
TL;DR
大概两周前写了一篇文章《谈谈微信+DeepSeek》对推理性能的上界进行了一个估计基本上单卡在并行策略恰当时能够做到1800~3000个tokens.
昨天DeepSeek公布了《DeepSeek-V3 / R1 推理系统概览》[1]中, 对于 decode 任务,输出吞吐约 14.8k tokens/s。折合成每卡也就是1800个token/s, 和前面分析的预期是符合的, 至少没有像某些专家那样出现数量级的错误.
这一周的项目读了一部分代码,除了respect就没别的词了, 我有点不太明白为什么有的人不懂得去欣赏, 反而同行相轻. 我这几天一直处在自嘲的状态, 天天都跟同事说, 我被DeepSeek虐成 Shallow Beg了..
估计唯一能够和幻方打成平手的是A股的量化, 感谢大A给我一个机会证明自己不那么蠢.
谈谈EP并行
回到正题, 今天DeepSeek开源了整个推理方案变得非常显学了, 其实在一个月前工业界还是不那么清晰的, 毕竟很多团队都是在做Dense模型推理的, 或者又一些粗粒度的MoE模型推理的经验, 对于DeepSeek这样的细粒度的MoE是没有很多经验的.
大概在春节后, 各个团队都在忙着优化DeepSeek-R1推理的时候, 我就在建议必须要大规模的EP并行来打散并增加Batch构建跨机的EP并行, 然后为了解决跨机并行的RDMA通信问题需要引入IBGDA维持CUDA Graph并降低延迟, 同时利用WarpSpecialization来做一些overlap. 两个月前DeepSeek-V3论文发布的时候,就在脑补代码的实现, 而如今看到DeepEP的代码后, 会心的微笑基本上的实现都猜对了.
《分析一下EP并行和DeepSeek开源的DeepEP代码》
当然这里又有另一种声音, 认为这样的EP并行成为做大ScaleUP的关键, 实际上的关键因素并不是延迟和带宽. 考虑到成本因素和可靠性因素, 我并不是很认同这样的方式, 毕竟以前Cisco在这条路上死过一次了, 那么为什么不在ScaleOut做LD/ST呢? 几个月前就写过为什么不能在ScaleUP做RDMA, 其实是一个对偶的问题.
《HotChip2024后记: 谈谈加速器互联及ScaleUP为什么不能用RDMA》
大规模的ScaleUP的可靠性和技术成熟度还是有很大的问题的, Nvidia GB200 NVL72的难产就证明了这样一个判断. 另一方面ScaleOut做LD/ST也是非常成熟干净的一种方式, 大概在2021年的NetDAM就实践过了. 而且这个判断正好契合DeepSeek-V3论文对未来硬件架构的建议.

其实IB-NVLink-Unified domain也应证了这样一句话,既然ScaleUP无法做RDMA,那么必然在ScaleOut做LD/ST.
回到正题上来, DeepEP中的PTXld.global.nc.L1::no_allocate这个操作做GPU和网络处理器微架构的人时间长了基本上都能想到, 而DeepGEMM中的yield bit真的是令我非常震撼, 工作做的太细致了. 然后DeepEP中的对于memory order的应用也非常的细致, 只能躺地上举双手双脚的点赞.
另外FlashMLA从发布到集成到vLLM就几天时间, 性能提升2%~16.8%, 但是DeepGEMM和FlashMLA的代码这周还没有太多的时间去阅读, 后面找时间再来补作业吧.
谈谈分布式存储
最近两天在做3FS的分析, 这是一个我几年前就关注的项目了, 因为都是做量化交易的同行, 深知行情tick数据快速存储和读取的重要性. 这对高频交易商是非常重要的基础设施. 昨天开源以后就很快的安装测试了一下, 做的非常不错
《基于eRDMA实测DeepSeek开源的3FS》
详细的代码分析蚂蚁存储团队也有一篇很好的文章
《DeepSeek 3FS解读与源码分析(1):高效训练之道》
180台机器,理论的带宽上限为7.2TiB/s, 实际使用能跑到6.6TiB/s非常的厉害了
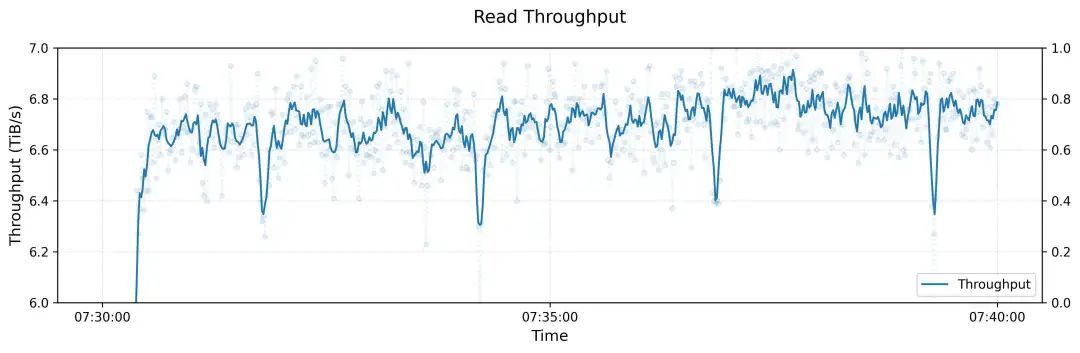
磁盘I/O的负载偏斜, 网络的拥塞等都在IB环境下解决的很好. 有一篇幻方以前的文章在减少网络拥塞上,我们的一点实践(一)[2]
其实这也是我一直的观点, 解决网络拥塞的问题,不到万不得已不要去动拓扑, 保证在FatTree结构下进行处理, DeepSeek在IB网络上通过修改OpenSM实现的, 而在RoCE上其实也有很多很巧妙的办法.
谈谈推理系统
在Day6的文章中也详细描述了整个系统的架构

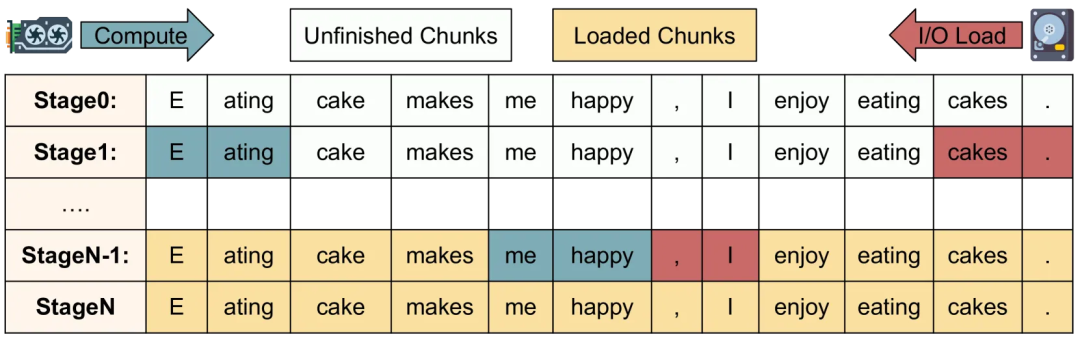
针对Prefill和Deocde都有额外的负载均衡组件, 同时专家也有EPLB的负载均衡, 然后接入到外部的KVCache服务中对于GPU故障导致的宕机服务中断也有了更好的恢复机制, 可以通过3FS的KVCache在另一个集群快速的拉取处理, 我不确定他们是否也实现了《Compute or Load KV Cache? Why not both?》采用了双向fill的机制, 从最后一个token开始倒着向前读取KV-Cache, 然后前向从第一个Token开始进行KVCache计算, 直到两个过程交汇.
集群的部署规模也比论文中的小一些, Prefill采用4个节点EP32+DP32, 而Decode集群采用了18个节点EP144+DP144, 似乎没有出现论文中说的TP4+SP.

然后从公开的trace来看overlap的真好, 唯一有点小遗憾的是没有公布decode的trace.
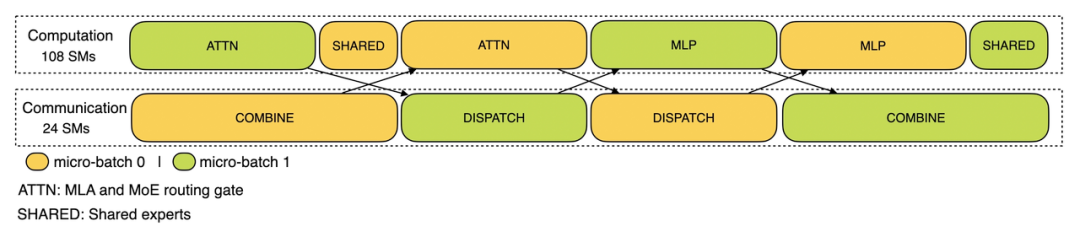

但是Decode Microbatch在DeepEP中已经看的很清楚了, 有一点怀疑为什么在online部署的时候没有采用TP, 是否因为FlashMLA不做TP的时候就和Combine花的时间一样多了?
其实这些工作背后还有一个没有开源的项目haiprof 在文章GTC 2023 | 按需分配的AI算力 Ⅱ[3]有过介绍.
haiprof (High-flyer’s AI Profile)[4] 是一个针对 PyTorch 模型的性能分析工具,用户能够在无需修改代码的情况下分析模型性能瓶颈,能随时调用,为整个训练过程做全方位的“CT”。 正是这样的工具辅助, 我想他们才会极致的在每一个环节去优化性能.
对于算子的优化hfai.nn[5]也有很多年的积累了, 整个infra团队太强了.
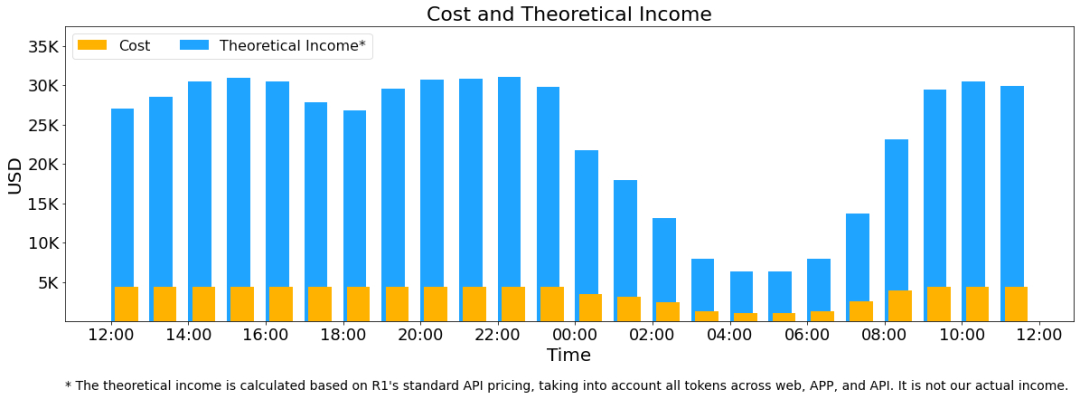
最后的一些统计和利润的计算实实在在的打了脸, 也向国外证明了真的不需要5w张卡, 只需要266台 2128张卡就可以服务2000万的DAU了, 当然这个说法也是不完全正确的,毕竟现在还是非常卡顿的经常请求失败. 最后的利润表或许又要引起一场价格战了….
谈谈未来MoE
最后其实还有更多的反思, 关于细粒度的MoE模型和Infra做了太多的协同设计, 特别是在V3上通过Group-Gating来约束通信的设计上. 当然另一方面这样细粒度的MoE虽然在算力上大幅度降低, 但也把压力转移到了网络和显存带宽上, 并由此开启了一个分布式推理的时代. 这样的Trade-off我相信肯定是在模型和Infra上做了大量的协同设计取舍而得到的, 而不是单单的一个算法出来之后Infra在后面擦屁股调优. 当然在这样的Trade-off下对于互联也带来了更多的压力, 这也是DeepSeek-V3论文中提出对未来硬件需求的点, 毕竟DeepEP的实现受到硬件的约束还是很复杂的.
其实针对MoE的通信优化, 我在2023年就已经完成了很多算法的分析, DeepEP的这些手段很早就已经分析过, 包括V3论文提到的一系列的offload和避免L1/L2Cache的占用等, 当时就在做一个极限的1024选64这样细粒度专家对通信需求的推演.
只是当时赶不上CIPU2.0的流片时间,选择了先把网络拥塞控制incast和多路径转发的能力放入芯片, 而这些能力今天您也可以看到在云上几分钟开启一个3FS集群成为了可能, 并且无需考虑任何网络拥塞带来的影响, 无需考虑虚拟机位置放置的影响, 然后没有因为多路径而放弃对RC的支持, 使得今天在eRDMA上部署3FS非常顺利,无需修改任何代码.
至于未来的事情涉及一些保密原因就不多说了…只想说超越Nvidia的网络设备是我们的本分, 大家一起加油~
DeepSeek-V3 / R1 推理系统概览: https://zhuanlan.zhihu.com/p/27181462601
[2]
在减少网络拥塞上,我们的一点实践(一): https://www.high-flyer.cn/blog/network-1/
[3]
GTC 2023 | 按需分配的AI算力 Ⅱ: https://www.high-flyer.cn/blog/gtc2023/
[4]
haiprof | 模型训练性能分析工具: https://www.high-flyer.cn/blog/haiprof/
[5]
hfai.nn: https://www.high-flyer.cn/blog/hfnn/
(文:GiantPandaCV)