
为法律文件构建 DeepSeek R1 RAG 得到一些重要的教训:
- 利用专门的嵌入模型(如 Qwen2)实现强大的检索;
- 在生成阶段使用 DeepSeek-R1 的推理能力来解决复杂的法律查询;
- 提示工程(PE)仍然是控制引用和构建内容的关键;
- 使用 vLLM 加速推理,从而大幅提高效率和速度。

1. 不要使用 DeepSeek R1 进行检索
尽管DeepSeek R1具有出色的推理能力,但它并不适合生成嵌入 —— 至少现在还不行。
发现了一些例子,表明 DeepSeek R1 生成的嵌入与专门的嵌入模型
Alibaba-NLP/gte-Qwen2-7B-instruct(MTEB排行榜上当前最好的嵌入模型)相比有多糟糕。
使用两个模型为数据集生成嵌入,并组成两个向量数据库。然后,对两个模型使用相同的查询,并在相应模型生成的向量数据库中找到前 5 个最相似的嵌入。

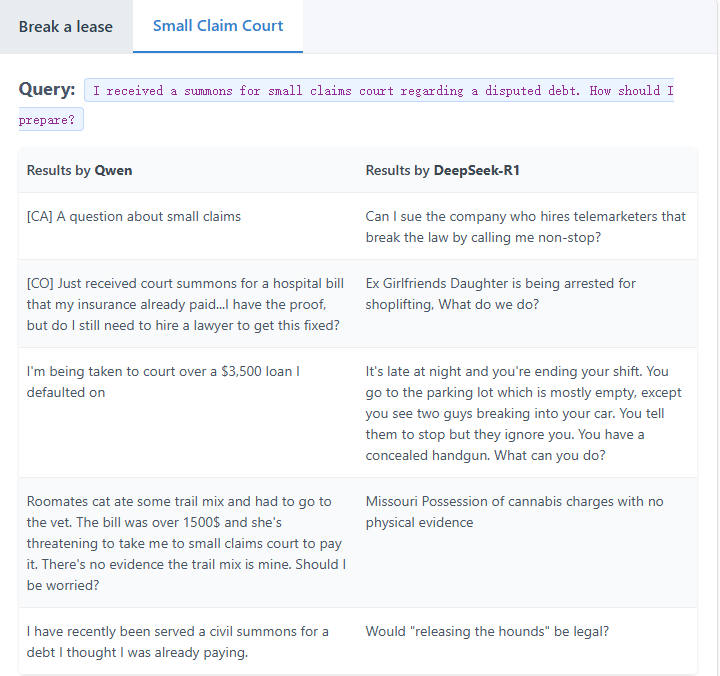
上表中,DeepSeek R1的检索结果明显更差,这是为什么呢?
-
根本问题在于 DeepSeek-R1 的训练方式。DeepSeek-R1 主要被设计为推理引擎,侧重于顺序思维和逻辑连接。这意味着 DeepSeek-R1 不会将文档映射到语义空间中。
-
相比之下,Qwen2 模型变体(
gte-Qwen2-7B-instruct)专门针对语义相似性任务进行训练,创建了一个高维空间,其中概念相似的文档紧密聚集在一起,而不管具体的措辞如何。 -
这种训练过程的差异意味着 Qwen 擅长捕捉查询背后的意图,而 DeepSeek-R1 有时会遵循导致主题相关但实际上不相关的结果的推理路径。
-
除非 DeepSeek-R1 针对嵌入进行了微调,否则不应将其用作 RAG 的检索嵌入模型。
2. 使用 R1 进行生成:理由令人印象深刻
虽然R1在嵌入方面遇到了困难,但发现它的生成能力非常出色。通过利用 R1 的思路链方法,我们看到:
- 更强的连贯性:该模型综合了来自多个文档的见解,清晰地引用相关段落。
- 减少幻觉: R1 在内部“大声思考”,通过数据的视角验证每个结论。
让我们看一些例子:
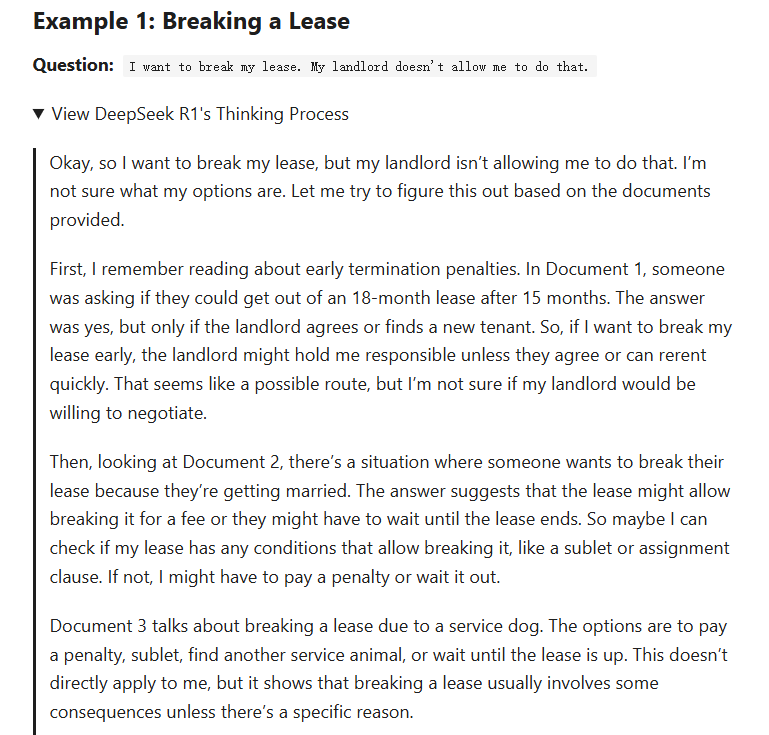


从这些例子中,可以看出DeepSeek R1的推理能力非常出色。它的思维过程清楚地显示了如何从源法律文件中得出结论:
- R1 首先构建法律问题的连贯模型
First, I remember reading about early termination penalties... Document 1 mentions...,这从其详细的思考过程中可以看出:这种推理优先的方法使得模型能够在检索之前有条不紊地连接多个来源的概念。 - 在处理租约终止或小额索赔法庭问题等复杂场景时,观察到 R1 明确地理解了每份文件(
Putting this all together...),而没有产生幻觉。 - 最后,生成器用精确的引文解释其推理过程,将结论与来源联系起来。这建立了从问题到推理再到答案的明确联系,确保了严谨性和可访问性。
用各种法律查询尝试了该模型,并且该模型始终表现出不仅可以从源文档中提取信息,还可以从中学习和推理的能力。
要点:对于问答和总结,R1是循序渐进的法律逻辑的宝藏。将其保留在生成阶段,几乎不会后悔。
-
法律数据集的一个子集(专注于法律建议) -
https://huggingface.co/datasets/pile-of-law/pile-of-law -
ChromaDB作为向量存储,用于存储嵌入、存储和查询 -
用于检索的Qwen2嵌入 -
以及DeepSeek R1用于生成最终答案。
https://github.com/skypilot-org/skypilot/tree/master/llm/rag(文:PaperAgent)