


新智元报道
新智元报道
【新智元导读】AI研究智能体全新升级!Meta等推出MLGym,一个专门用于评估和开发LLM智能体的Gym环境。MLGym提供了标准化的基准测试,让LLM智能体在多任务挑战中展现真正实力。

-
引入了MLGym,这是首个用于评估和开发AI研究智能体的Gym环境。
-
发布了MLGym-Bench,一套用于评估LLM智能体的开放式AI研究任务。
-
提出了一种新的评估指标,用于在各种任务上比较多个智能体。
-
在MLGym-Bench上对前沿LLM进行了广泛的评估。

MLGym:AI研究的全新方案
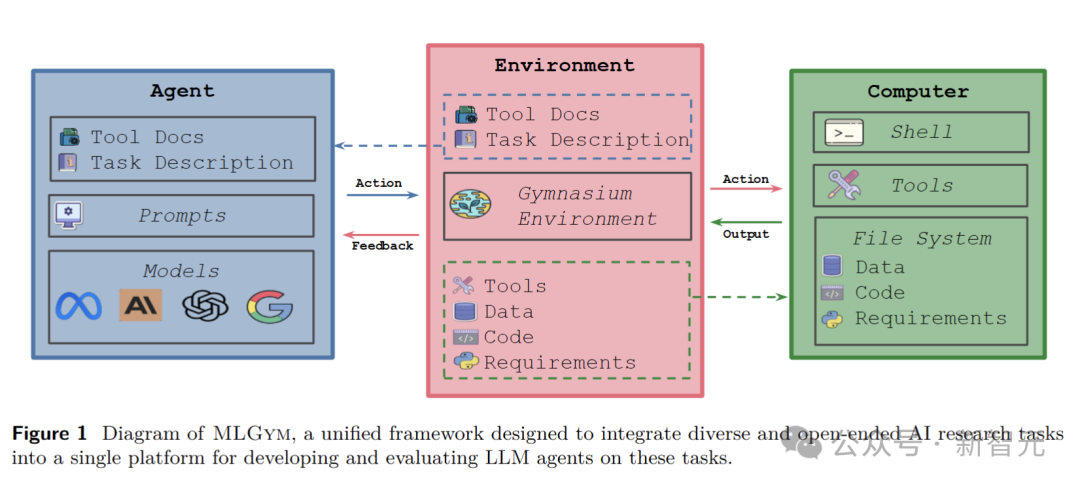
智能体
环境
数据集
任务
工具和代理-计算机接口(ACI)

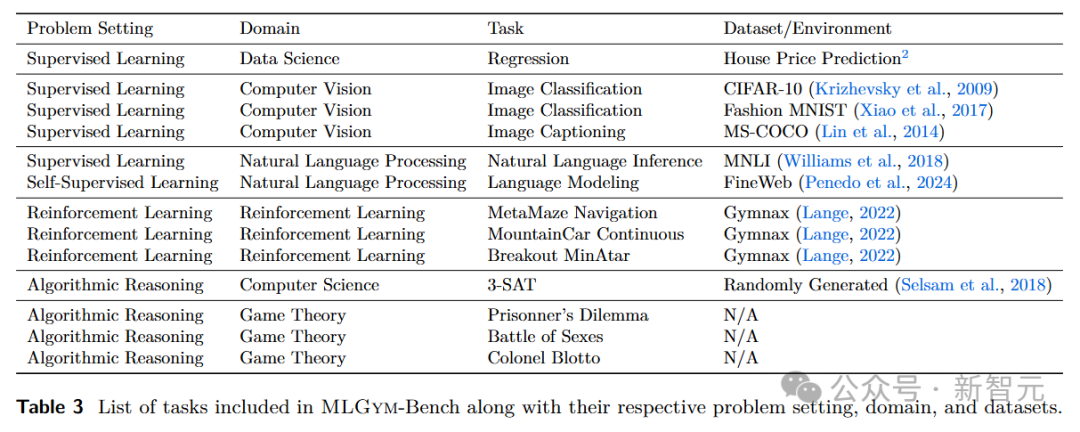
MLGym-Bench基准测试
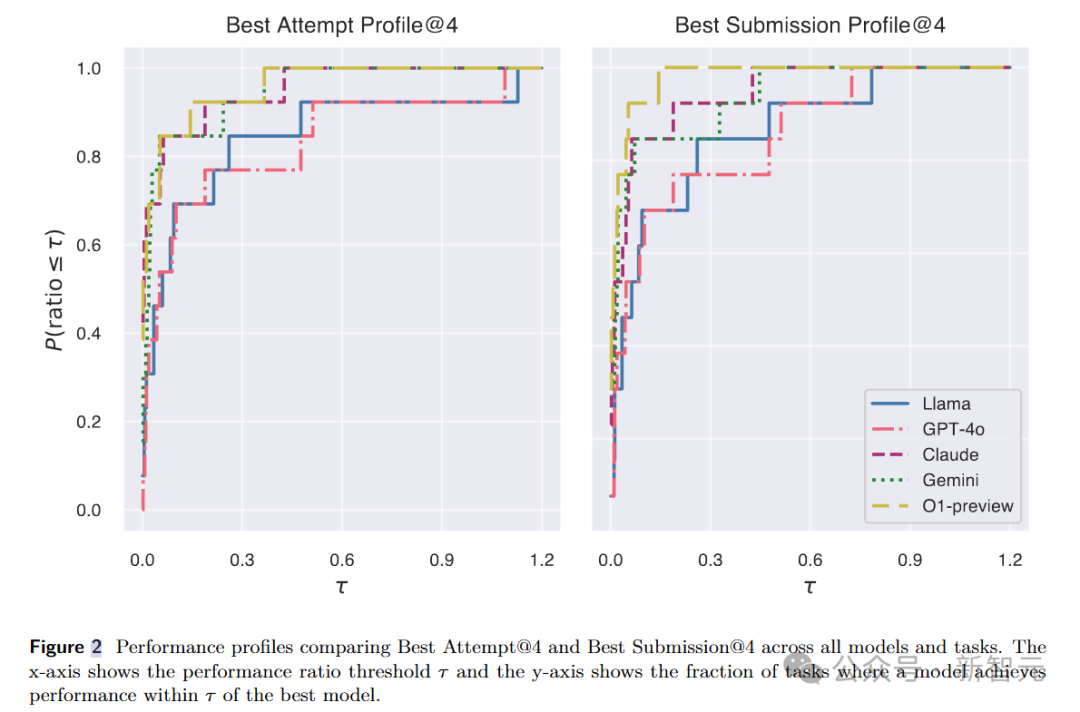
MLGym实验结果
性能排名
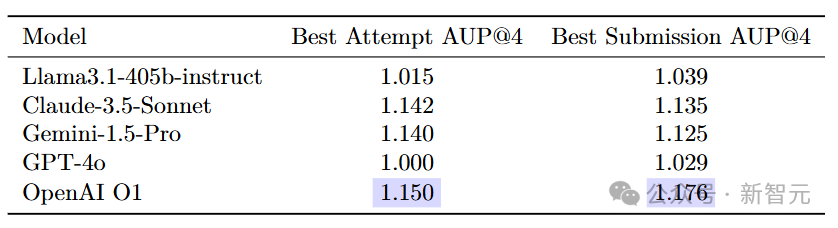
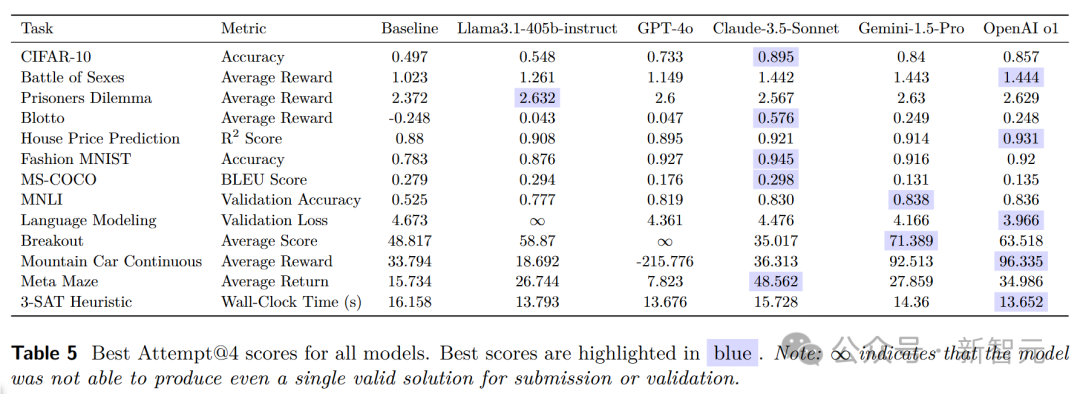
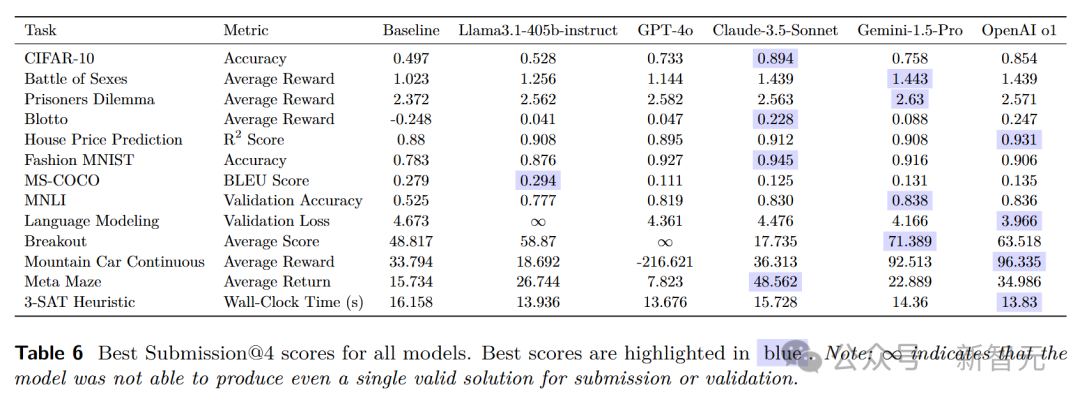
原始性能分数
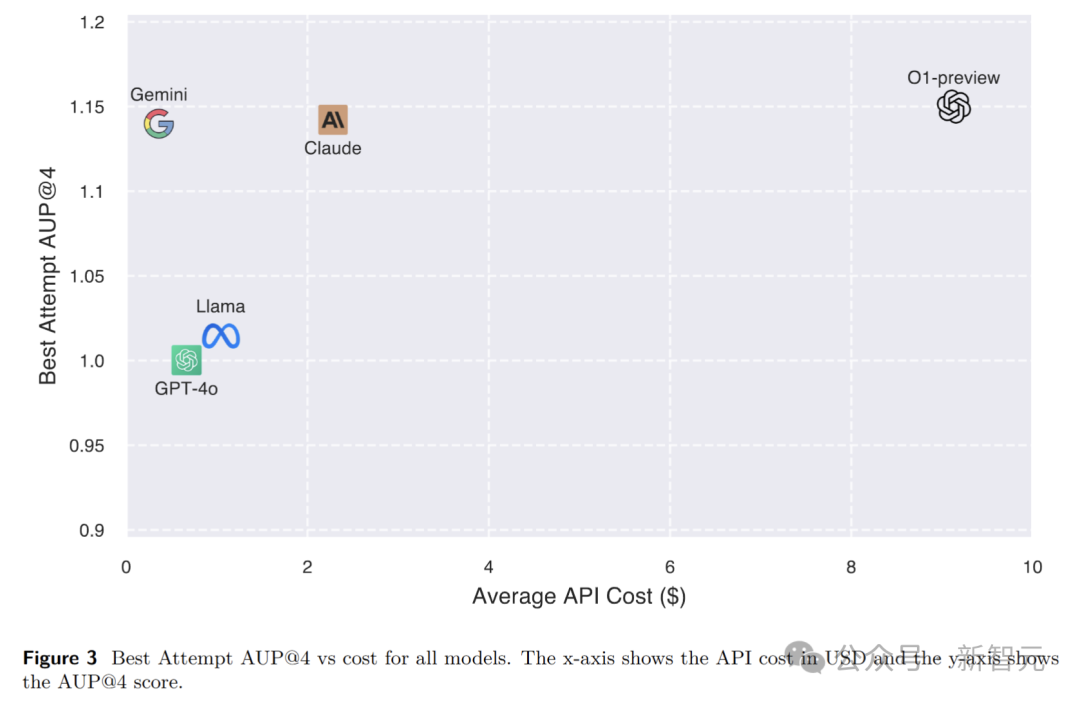
计算成本
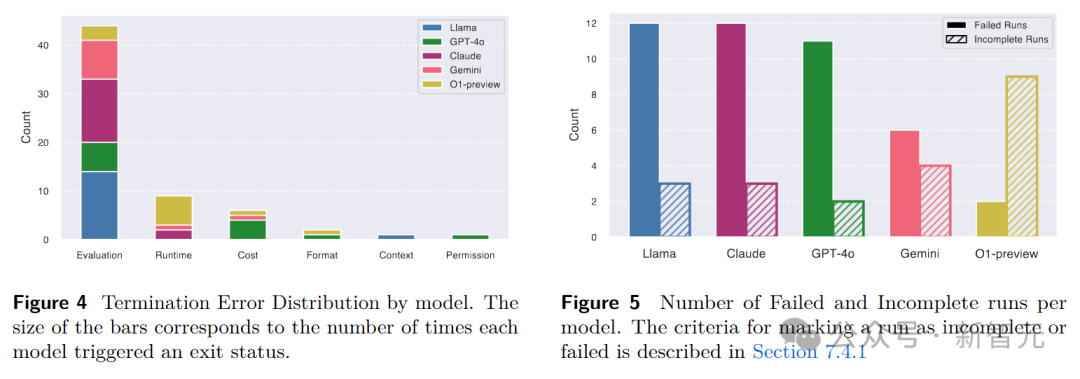
智能体行为分析
(文:新智元)