
今天是2025年3月5日,星期三,北京,天气晴。
今天我们再来看看文档智能的一些事儿,这个也是社区的主要方向之一。
我们在文档智能专题https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzAxMjc3MjkyMg==&action=getalbum&album_id=3343154918412664836,专门有讲过很多主题工作了,大家可以去看。
最近又冒出了omlocr这个模型,我们来看看,究竟是什么?炒冷饭?
顺便梳理下目前文档解析的两个流派,pipeline派文档解析以及end2end派文档解析。
先说问题,要时效性好的且落地的,老老实实走pipeline派。想尝试下先进性的,有钱且不care速度的,可以用end2end派。
但是大家要清楚一个事情,除了技术路线上有区别,更要看应用场景,面向RAG的文档解析跟面向可编辑/格式转换的文档解析是不一样的,两者需求不同,对文档出错的容忍性也不一样,不同的需求,会导致不同的工具选型和优化目标,这个不要混淆【纵然现在很多都是乱上的】。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、pipeline派文档解析
pipeline派文档解析的核心是,不走多模态端到端,而是基于传统的路线,给定一个文档,先转为图片,然后进行版式布局分析,检测出图、表、公式、段落等,然后分别使用表格解析、公式解析,段落ocr,然后再进行阅读顺序还原等方案进行后处理,最终得到一个ocr表示,比如md。
但是呢,问题很明显,就是它是个大集成方案。这个集成呢,好处在于可以强强联合,每个组件都可以单独进行优化,或者集成开源做的比较好的,谁好用谁。坏处就是,整个流程很多,错误传播不好控制。
但是,这种方案,最难的点,其实不是集成本身,而是集成后的后处理阶段,比如扫描版本跟可编辑版本的ocr取值是不一样的,布局分析的检测框是不完整的,公式也可能是漏的,一个是找回全不全的问题,一个是识别准不准的问题,一个是串起来合不合理的问题,工作量很大。
当然,这一类工具目前有很多。最早是paddlepaddle出的ppstructure,后面ragflow也出了一套,然后就是miner-u也做了一套,其实流程都很同质化,区别就在于集成的每个模型用的是什么,以及后处理的逻辑哪个完善一些。
现在也看几个相关工具。
1、ppstructure
PP-Structure是PaddleOCR团队自研的智能文档分析系统,旨在帮助开发者更好的完成版面分析、表格识别等文档理解相关任务。
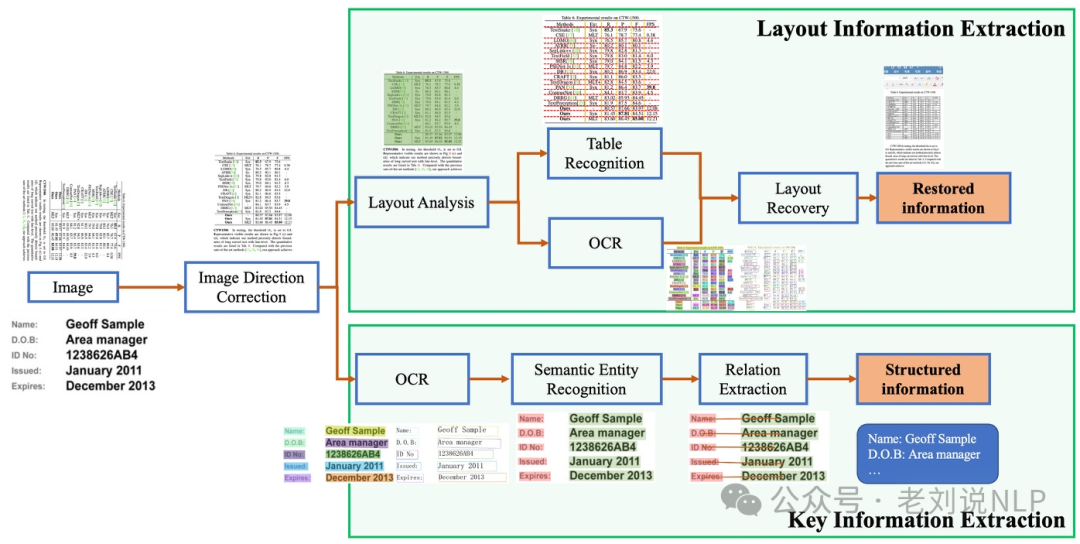
版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;
地址:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
2、miner-u
mineru,ocr用的paddlepaddle,table用的rapd-table,版式分析用的doclayout,公式用的unimernet,阅读顺序用的xycut/ layoutreader,公式检测用的yolo,然后串起来,写了很多postprocess,这就是miner-u,纯开源集成。
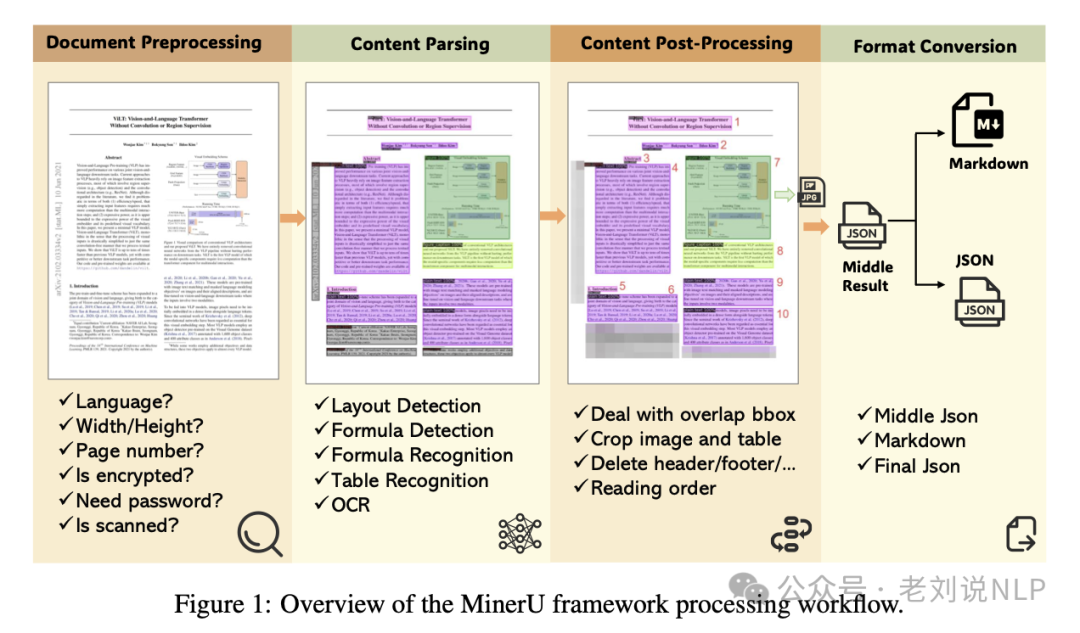
地址在:https://arxiv.org/pdf/2409.18839,https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
基于https://github.com/opendatalab/PDF-Extract-Kit,所用模型如下:
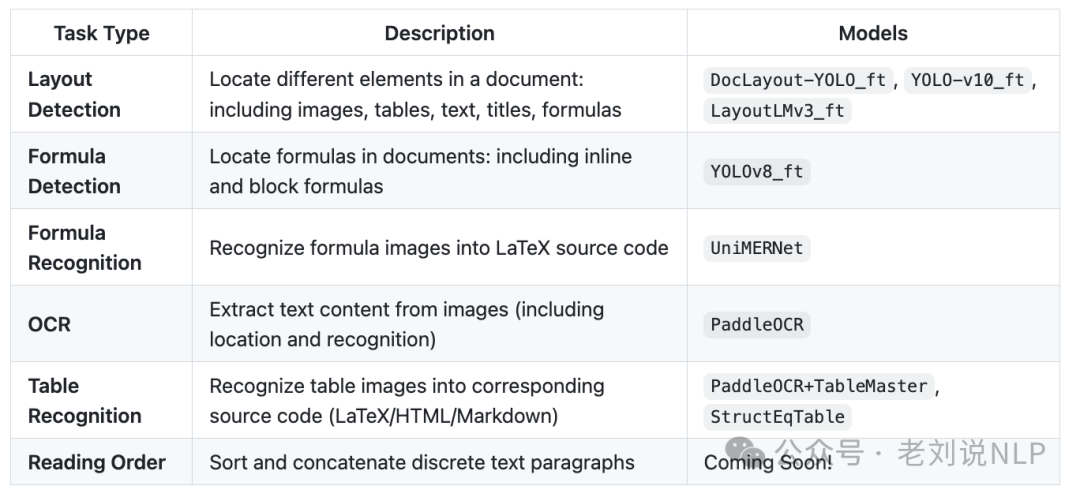
其后处理做了大量的工作,这是很难能可贵的。

一、end2end派文档解析
end2end派OCR解析的核心就是,直接一个prompt+图片,输入到一个多模态模型中,输出一个ocr解析结果。
例如,prompt是,把这个表格转换为md,输出的就是一个md表示的表格;
又如,把这个图片转换为md,输出的就是一个md表示的文档ocr结果;

这种方式就是我们常说的OCR-free的思路,在具体训练时候,就是需要构造大量的<prompt, doc_image, ocr_md>的三元组,然后选择一个多模态模型(比如qwen-vl, intern-vl, llava, phil-vl)等进行微调(lora或者full-finetune),最终得到一个OCR模型。
但是,其中的核心,包括几个:
一个数据数据层面。其实是大量的<prompt, doc_image, ocr_md>三元组的构造工作,也就是数据如何大规模挖掘出出来。比如现在找到文档-md的数据对,其实并不容易,很多都是拿arxiv的数据做的,有明显的语种偏向性,也有的使用pdfminer或者pymupdf进行转换渲染,这种渲染方式其实又存在噪声,重点还是要去洗。
一个是输入特征层面,因为模型输入的是一个文档图片,在解析文档的时候,比如一个pdf,首先是要将pdf分页,然后转换成每一页,将每一页转化为图片。但是文档图片跟一般的图片不一样,其是文档密集型,并且有布局信息,并且分辨率影响很大。在做patch切分的时候处理逻辑理想情况下是要有特殊对待。所以,根据这个前提,目前模型层面有很多可以改进的点,例如vary,觉得视觉词表跟llm的文本词表不同,所以就加了个一个词汇,一些owlplug或者monkey这些,就是在做分辨率的动态或者采样的优化,或者omlocr,将pdf的meta信息加进去做增强,这些其实更多的还是做的特征上的操作。
另一个就是模型层面,常规的范式上,模型架构都是并结合了图像编码器、线性层和解码器三个模块。在预训练阶段,首先通过纯文本识别任务来预训练视觉编码器,然后连接一个更强大的解码器来进行多任务联合训练,做对齐。在微调阶段则是使用下游任务来进行增强。所以这块的优化思路很多就是增强视觉编码器的能力,提升对更多不同文档的适应能力。
这三个层面的事情,一同决定了目前ocr-free的性能表现。这种方式呢,好处在于是足够端到端,很丝滑。但是问题很多,比如幻觉问题,比如泛化性问题,很多指标都是英文来测的,中文上表现并不是很好。还有一个,很慢,真的很慢,虽然使用vllm或者SGLang进行加速,但是在时效性很强的场景下是很难用的,并且还有卡。
但是,每次出现一个这样的工作,大家就开始各种疯转,这其实蛮不好的,因为它还是那套东西,并没有什么变化。
当然,这一类,其实出现了很多工具,我们来简单列举一下。
1、omlocr
OLMOCR,一个开源的Python工具包,用于将PDF文档转换为清洁的线性化纯文本,同时保留结构化内容如章节、表格、列表、方程式等。
相关地址:https://olmocr.allenai.org/ ,https://huggingface.co/allenai/olmOCR-7B-0225-preview,Efficient PDF Text Extraction with Vision Language Models,https://arxiv.org/pdf/2502.18443v1,code:https://github.com/allenai/olmocr。
输入端有啥特色? 用了个DOCUMENT-ANCHORING技术:通过提取页面中的文本块和图像位置信息,并将其注入到VLM的提示中,以提高内容提取的准确性,结合了文本和视觉信息,以获得更准确的文本表示。
用的啥数据?使用从超过100,000个爬取的PDF文档中提取的260,000页构建数据集。数据集包括学术文档、宣传册、法律文件等。怎么训练的?
怎么训的?在微调过程中,Qwen2-VL-7B-Instruct模型进行微调。微调过程使用Hugging Face的transformers库实现,采用AdamW优化器和余弦退火调度,使用单个节点上的8个NVIDIA H100 GPU进行训练。
怎么推理的更快? OLMOCR使用SGLang和vLLM作为推理引擎。
如果我们细想这个工作,就会有个发现,它的创新点在哪儿?其实就是,端到端模型(如Nougat)这些仅依赖图像输入,忽略PDF原生元数据,元数据就是文本块,图像这些?加进去会不好一点?所以就有了。其实之前也有,比如加入layout布局信息去做的。但是呢,可能会疑惑,就是,既然训练的时候需要图片+pdf的元数据【这个需要pdf解析一下才能拿到】。那么,推理的时候面对扫描版不就是不行了么?训推一体嘛。但是呢,不要紧,可以兼容,元数据可以置空。
2、GOT OCR2.0
GOT OCR2.0的特色是能处理多种样式的文档,能处理包括文本、数学公式、分子式、图表、乐谱和几何图形在内的多种光学字符。

地址在:https://github.com/Ucas-HaoranWei/GOT-OCR2.0,https://huggingface.co/stepfun-ai/GOT-OCR2_0,https://arxiv.org/pdf/2409.01704
3、vary
文档OCR、视觉定位、图像描述、视觉文答。比较早期的工作。
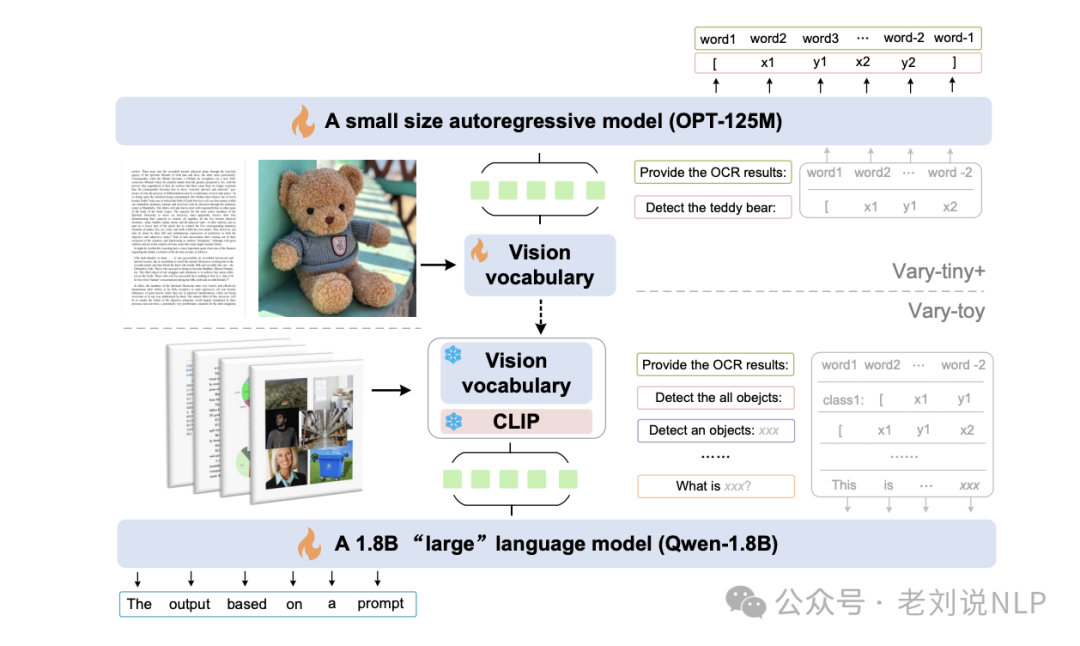
地址在:https://varytoy.github.io/,https://arxiv.org/abs/2401.12503,https://vary.xiaomy.net/,https://github.com/Ucas-HaoranWei/Vary-toy
总结
本文主要回顾了两类文档解析的路径,每种方案都很有各自的长处和不足。冷饭一直在炒,但是呢,不变的还是在那儿,咱们自己去试。
(文:老刘说NLP)