
Datawhale分享
开源周:Day 05,编辑:Datawhale
上周五,DeepSeek 发推说本周将是开源周(OpenSourceWeek),并将连续开源五个软件库。
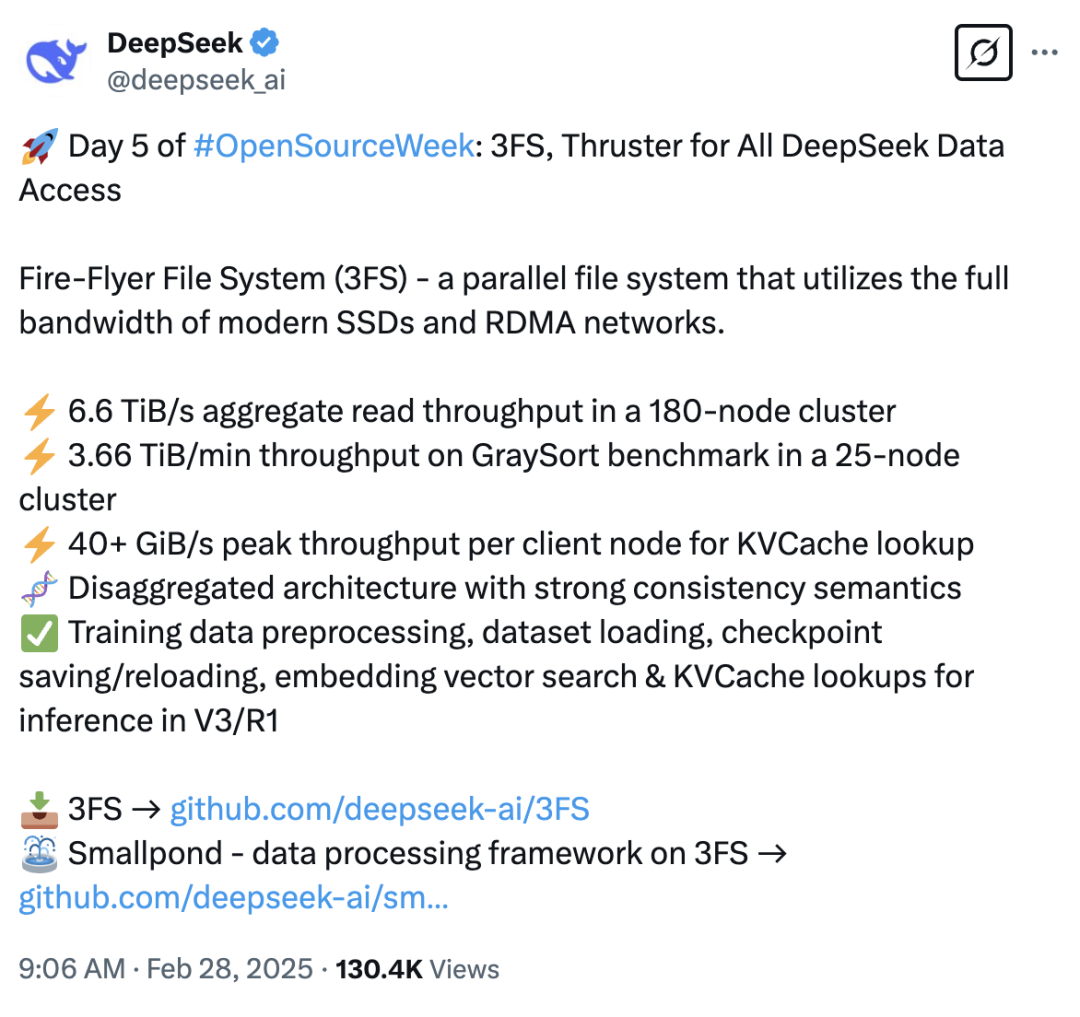
就在刚刚,开源周最后一天,DeepSeek 开源了一个名为 3FS(Fire-Flyer File System)的系统。
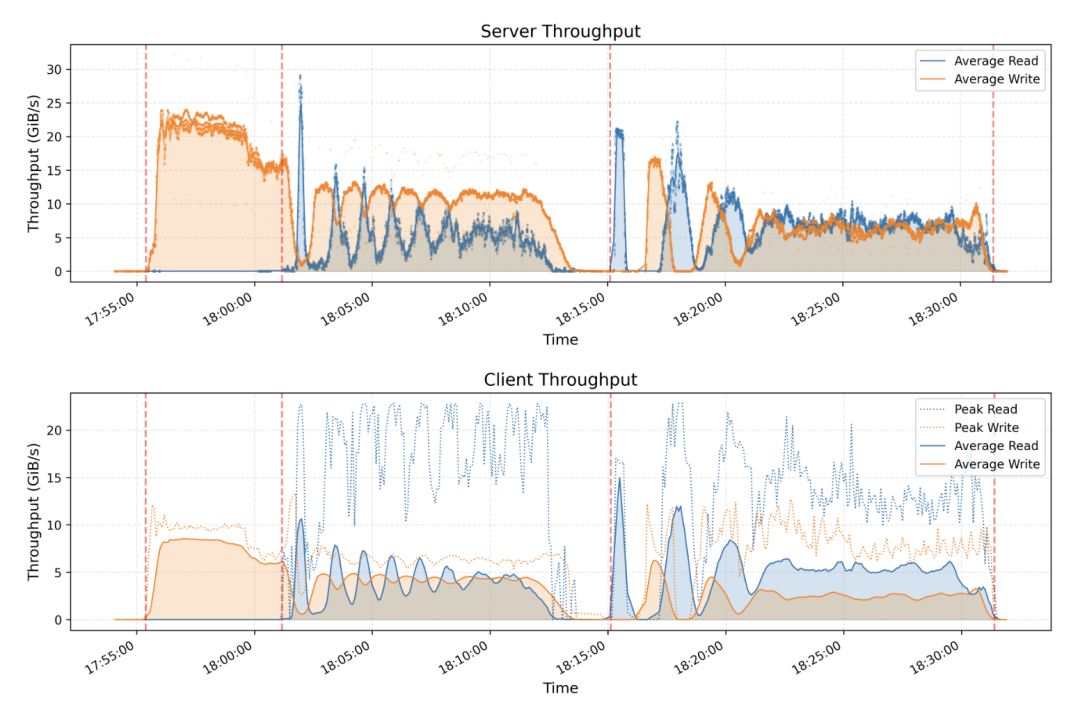
这是一种并行文件系统,它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,能够加速和推动 DeepSeek 平台上所有数据访问操作。
-
开源链接:https://github.com/deepseek-ai/3FS
-
Smallpool(3FS 上的数据处理框架):https://github.com/deepseek-ai/smallpond
通俗理解3FS
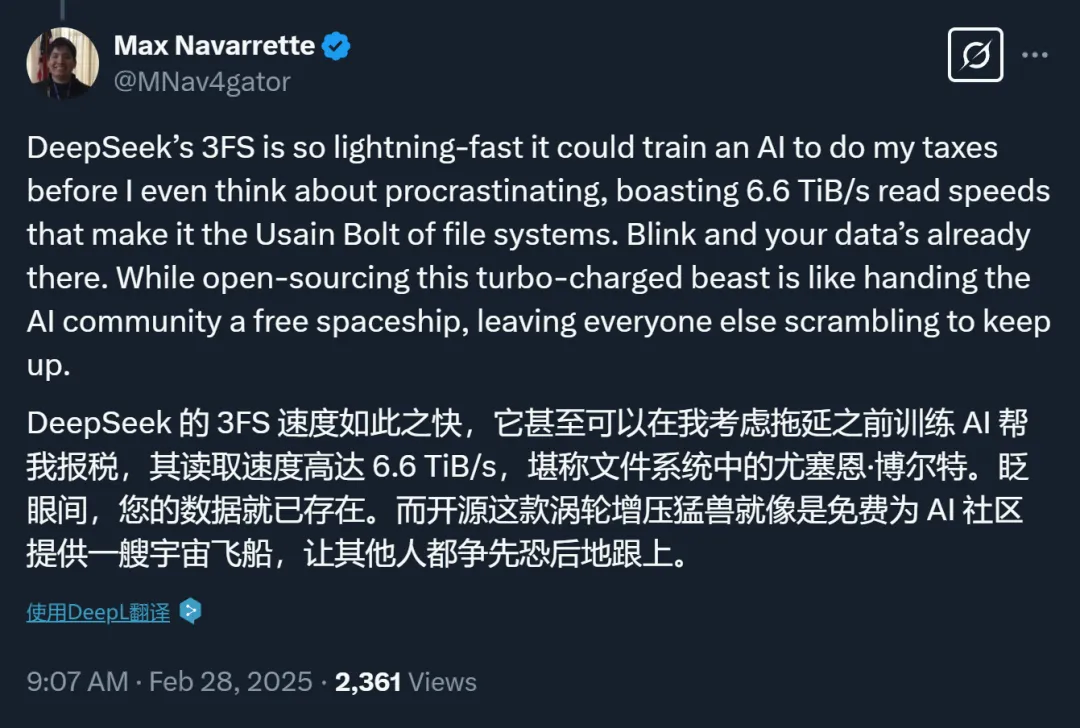
同时,这位研究者也是一位早期使用者。
他评价说:DeepSeek 的 3FS 系统快得惊人,它处理数据的速度快到可以在我还没来得及拖延的时候就已经训练好了一个能帮我报税的 AI。它拥有 6.6 TiB/s 的读取速度,这使它成为文件系统界的『博尔特』。你眨眼的功夫,数据就已经处理完毕了。而将这个超级快速的系统开源,就像是给整个 AI 社区免费赠送了一艘宇宙飞船,让其他所有竞争者都不得不加紧脚步追赶。
DeepSeek官方文档解读
-
分离式架构。结合了数千个 SSD 的吞吐量和数百个存储节点的网络带宽,使应用程序能够以不受位置限制的方式访问存储资源。
-
强一致性。实现了带有分配查询的链式复制(CRAQ)以保证强一致性,使应用程序代码简单且易于理解。
-
文件接口。开发了由事务性键值存储(如 FoundationDB)支持的无状态元数据服务。文件接口广为人知且随处可用。无需学习新的存储 API。
-
数据准备。将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
-
数据加载器。通过支持跨计算节点对训练样本的随机访问,消除了预取或打乱数据集的需求。
-
检查点保存。支持大规模训练的高吞吐量并行检查点保存。
-
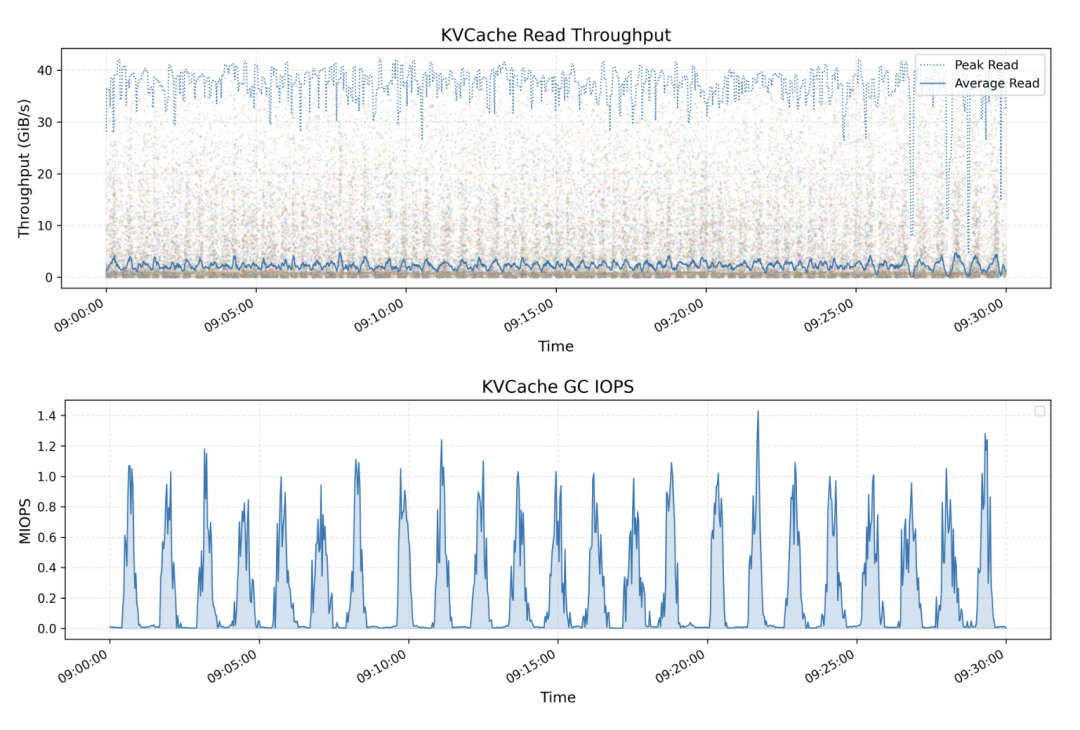
用于推理的 KVCache。为基于 DRAM 的缓存提供了一种成本效益高的替代方案,提供高吞吐量和显著更大的容量。
DeepSeek开源周正式完结

 一起“点赞”三连↓
一起“点赞”三连↓(文:Datawhale)