

新智元报道
新智元报道
【新智元导读】历史上首个能通过双盲同行评审的AI系统Carl诞生了。它是Autoscience研究所的成果,能完成从构思到展示的整个研究过程,撰写的论文已被国际顶会ICLR接受,其能力令人惊叹。
AI自己写的论文也能通过顶会的评审了?历史上首个能通过双盲同行评审的AI系统Carl,出现了。
Carl撰写的研究论文已被国际顶会ICLR的Tiny Papers赛道接收。关键是,这些论文几乎全由Carl生成,人工干预非常少。
这个Carl到底是何方神圣?

博客链接:https://www.autoscience.ai/blog/meet-carl-the-first-ai-system-to-produce-academically-peer-reviewed-research
认识Carl
Carl是一个新成立的研究所Autoscience的研究成果。
他们希望通过自主AI研究彻底改变AI科学领域,目标是构建一个能够完成整个研究周期——从构思到展示——并能通过同行评审的系统。正是基于这一愿景和目标,他们开发了Carl。
给定一个研究方向和一些基础文献,Carl可以提出科学假设、实施实验并撰写论文,且人类干预的程度非常有限。
Carl可以访问所有公开的科学文献,进行构思、假设、引用,并在庞大的科学文献库中建立联系。
它能够在几秒钟内阅读和理解已发布的论文,并且可以全天候监控正在进行的研究项目,及时修正出现的错误,从而加速研究周期,减少实验成本。
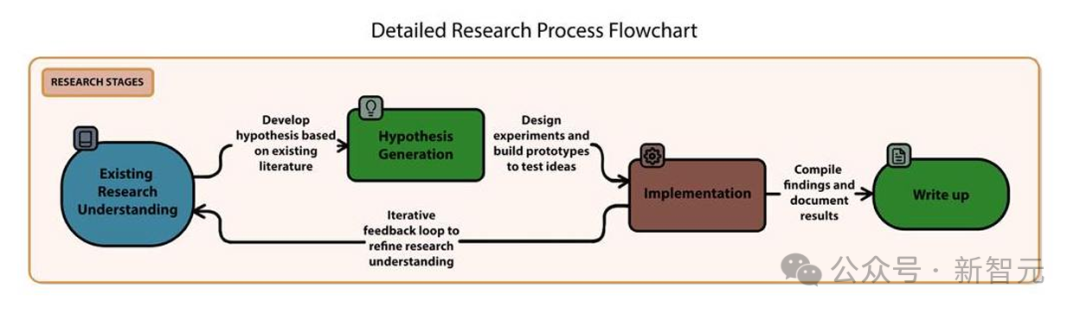
Autoscience采用了三阶段方法来构建Carl的自主AI研究系统:
-
构思阶段:从以往的研究出发,Carl识别潜在的研究方向并提出假设。最终,Carl的任务是为测试假设设计一个连贯的研究方法。该方法的设计受到一定计算资源要求的约束,且不涉及收集人类数据。 -
执行阶段:Carl通过编写代码来实现其研究方法,测试研究假设。在这一阶段,系统获得一个沙箱环境,允许其在最多5天内使用配备A100 80GB GPU的计算资源执行代码。这限制了Carl能够执行的方法,必须符合计算资源的限制。Carl还可以查询OpenAI、Huggingface和其他常见机器学习平台的付费API。 -
展示阶段:基于实验结果和相关的抓取文献,Carl创建一篇科学手稿,记录实验过程。在构思和实验过程中,Carl所查看的每一篇已发布的科研工作都会被跟踪记录。
仍需人类的参与
虽然Carl的能力使它在很大程度上可以独立工作,但在某些流程环节,仍需要人类的参与,以确保符合计算标准、格式要求和伦理规范。
-
研究步骤的批准:为了避免浪费计算资源,人类审稿人会在Carl的特定研究阶段给出「继续」或「停止」的指令。这些指导帮助Carl更高效地推进项目,但不会影响研究的具体内容。 -
对前API模型的辅助:Carl偶尔依赖于一些没有自动API接入的最新OpenAI和Deep Research模型。在这种情况下,手动介入——比如复制粘贴输出——帮助弥补了这些缺口。Autoscience预计,随着API的普及,这些任务未来将完全自动化。 -
引用和格式化:在现有的引用生成技术中,无法满足学术界对引用频率和严谨性的要求。Anthropic和Google Cloud的LLM引用功能允许模型在回答中引用预先指定的文献,但这些功能更多是为搜索结果设计的,通常无法包含所有相关的文献。为了确保所有参考文献都符合学术规范,目前这一步骤仍然是手动进行的。 -
文本风格:语言模型生成的文本风格往往不符合学术标准。要解决这一问题,预选文献的质量非常重要。其次,Autoscience发现学术写作与编写代码更为相似,而非创意写作。他们将通常用于LLM代码编辑器的技术应用到论文写作中,取得了意想不到的效果,显著提升了生成手稿的质量。
需要指出的是,Carl的方法在整个开发过程中不断演进。在临近研讨会截止日期时,Carl系统发生了许多改进,特别是在展示阶段,这导致了某些提交作品中人类干预程度的差异。
尽管这种快速的进化展示了Carl的快速成长,但它也引入了风险,即Carl的展示阶段可能会过度拟合于它所写论文的特定类型,因为Autoscience在不断根据阶段性结果调整方法。
在生成第三篇高质量论文之后,Autoscience停止了对Carl系统的进一步修改,确保未来的研究工作不再依赖于过度调整。
Carl目前还无法将每个生成的创意转化为高质量的研究。
据Autoscience估计,如果没有经过研究步骤的批准,大约10%的创意是有前景的研究方向——在Carl的计算约束下可行,并且写得足够好,Carl能够正确执行这些想法。
Autoscience还估计,大约7%的经过人工批准的想法能在Carl的第一次尝试中成功实现。
人工批准研究的作用是修剪出可行路径,以便控制成本。虽然这一不断修改的过程存在和初期作品过度拟合的风险,但Autoscience的内部基准显示,这些改进在特定案例之外也具有积极作用。
成果:在质疑中彰显AI科研实力
Carl的两篇论文被ICLR 2025「微型论文」板块录用,这一成绩足以证明AI在科研领域的潜力。
虽然Carl是一个新兴的「研究人员」,但它并不是人类研究员。为避免占用资源,或造成不必要的争议,团队撤回了已被录用的论文。
《面向机器人协调的抗偏差多智能体对齐》共有三份评审意见,一位评审给予「弱通过」,两位给予「弱拒绝」。其中给予「弱通过」的评审人对自己的评估结果最为自信。


从实验设计和评估的角度来看,研究还存在明显的不足。
评审指出了一些问题,如实证评估局限于网格世界,影响了研究结果的普遍性,难以推广到更复杂的实际场景。
另外,还有人指出,论文对研究问题的阐述和讨论不够深入,缺乏计算成本比较以及对碰撞机制的处理说明等。
团队也认识到实验存在的局限性,比如奖励函数设计可能导致的策略问题,但他们认为在合理限制下,该实验仍能有效地展示算法的性能,为后续研究提供有价值的参考。
《何时拒绝:揭示大语言模型对齐的早期线索》是Carl撰写的第一篇论文,在创作过程中接受了大量人工修改。
团队发现了一些重要的文献,没有被Carl引用,于是在此基础上重写了相关内容,并对整篇论文进行了润色。
这篇论文的评审结果同样存在争议,但最终还是被录用了。
研讨会主席认为该论文高于微型论文板块的录用门槛,评审却认为它低于完整论文的录用门槛。

有评审认为,论文缺乏对所提出方法和基线方法的详细描述,与相关方法的比较也不够充分。
评审提出了一系列修改建议,包括补充详细的研究方法、换更多来自近期文献的基线方法、在更多模型上测试,而不仅是Llama 3.1B,以及引用更多文献等。
此外,引用文献的准确性和相关性也受到了质疑。
一位评审指出「这篇论文与Nemani等人的《可解释性与对抗鲁棒性》无关」,但这其实是一种误解。
另一位评审对研究的创新性提出质疑,认为所提出的问题已经被Kirch等人更深入地研究过。
虽然团队并不认为Carl的研究比Kirch等人的研究更深入,但表示所回答的是不同的问题。
全面评估
为确保Carl的研究成果真实可靠、符合学术规范,团队从多个维度对其进行了评估。
在实验可重复性方面,团队采用了三种机制。
首先,创建多个Carl实例,让它们独立地重复研究,然后对各个研究结果进行详细对比。
通过这种方式,可以有效检验Carl在相同条件下能否稳定地得出一致的研究结论,避免偶然因素导致的偏差。
其次,团队将Carl的研究方法提供给MIT等名校的研究人员,邀请他们对实验进行复现或验证。
借助这些高校团队的专业能力和独立视角,进一步增强了实验结果的可信度。
最后,团队会仔细审查Carl编写的所有代码,检查是否存在抄袭、引用不当等问题,并借助抄袭和引用检测工具,确保研究符合学术规范。
在评估实验是否为学界贡献新知识时,团队开发了自动同行评审工具。但由于缺乏人类评审员的细致判断和伦理考量,最终仍需真实的同行评审。
尽管Carl取得了一定成绩,但局限性也十分明显。
Carl擅长实证研究,却无法开展深入的理论研究,面对复杂实验和需要大量计算资源的研究时也力不从心。
数据获取方面,受安全、版权和访问限制,它无法使用Hugging Face未经授权的模型和数据集,也不能开展涉及人类受试者的实验,这大大限制了其研究范围。
在学术界,确定研究想法的新颖性是个难题,Carl也深受其扰。目前缺乏可靠的方法判断其想法是否新颖,这可能导致重复研究,浪费资源。
此外,Carl产出高质量研究成果的成功率有待提高,虽然在人类干预下能通过同行评审,但整体比例较低。
这表明Carl在独立产出高质量研究成果方面,还有很长的路要走。
(文:新智元)