
来自阿里巴巴通义实验室、中国科学技术大学和上海交通大学的最新研究成果——ViDoRAG(Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents),通过创新的多智能体框架和动态迭代推理机制,为视觉丰富文档检索增强生成(RAG)提供有效解决方案。

论文地址:https://arxiv.org/abs/2502.18017
Github地址:https://github.com/Alibaba-NLP/ViDoRAG
数据集地址:https://huggingface.co/datasets/autumncc/ViDoSeek
为了解决现有RAG方法在处理视觉丰富文档时面临的挑战,尤其是检索阶段无法有效整合文本和视觉特征,以及生成阶段推理能力不足的问题,我们提出了ViDoRAG框架。ViDoRAG通过引入基于高斯混合模型(GMM)的多模态混合检索策略,以及多智能体迭代推理机制,显著提升了模型在视觉丰富文档上的检索和推理能力,为相关领域的研究提供了新的思路和方法。
与此同时,我们注意到现有数据集仅聚焦于单张图片或单个文档的问答任务,缺乏在大规模文档集合情景下针对检索和复杂推理能力的系统性评估。为弥补这一空白,我们提出了ViDoSeek 数据集。该数据集专为视觉丰富文档的检索-推理-回答任务设计,旨在为大规模文档集合的检索和生成能力评估提供一个更具挑战性和实用性的基准。ViDoSeek 的推出,不仅为 ViDoRAG 框架的验证和优化提供了有力支持,更为未来相关研究提供了一个高质量的基准,推动视觉文档问答领域的进一步发展。
🌟 ViDoSeek Benchmark:专注于大规模数据文档集合下的检索和复杂推理
为精准评测 RAG 在视觉文档处理上的性能,我们精心打造了 ViDoSeek 数据集。这并非传统意义上简单的图像问答或文档问答集合,而是一个专为大规模文档检索、复杂推理与精准问答设计的综合性评估。在 ViDoSeek 中,每个查询都指向大型文档集合中的唯一答案,并配有明确的参考页面标注,涵盖了文本、图表、表格、布局等多种内容类型,完美模拟真实世界中多样化的文档场景。
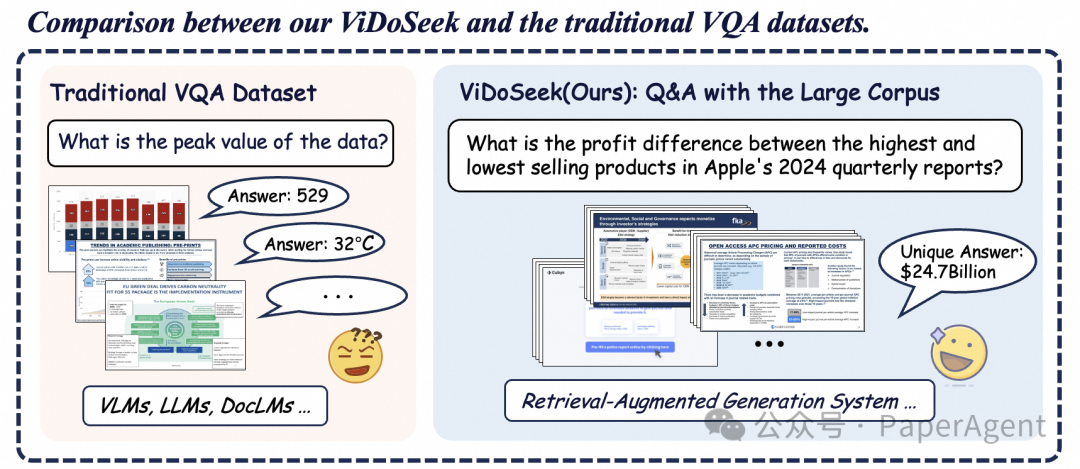
ViDoSeek 汇聚了约 1200 个精心设计的问题,覆盖了文本、图表、表格和二维布局等多种内容类型。每一个问题都能在大规模文档集合中找到唯一的答案,并且配有明确的参考页面标注。这使得 ViDoSeek 不仅能够评估模型的检索能力,还能全面考察其在大型文档集合情境下的推理和理解能力。
ViDoSeek 对问题类型进行了细致划分,单跳推理问题要求模型从单一信息源中直接获取答案,而多跳推理问题则需要模型在多个文档或信息片段之间建立联系,进行深层次的推理和整合。这种复杂性要求整个系统不仅要具备精准的检索能力,还要能够有效地整合和分析来自不同文档的信息。
这种设计不仅增加了数据集的挑战性,也为模型的推理能力提供了全方位的试炼场,从而对 RAG 系统的综合能力提出更高要求。这种对复杂文档结构和内容的深度把控,正是 ViDoSeek 的独特魅力所在,它为 RAG 系统提供了一个贴近实战的演练场,让模型在 “真刀真枪” 的考验中锤炼能力。
🚀 ViDoRAG:多智能体迭代推理,开启类人思考新范式
我们进一步提出了ViDoRAG,一个针对视觉文档复杂推理的多智能体RAG框架。相比于传统的RAG框架,ViDoRAG的核心在于其多模态混合检索策略和多智能体生成流程。这些特性使得ViDoRAG在处理视觉文档时如鱼得水,能够更加精准地检索、理解和生成答案。

多模态混合检索:打破视觉与文本的隔阂
在处理视觉文档时,传统的RAG方法往往面临着一个棘手的问题:如何有效地整合视觉和文本信息。纯视觉检索方法虽然能够捕捉到图像中的关键信息,但在理解文本内容时却显得力不从心;而纯文本检索方法则在处理视觉信息时存在天然的局限性。这种割裂的检索方式,不仅导致了检索结果的不准确,也限制了模型对文档的全面理解。
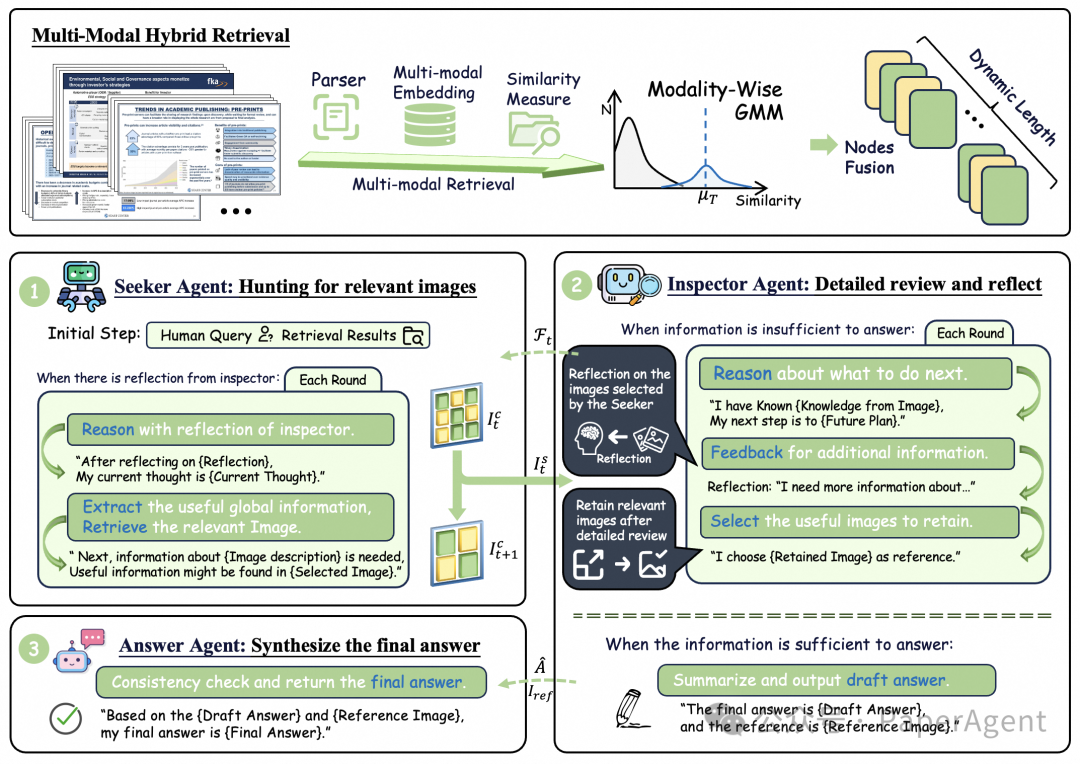
为了解决这一问题,ViDoRAG提出了多模态混合检索策略。这一策略的核心在于将视觉和文本特征进行有机结合,通过高斯混合模型(GMM)动态调整检索结果的分布。**具体来说,ViDoRAG首先分别通过视觉和文本管道进行信息检索,然后利用GMM模型对检索结果进行融合。GMM模型能够根据查询与文档集合之间的相似度分布,自动确定每个模态的最优检索数量。**这种方法不仅提高了检索的准确性,还减少了不必要的计算,使得模型能够更高效地处理大规模文档集合。
多智能体迭代推理:开启类人思考新范式
在检索到相关信息后,如何生成准确且全面的答案,是RAG系统的另一个关键挑战。传统的RAG方法在生成答案时,往往缺乏足够的推理能力,尤其是在处理复杂推理任务时,容易出现答案不准确或不完整的问题。为了解决这一问题,ViDoRAG引入了多智能体生成流程,通过模拟人类的推理过程,逐步提炼出最终的答案。
ViDoRAG的多智能体生成流程包括三个智能体:探索者(Seeker)、检查员(Inspector)和回答者(Answerer)。探索者负责从粗略的视图中选择相关的图片,基于查询和检查员的反馈,逐步筛选出最相关的图片。检查员对探索者选择的图片进行详细审查,提供反馈或初步答案。如果当前信息足以回答查询,检查员会提供一个草稿答案和相关图片的引用;如果信息不足,检查员则会指出需要进一步获取的信息,并保留相关图片以供后续审查。回答者在最终步骤中,验证检查员草稿答案的一致性,并根据参考图片和草稿答案,给出最终答案。
这种多智能体的协作方式,不仅提高了生成答案的准确性,还使得整个过程更加高效。通过模拟人类的推理过程,ViDoRAG能够更好地处理复杂的视觉文档任务,生成更加准确和全面的答案。
🛠️ 实验与分析
在实验中,研究者们采用了多种模型进行端到端评估,评估指标主要为准确率,通过 GPT-4o 对参考答案和最终答案进行比较打分。实验结果显示,ViDoRAG 在 ViDoSeek 基准测试中表现出色,显著优于现有的方法。例如,在 GPT-4o 模型上,ViDoRAG 的准确率达到了 79.4%,比传统 RAG 方法提高约10%以上,这一结果充分证明了 ViDoRAG 框架的有效性和优越性。
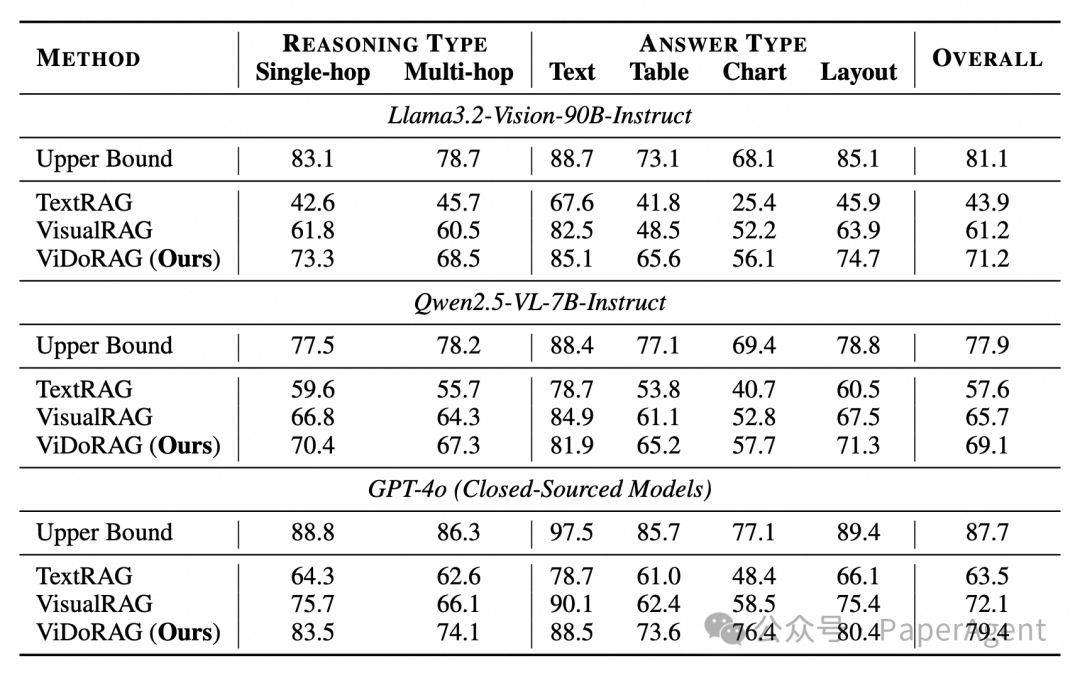
在检索性能方面,ViDoRAG 的动态检索策略展现了显著的优势。通过 GMM 动态确定检索文档数量,不仅提高了检索的准确性,还为生成阶段减少了不必要的计算开销。这种动态调整机制使得 ViDoRAG 能够更加高效地处理大规模文档集合,进一步提升了模型的性能和效率。

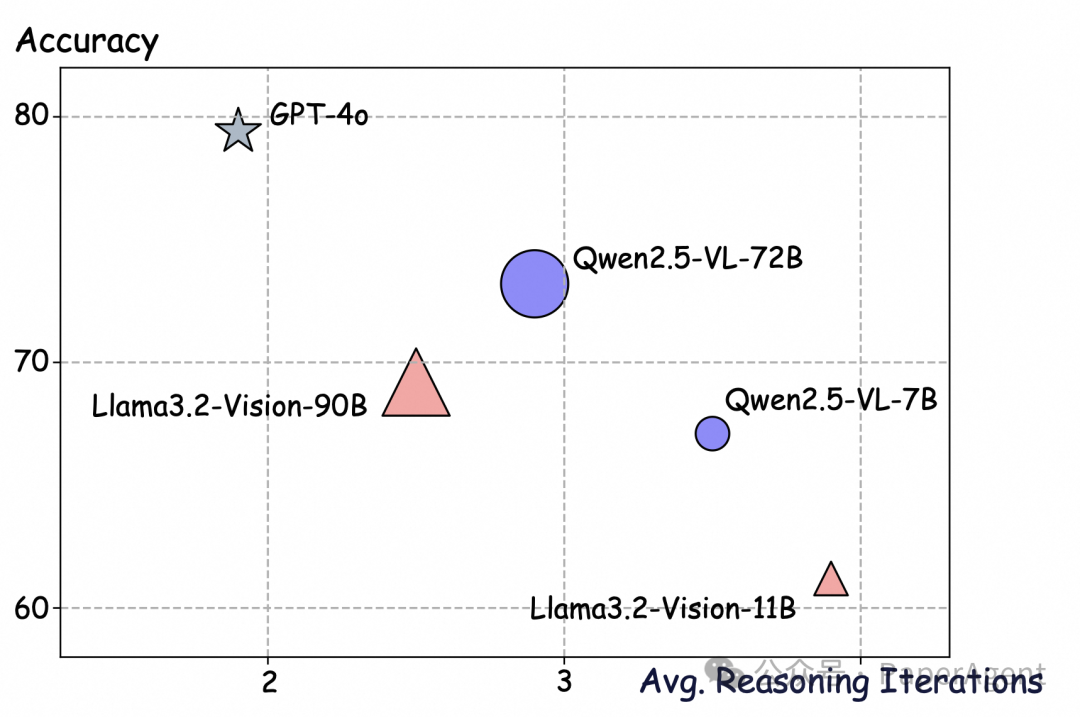
研究者基于ViDoRAG 验证了其Test-Time Scaling。研究发现,在 ViDoRAG 框架下,不同模型的交互轮次存在明显差异:性能更强的模型由于其出色的推理能力,能够更快地理解任务需求并生成高质量的答案,因此所需的推理迭代次数更少;而性能相对较弱的模型则需要更多的推理迭代次数,通过逐步积累信息和调整思路,最终才能生成较为准确的答案。这种差异表明 ViDoRAG 能够根据模型的性能特点,灵活地调整推理过程,从而在不同模型上都能实现较好的效果。
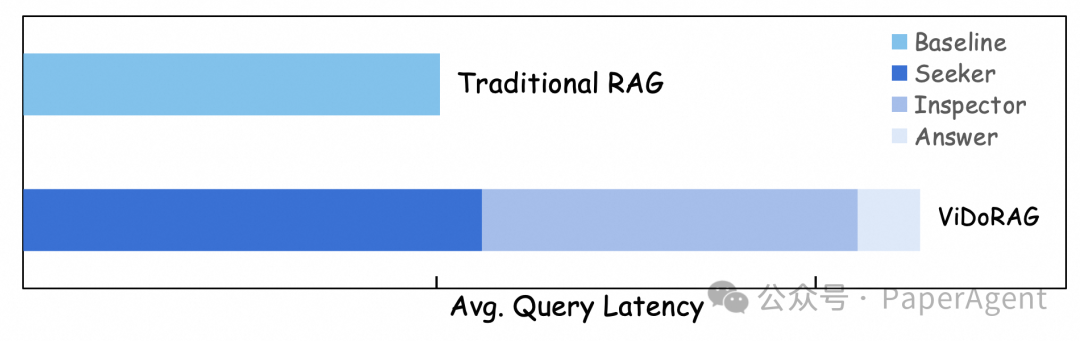
在时延分析中,由于多智能体系统的迭代特性,ViDoRAG的延迟相较于传统RAG有所增加。具体来说,每个智能体依次执行特定任务,这虽增加了时延,但生成答案的质量却显著提升。因此,在复杂RAG任务中,这种延迟与准确率之间的权衡是值得的。
📚总结和展望
ViDoRAG 的提出,为大规模视觉文档集合的检索增强生成提供了一条全新的路径。凭借创新的多智能体框架和多模态混合检索策略,ViDoRAG 在复杂视觉文档的推理和生成能力方面取得了显著提升,同时也为未来的研究和应用指明了新方向。接下来的工作将重点聚焦于优化系统效率和减少模型幻觉,以在保持高准确率的同时,进一步降低计算成本,提高响应速度和可扩展性。这包括对多智能体框架的优化,以及更精细的检索和生成流程管理。此外,我们还将探索更加严格的验证机制和更精准的推理步骤,以确保生成的答案更具可靠性和准确性。ViDoRAG 的发展不仅推动了视觉文档问答技术的进步,也为未来 RAG 领域的研究提供了重要的参考和启示。
(文:PaperAgent)