据的候选数据集。在数据管理过程中,我们设计了一个四步数据清理流程,重点关注基本维度、视觉质量和运动质量。通过强大的数据处理管道,我们可以轻松获得高质量、多样化和大规模的图像和视频训练集。
与 SOTA 的比较
我们将 Wan2.1 与领先的开源和闭源模型进行了比较,以评估其性能。使用我们精心设计的 1,035 个内部提示,我们在 14 个主要维度和 26 个子维度上进行了测试。然后,我们通过对每个维度的分数进行加权计算来计算总分,在匹配过程中利用从人类偏好中获得的权重。详细结果如下表所示。这些结果表明,与开源和闭源模型相比,我们的模型具有卓越的性能。
(文:路过银河AI)