
今天是2025年3月23日,星期日,北京,天气晴。
我们今天继续回到R1在后续模型训练上的一些尝试。之前说过很多R1用在多模态领域的工作,核心就是把多模态的数据进行文本化,然后蒸馏R1的推理路径做微调,或者在强化阶段引入一些个非文本模态的奖励,如IOU奖励。
这次来说说用在垂直领域。现在这块的趋势,像极了23年清一色的领域微调模型一样,当时的路线是继续预训练(continue pretain)+微调(SFT),或者直接微调(SFT),这里的SFT大多是构造问题,然后蒸馏GTP4等强模型的答案,构成二元组数据(question, answer)。
R1出来之后,模式就变成了SFT(监督微调)、RL(强化学习)或两者的组合。但是这里的微调(SFT)使用的答案,从之前的答案,变成了加入思考轨迹的三元组,即(question, think, answer),被蒸馏对象变成了DeepseekR1或者GPT4-O1等。然后强化学习变成了GROP(大多都是准确性奖励和格式正确奖励两种)。
这种范式下,也逐步会出现一些行业R1模型的实践工作,换个数据集把流程走一遍,产出一些实验报告,这也是最近多模态R1以及一些声称做了一些行业R1工作的底裤。
本文来讲讲最近的一个具体工作。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、再看行业R1模型构建路线,以Fin-R1为例
行业R1如何做,蒸馏行业R1推理数据微+GRPO下。
因此,就有了一些工作,例如用在金融行业。《Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning》,https://arxiv.org/pdf/2503.16252,结论没有实用意义,金融计算问题,正是大模型短板,且用7B,也没有实际说服力,测试任务也很简单,就是上述方式用金融领域的数据套着做了一遍,但也可以作为再加深下印象来看。
工作的Github地址崽,https://github.com/SUFE-AIFLM-Lab/Fin-R1,模型地址在https://huggingface.co/SUFE-AIFLM-Lab/Fin-R1。
核心看2点,三张图。
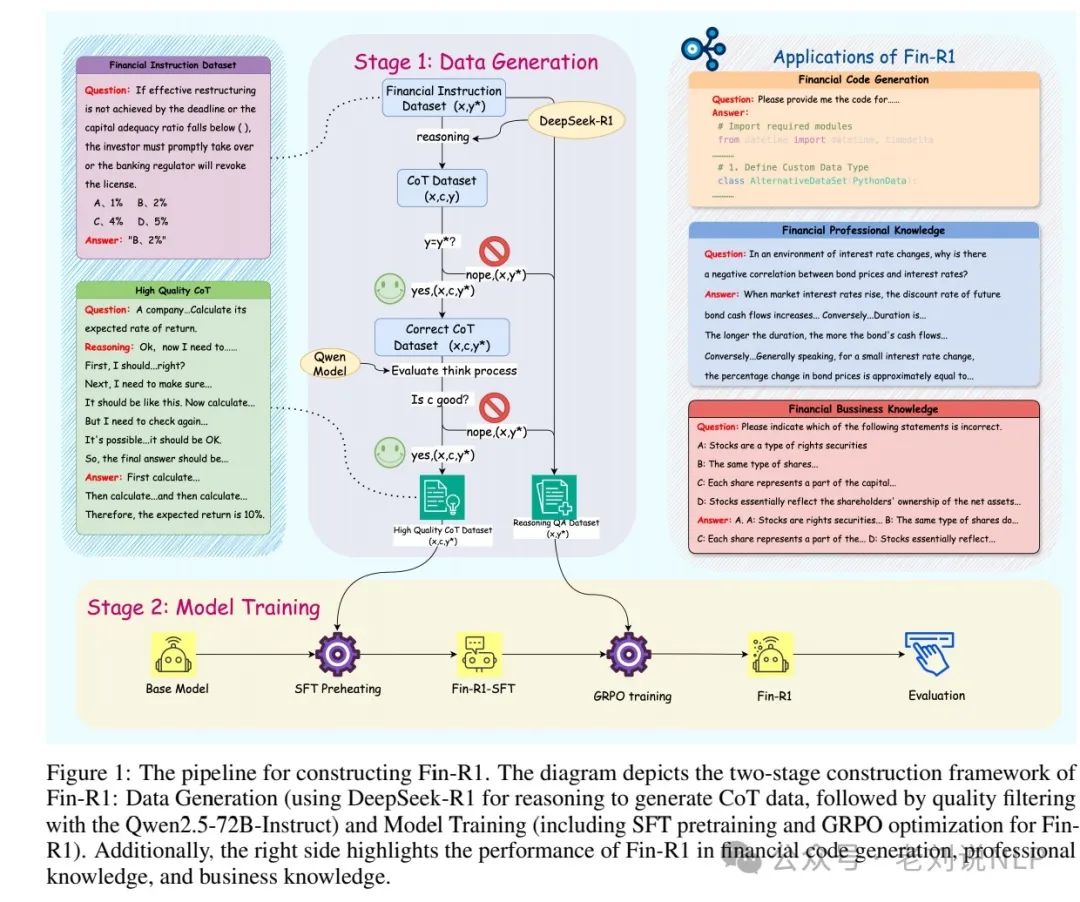
一个是数据怎么做?
数据集包括60,091条条目,涵盖中英双语的金融内容。数据集分为开源数据集和专有数据集。开源数据集包括Ant_Finance、FinanceIQ、Quant-Trading-Instruct等,专有数据集为金融研究生入学考试题(FinPEE)。
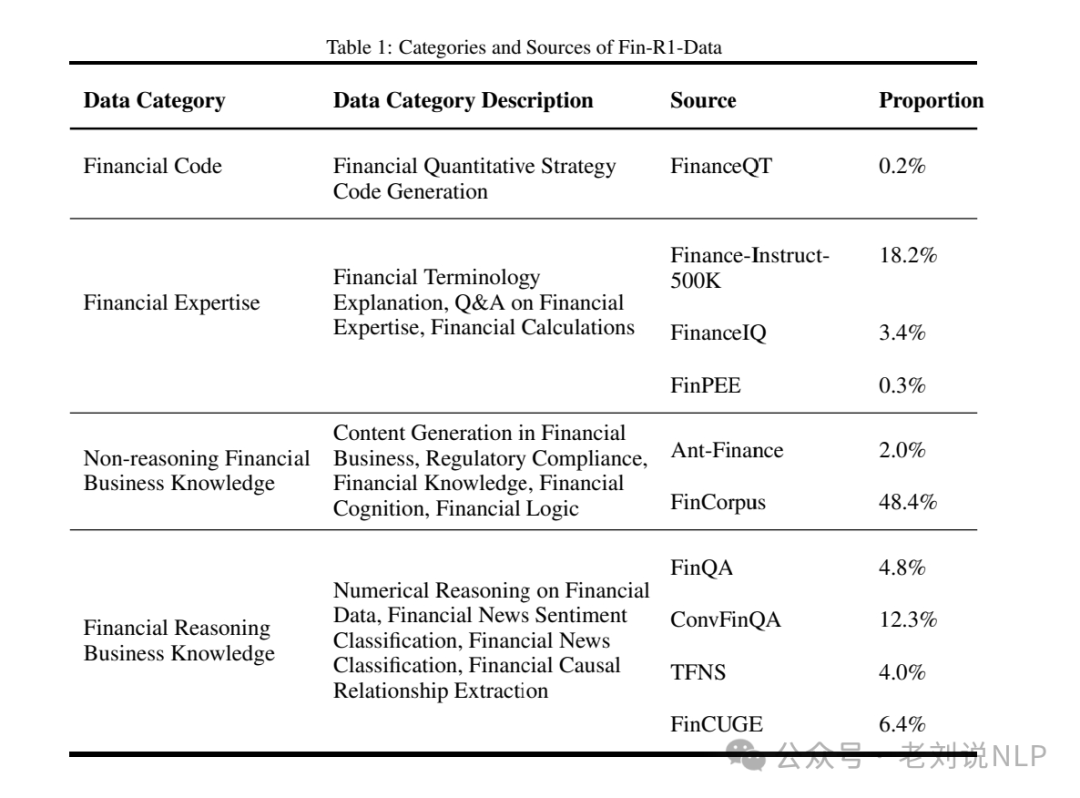
数据处理包括数据蒸馏和数据过滤。在蒸馏阶段,参数配置与官方DeepSeek-R1规范对齐,温度设置为0.6,数学数据使用标准化提示以确保答案格式一致。在过滤阶段,采用Qwen2.5-72B-Instruct作为判断模型,通过七维评估标准(内部一致性、术语重叠率、推理步骤数、逻辑连贯性、内容多样性、任务域相关性和与任务指令的对齐)筛选高质量的推理轨迹。
一个是具体怎么做的训练?

两个阶段,监督微调(SFT)阶段,使用Fin-R1-Data对Qwen2.5-7B-Instruct进行微调,SFT训练数据由ConvFinQA和FinQA数据集组成,每个样本包含问题、推理轨迹和答案。强化学习(RL)阶段,采用组相对策略优化(GRPO)算法,双重奖励机制包括格式奖励和准确性奖励。
二、减少推理大模型过度思考的技术方案总结
关于推理模型过度思考的工作,我们也讲过许多了,其虽然提高了性能,但也带来了显著的计算开销,导致“过度思考”现象,具象化理解起来就是,LLMs生成过于详细或不必要的推理步骤,从而降低了解决问题的效率,这种现象在参数规模较小的模型中尤为明显。

如下,“过度思考现象”的一个例子:当推理模型被问及“0.9和0.11,哪个更大?”时,QwQ-32B 花费了19秒,DeepSeek-R1花费了42秒才给出最终答案。
可以继续温习一下,来看一个技术总结,《Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models》,https://arxiv.org/pdf/2503.16419,https://github.com/Eclipsess/Awesome-Efficient-Reasoning-LLMs,收集了一些代表性的工作。
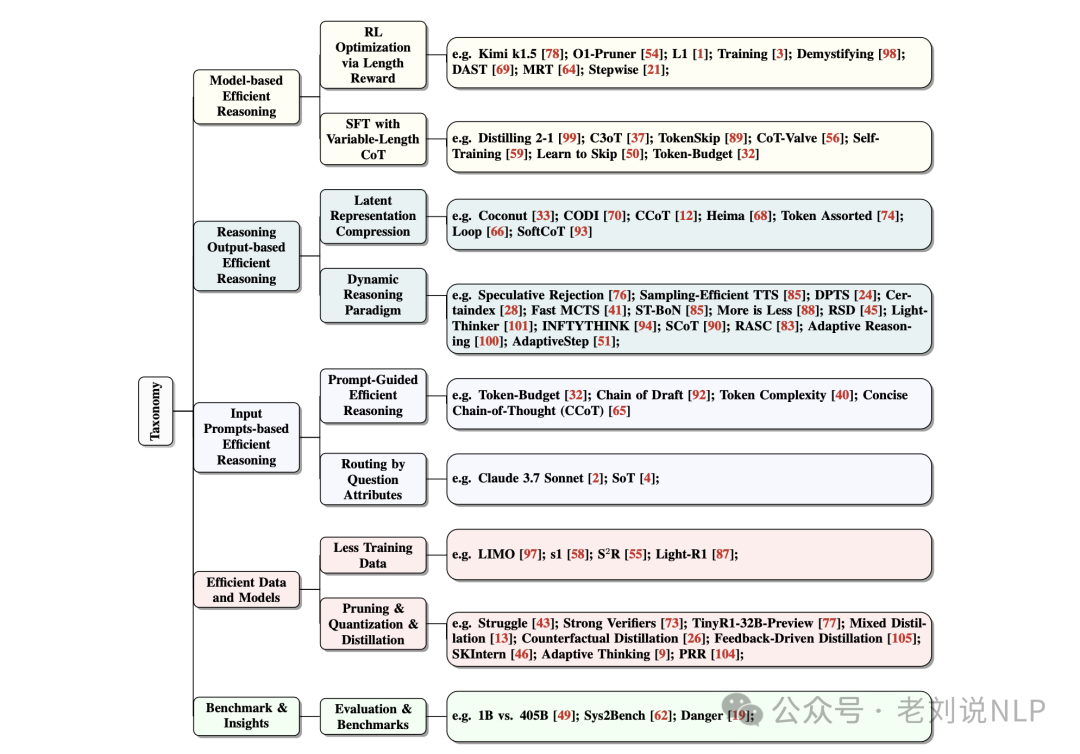
核心就三个方向:基于模型的高效推理,考虑优化全长推理模型为更简洁的推理模型或直接训练高效推理模型;基于推理输出的高效推理,旨在推理过程中动态减少推理步骤和长度;基于输入提示的高效推理,寻求根据输入提示属性如难度或长度控制来提升推理效率。 具体看怎么做?
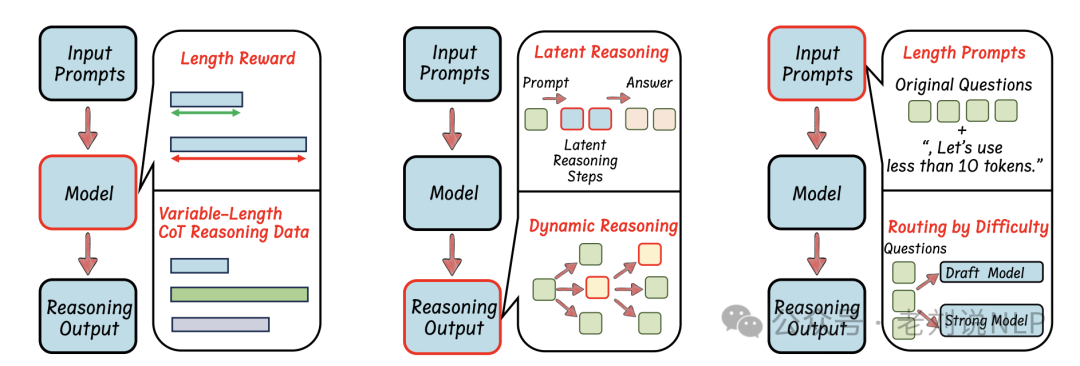
对于基于模型的高效推理model-based,2个角度:
一个是RL与长度奖励设计,通过在强化学习框架中引入长度奖励来缩短推理过程。具体方法包括使用PPO算法和Cosine Reward等。
一个是SFT与可变长度CoT数据,通过使用可变长度的CoT数据集来优化推理效率。方法包括自训练、TokenSkip、C3oT等。
对于基于推理输出的高效推理reasoning output-based,2个角度:
一个是压缩推理步骤到更少的潜在表示,通过将推理步骤压缩为更少的潜在表示来提高效率。方法包括Coconut、CODI、CCOT等。
一个是动态推理, 在推理过程中选择适当的准则来指导推理策略。方法包括基于奖励的推理、基于置信度的自适应推理、基于一致性的选择性推理等。
对于**基于输入提示的高效推理 input prompts-based **,两个角度:
一个是提示引导的高效推理,通过明确的提示指令来控制推理长度。方法包括设置token预算、使用简洁的提示等。
一个是提示推理路由,根据输入提示的复杂性动态确定语言模型处理查询的方式。方法包括使用分类器训练查询路由器、基于不确定性的自我路由等。
这个工作也谈到了几个有趣的话题,包括:如何将推理步骤压缩到潜在空间?在推理过程中应该使用哪种标准来指导推理策略?如何准确地控制LLMs的推理长度?如何构建少但高质量的训练数据?小模型在推理任务中的表现如何?模型压缩(如量化)对其推理能力有何影响?
感兴趣的可以进一步读一读。
参考文献
1、https://arxiv.org/pdf/2503.16252
2、https://arxiv.org/pdf/2503.16419
(文:老刘说NLP)