

我发现对于 o1、R1 等推理模型们大家是又爱又恨,
喜欢用的人觉得能从模型的思考过程里自主判断问答正确与否,还可以学到不少原理;
不爱的人觉得提问的时候答案就是明确的,思考过程太慢了,想要多轮对话很费时间。
所以有没有那种速度快,质量好,能一口气丢进去大段长文本的模型呢?
今天它来了,腾讯混元 T1正式上线!
先说两个重要结论:
-
T1 是个六边形选手,在中文能力上超越 DeepSeek R1,复杂推理、代码任务上优于 o1
-
首字符1秒内响应,是 R1 的8倍上下,o1-mini 的2倍左右,还有 60-80 tokens/秒生成速度,平均下来是R1、o1的3-4倍。
在 🔗llm.hunyuan.tencent.com/#/chat/hy-t1 里就可以直接体验。
从视频的实时计时来看,效果更加震憾。但快并不代表质量不好,
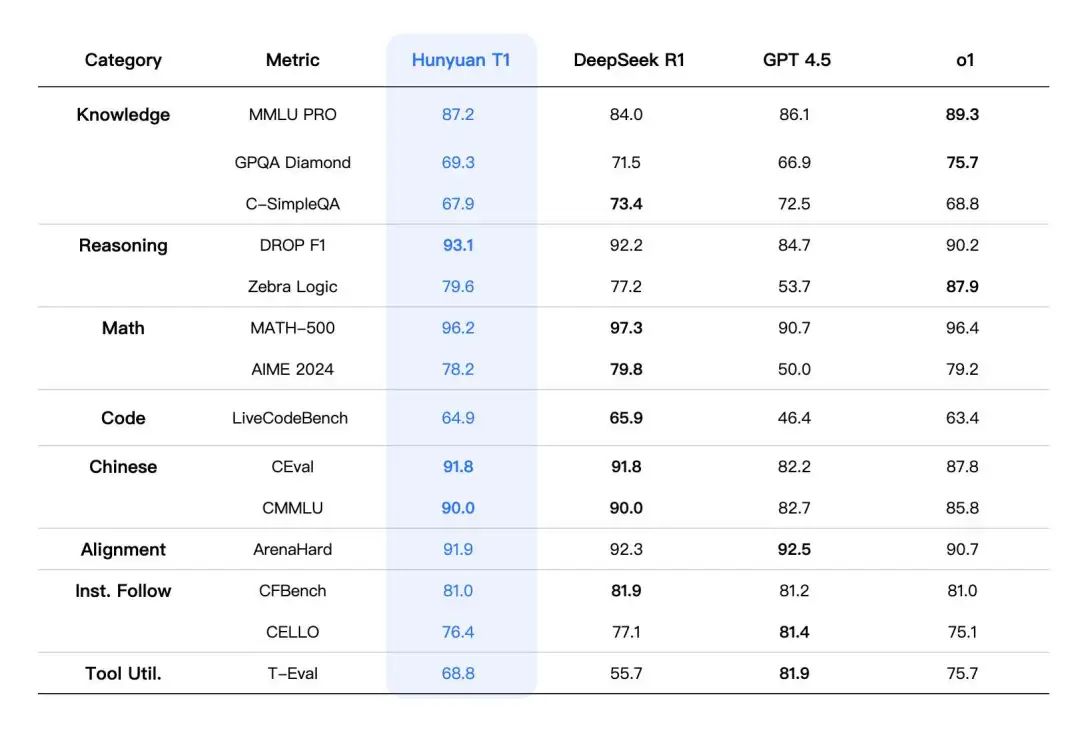
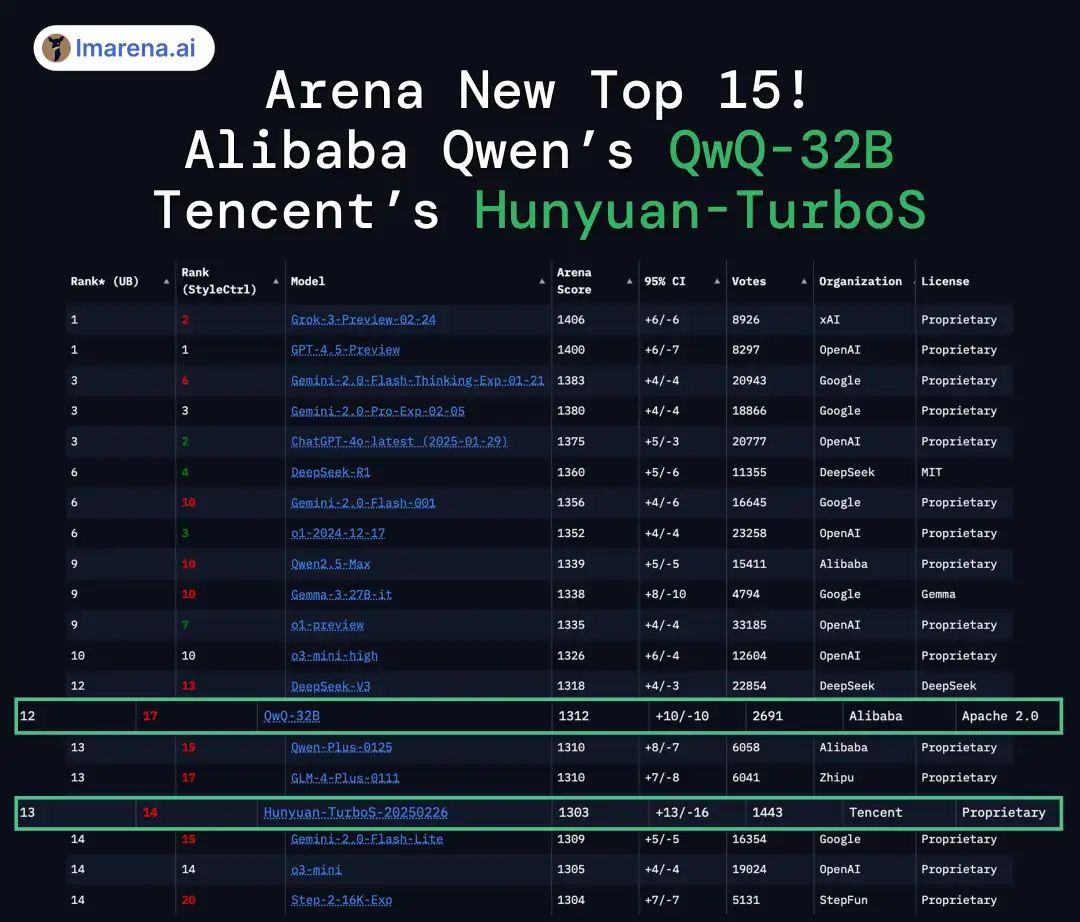
从报告里贴出来的数值来看相当能打,而在大模型竞技场中,混元 T1 的基础模型 Turbo S 已经挺进前15,超了 o3-mini
所以我就计划从我最近用推理模型较多的两个场景来实测T1,联网搜索和将 PDF 一键转成可视化网页。
T1 这次相当友好的是开放了兼容 OpenAI 格式的 API,也就是说那一大堆 API 客户端都能用上了。
登陆 🔗 https://console.cloud.tencent.com/hunyuan/start 里选择创建API KEY就行,参数就按照这个设置:
- API_Key: sk-XXXX
- Base_URL: https://api.hunyuan.cloud.tencent.com/v1
- MODEL_NAME: hunyuan-t1-latest
先看试试看联网搜索,后续 T1 会在元宝上支持联网,我们这次借助 Chatbox 算是超前点播了。

我只提问了昨天OpenAI发布了什么?,从 T1 的思考过程里可以看出它能准确利用时间来筛选网页信息。

跟 R1 对比一下质量,它们都给出了完整的模型列表、API 费用信息和技术升级点。
据可靠小道消息,T1马上就要上线元宝了。元宝也是老朋友了,能整合公众号里文章的信息。之前我也有测评过,元宝并不是按照热度高度来检索文章的,而是信息相关度,也就是说很冷门的文章,只要是对信息有用的都能搜索到。
我现在 AI 搜索工作流就是 Grok3 + 元宝 + Perplexity,覆盖 X、公众号、通用域的所有信息,T1 这波加强之后估计 Perplexity 可以退到二线了。
再来看看 T1 的代码能力:
T1 在写代码的时候同样思考得很快,生成的网页整体风格很素,属于是该有的都有,要是美学设计再提升一点就更好了,
上次将文本转成可视频网页的效果,我测试了很多模型,基本只有 o1 和 Claude3.7 才能稳定复现,R1成功率大概不到80%。
目前,混元 T1 API 输入为每百万 tokens 是1元,输出为每百万tokens是4元。
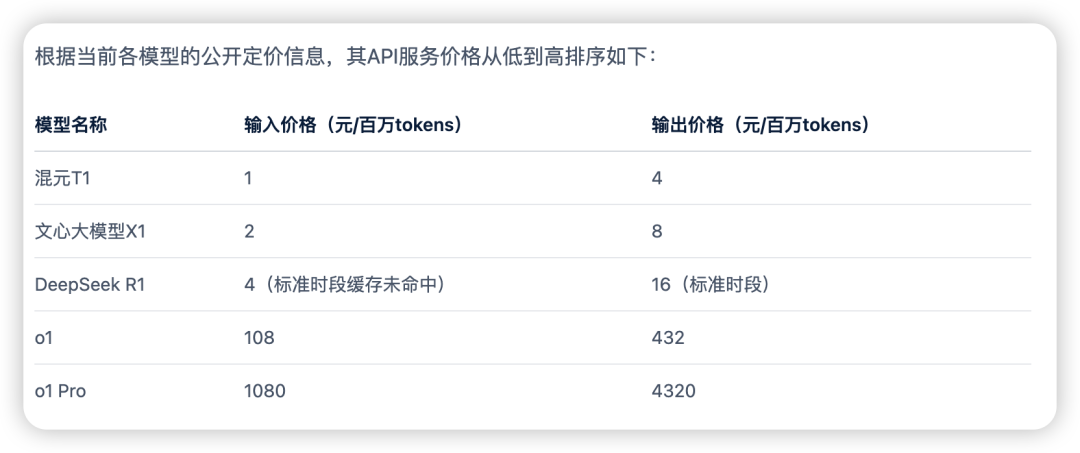
过于良心了,推理模型的价格内卷也是开始了。T1 是 o1 pro 的千分之一、o1 的百分之一、DeepSeek R1 的四分之一,是文心大模型 X1 的二分之一。
所以为什么是推理模型?
如果说之前看过 GPT4.5 的朋友们,夸张点说基础模型性能提升在现阶段已经快到头了,计算量是 GPT4 的10倍,基础测试只比上一代 4o 好了5%,同时段的推理模型 o3-mini 在 AIME2024(数学)测试集里,超出 GPT4.5 快50个点。
万人盲测GPT4.5中文版,价格涨300倍就为了加点人味儿,OpenAI真做到头了
为了提升速度,腾讯做了什么?
混元T1 采用Hybrid-Mamba-Transformer融合模式,是首次将混合 Mamba 架构无损应用于超大型推理模型。
GPT 系列就是 Transformer 结构,但是处理长文本的时候,计算和内存需求会二次增长,而 Mamba 架构适合处理长序列数据,生成阶段的内存和计算需求保持恒定,从而支持更长的上下文。
T1 让我看到了更多的可能性,
@ 作者 / 卡尔 & 阿汤 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)