


今天给大家带来一篇重磅研究解读,来自新加坡国立大学 和SeaAILab团队 Zichen Liu 博士的最新工作,直击 R1-Zero-Like 训练的核心痛点,信息量爆炸!

这篇论文题目就非常硬核:《Understanding R1-Zero-Like Training: A Critical Perspective》(理解类 R1-Zero 训练:批判性视角)。 他们没有盲目跟风,而是选择了 “先理解,再改进” 的硬核路线,深入剖析了 R1-Zero 这类训练方法的两大基石: 基座模型 和 强化学习 (RL)
重磅发现一:基座模型才是真大佬?“顿悟时刻” 比你想的早!
文章一上来就抛出震撼弹: DeepSeek-V3-Base 竟然在 RL 微调之前就展现出了 “Aha moment”(顿悟时刻)!这直接颠覆了我们之前的认知,难道 RL 只是锦上添花?

更让人惊讶的是,他们发现Qwen2.5 基座模型,这个 R1-Zero-like 训练的 “网红选手”, 即使不用 Prompt 模板,推理能力也强到离谱!平均 benchmark 分数直接飙升 ~60%! 这简直不像基座模型,更像是用 QA 数据集 SFT 过的模型!🤔
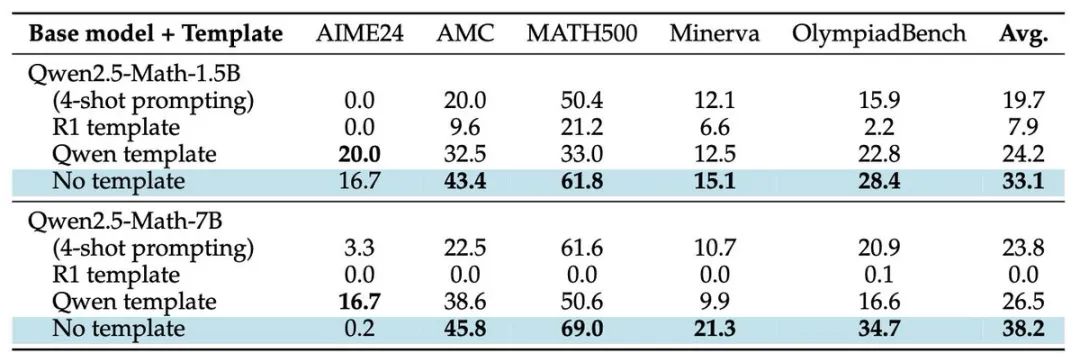
这些现象都在暗示一个扎心的真相: 基座模型的预训练阶段可能已经注入了太多 “偏见”。 比如,自我反思能力、数学解题技巧,可能在 RL 奖励信号强化之前就早已埋下种子。
🤔 等等,那模型回复越来越长,真的是 RL 的功劳吗? 这里面可能另有隐情…
重磅发现二: RL 环节暗藏 “长度偏见”? GRPO 原来没那么完美!
研究团队深入扒了 RL 环节,尤其是 GRPO (Generalized Reward Policy Optimization) 算法,结果发现… GRPO 竟然是有偏见的!

具体来说,GRPO 的 长度归一化 (length normalization) 会偏爱短的正确答案,却对 长的错误答案更宽容! 这就导致了 “长度偏见” (length bias)。
更可怕的是,GRPO 的标准差归一化 (std normalization)还会偏爱太简单或太难的问题,而忽略难度适中的题目! 这又带来了“难度偏见”** (difficulty bias)
🤯 PPO 也躺枪? 开源实现竟然也引入了 “长度偏见”!
更让人意想不到的是,即使理论上 PPO (Proximal Policy Optimization) 算法是无偏的,但几乎所有开源实现都通过计算 masked_mean 引入了 “长度偏见”! 这简直防不胜防!

划重点: “长度偏见” 可能就是模型回复越来越长的幕后黑手之一!
🔥 利器: Dr. GRPO 横空出世!两行代码解决 “偏见” 问题!
为了解决 GRPO 的 “偏见” 问题,研究团队祭出大招 —— Dr. GRPO (Doctor GRPO)! 只需 两行代码 的魔改: 移除长度归一化和标准差归一化 (图中红色部分)!
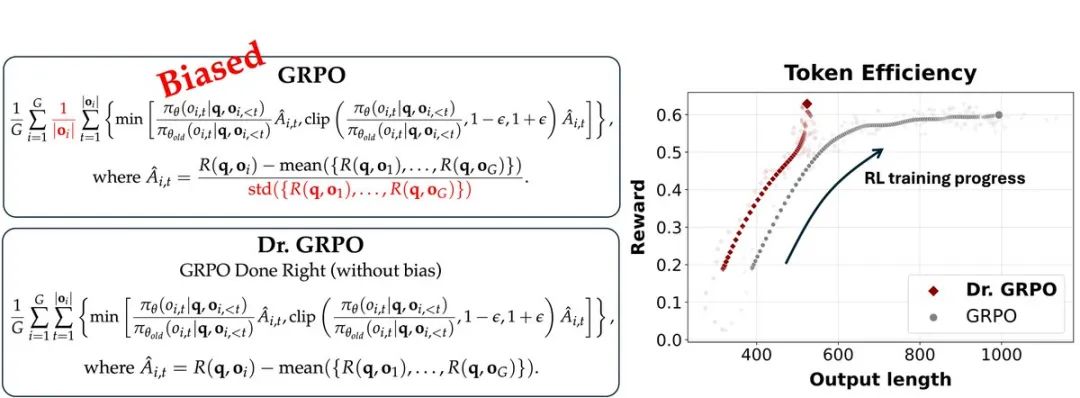
Dr. GRPO 不仅无偏,还能提升 Token 效率!因为它能有效阻止 GRPO 产生越来越长的错误答案,避免浪费计算资源。
R1-Zero 训练极简配方大公开! 7B 模型 AIME 怒刷 SOTA!
基于以上分析,研究团队给出了一个极简的 R1-Zero 训练配方,没有花里胡哨的技巧:
-
• 算法: Dr. GRPO (无偏优化器) -
• 数据: MATH level 3-5 难度问题 -
• 模板: Qwen-Math -
• 算力: 27 小时 * 8 * A100
结果震撼: 7B 模型在 Zero-RL setting 下,AIME 2024 怒刷 43.3 分 SOTA!
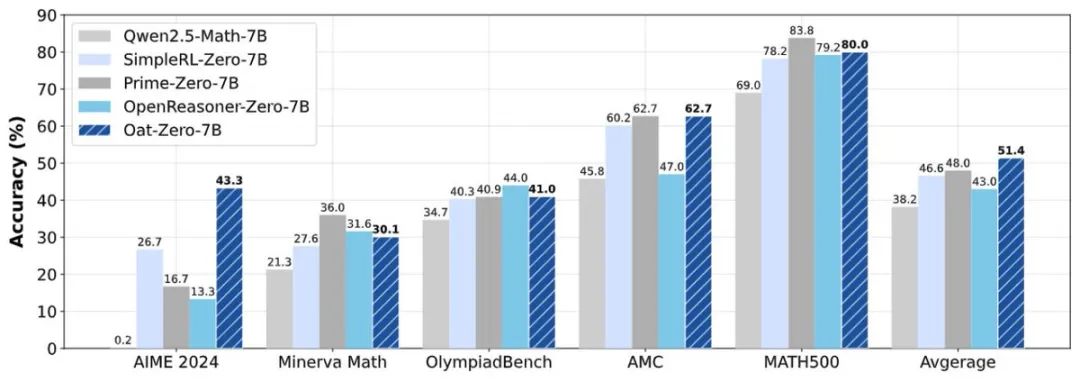
这还不是全部! 这篇论文和代码库里还有更多有趣发现,例如:
a.基础代数 (+ − × ÷) 问题上的 RL 训练,竟然能提升奥赛级别的推理能力!
b.Llama 模型也能 “顿悟”!
强烈建议大家去围观论文和代码👇
论文地址:
https://github.com/sail-sg/understand-r1-zero/blob/main/understand-r1-zero.pdf
代码地址:
https://github.com/sail-sg/understand-r1-zero
总结一下: 这项研究不仅揭示了 R1-Zero-like 训练的深层机制,更指出了现有方法的潜在问题,并提出了有效的改进方案。 对于想要深入理解和实践 R1-Zero 训练的朋友们来说,绝对是不可多得的宝藏资料! 赶紧学起来吧!
作者信息: Zichen Liu, PhD student, RL believer @SeaAIL @NUSingapore
⭐
(文:AI寒武纪)